プロファイリングについて、3回に分けてご紹介する「プロファイリング入門」。今回は第2回目です!
第1回目「プロファイリングとは何か?」はこちらからご覧ください。
- 第1部: プロファイリングとは何か?
- 第2部:なぜプロファイリングを使うのか?(当記事)
- 第3部:プロファイリングツールとその使い方(近日公開予定)
アプリ開発の成功には、素晴らしいパフォーマンスが重要であることはご存じかと思います。
パフォーマンスを改善するためのツールはたくさんあります。
最新のプロファイリングツールを使ってプロファイリングを行うことは、アプリのパフォーマンスを理解するために最も簡単で効果的な方法の一つといえます。
プロファイリングツールは、1970年代から開発者が遅いコードを修正するのに役立ってきました。
最近のプロファイリングツールは、より洗練され、より使いやすくなっています。そして、サービス終了までのあいだ継続的に稼働させることができます。
例えば、遅いコードの経路を示す有用な可視化データを自動的に作成する機能があります。また、他のパフォーマンスツールとの統合や連携も可能です。
シリーズの第1回目と同様に、この記事のほとんどの例は、フロントエンドとバックエンドの開発に関するものです。
しかし実際には、プロファイリングツールはほとんどのコードに適応し、パフォーマンス向上に役立てることができます。
なぜプロダクションでプロファイルするのか?
PythonのcProfileやGoのpprofのように、多くの言語にはプロファイリングツールが組み込まれています。
これらのツールはとても便利で、何十年も前から使われています。
しかし、使い続けていると次第に使いにくい場面も出てくるのは事実です。そんな時は、追加の可視化ツールを必要とします。
これらのツールは、あなたのローカル環境上で動作することだけを想定しています。
ローカルプロファイリングは限定的
内蔵のプロファイラを使えば、コードの特定の部分について詳細なベンチマークを取得することができます。それにより課題のある箇所を見つけるのに役立ちます。
しかし、大規模なシステムでパフォーマンスの問題を発見するためには、最適の策ではありません。
ローカルプロファイラを使用すると、多くのオーバーヘッドがコードに追加されます。(一般的には200%以上追加されます)
プロファイリングを使うということは、コードの性能を気にしているはずです。
それにも関わらず、コードを2倍以上遅くしているのは矛盾します。
そして、すべてのプロファイラで、追加されるパフォーマンスオーバーヘッドの量は、関数呼び出しの間で一定ではありません。
つまり、プロファイリングで得られるCPU処理時間は、正確ではない結果となります。これでは正確に解析できないため、プロファイリングを実行する意味がありません。
一般的に、ローカルでのプロファイリングだけでは、ユーザー体験を明確に把握することはできません。
本番環境での速度低下の原因を、ローカル環境で再現するのは非常に困難であるためです。
ご存知のように、開発マシンでのパフォーマンスは、コードが本番稼働しているときと常に同じとは限りません。
したがって、開発環境のローカルプロファイリングで問題を発見し、実際に修正するのは非常に困難であるということがわかります。
プロダクションにおける最新のプロファイリング
最終的には、本番環境でパフォーマンスを測定することが、システムのパフォーマンスを正確に把握する唯一の方法となります。
幸いなことに、ローカルのプロファイリングツールが作られて以来、プロファイリング技術は大きく進化してきました。
最新のサンプリングプロファイラは、現在、本番環境で実行できるほど進化しています。(決定論的プロファイラとサンプリングプロファイラの比較は第1回目で詳しく説明しています)
それは、パフォーマンスのオーバーヘッドを抑えて実行できるようになったためです。
また、コードのパフォーマンスの詳細な情報を可視化して提供してくれます。
それはローカル環境上のプロファイリングと遜色ない、有用で十分な解析結果を出力してくれます。
例えば、Sentryのプロファイリングツールは、10%以下のオーバーヘッドを目標として実行しています。
さらに、最新のプロファイリングツールは、すべてのユーザーセッションのデータを取得するように設計されています。
つまり、コードが本番環境でどのように動作しているかを包括的に把握することができるのです。
プロファイリングは<metrics/logging/tracing>と比較してどうなのでしょうか?
他のツールを使って、本番環境からパフォーマンスデータを取得している方もいらっしゃると思います。
『なぜプロファイリングをセットアップする必要があるのか』という疑問もあるでしょう。パフォーマンスを監視する方法を変更するのは、決して簡単な作業ではありません。
しかし幸いなことに、プロファイリングはパフォーマンスを測定するための他の戦略とともに機能します。
また、設定もそれほど難しくなく、得られるメリットも大きいです。
最も大きなメリットは、プロファイリングデータが関数またはコードレベルの粒度を提供することです。これにより、開発者はパフォーマンスの問題を発見し、修正することが非常に簡単になります。
システムメトリクス
ページロード時間、CPU使用率など、その他の事前設定されたメトリクスは、本番環境で稼働しているアプリのパフォーマンスを把握するために使用されます。
また、効果的でオーバーヘッドの少ない方法を提供し続けます。
メトリクスは、パフォーマンスの問題があることを知らせるには最適ですが、その原因まで突き止めることはできません。
メトリクスは非常に低いオーバーヘッドで動作するので、使わない理由はありません。しかし、最近のツールと比較すると、その有用性は限定的となります。
ロギング
ロギングは、パフォーマンスを含め、さまざまな方法でシステムの健全性を把握するのに便利です。
しかし、ロギングからパフォーマンスデータを取得するには、多くの手間がかかります。
情報が欲しい全ての箇所に、イベントを手作業で追加する必要があるためです。
ロギングシステムをどのようにセットアップしたかによりますが、ログ収集も高額になる可能性があります。
分散したシステムでログを追跡し分析することは困難です。
パフォーマンス問題の根本的な原因であるコードを把握するために、ログを分析するのは困難で時間がかかります。
トレース
プロファイリングが分散トレーシングとどう違うかについては、第1部をご確認ください。
分散トレーシングを使ってアプリのパフォーマンスを監視する場合、Zipkin、Jaeger、Grafana Tempoなどが多く使われています。
あるいはSentryのようなものを使うと、本当に便利です(小声)。
トレーシングは、サービスや外部呼び出しのどこで処理時間が費やされているのかを示すのに最適です。
しかし、収集できる情報は、手動でインスツルメンテーションした間隔と同じ粒度でしかありません。
プロファイリングは、トレースと連携して、コードの問題箇所がどこにあるか、ファイルや行のレベルで詳しく説明することができます。
ここからは、プロファイリングとトレーシングを併用することのメリットをいくつかご紹介します。
プロファイリングのメリット
システム開発の現場でパフォーマンスの問題が発生した際、ツールでコードのどこに問題があるのかを正確に示してもらい、それを修正できるようにしたいものです。
そこで登場するのがプロファイリングです。
最近のCPUプロファイラでは、コールスタックを1秒間に何度もサンプリングしてプロファイラを収集します。
これにより、各関数の実行にかかる時間が把握できます。
コードのどこが、どのくらい遅いのか。極めて詳細なデータを得ることができるのです。
そして、プロファイラーが本番環境で常に稼働しているため、自動的に速度低下に関するデータを得ることができるのです。
プロファイラから戻ってくるデータによって、コールスタックを掘り下げてホットスポットを見つけることができます。
コードに多くの時間を費やしている場所の詳細(行番号まで見ることができます)が表示されます。
多くの場合、このデータは「フレーム・チャート」や「フレーム・グラフ」で出力されます。以下の画像は、SentryのPythonプロファイラによるフレームチャートの一例です。関数にカーソルを合わせると、実行中のコールスタック、各関数の実行時間、行番号を確認することができます。
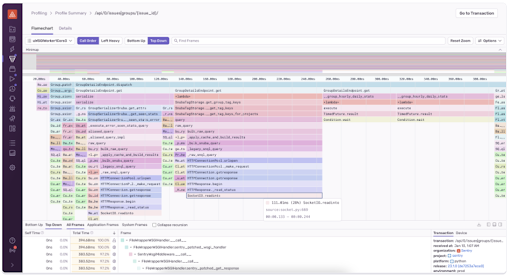
プロファイリングとトレーシングの併用
Sentryでは、プロファイリングとトレーシングは、とても相性が良いと考えています。トレーシングでは、システムのパフォーマンスをハイレベルで見ることができます。プロファイリングは、その細部を埋めるものです。これにより、正確なコード行番号まで掘り下げることができます。これにより、速度低下の根本的な原因をより迅速に見つけることができます。
Sentryのツールを使えば、自動トレースを多くのフレームワークでサポートします。つまり、数行のコードを追加するだけで、トレースを開始でき、これまで必要だった多くの手間を必要としないのです。
プロファイリングも有効にすると、Sentryのトランザクションベースのプロファイラが自動的にプロファイルを収集し、プロファイルとトランザクションをリンクします。
これにより、パフォーマンスデータを探索し、理解するためのわかりやすいモデルが提供されます。
より高いレベルのトランザクションビューから、プロファイルの機能レベルの詳細まで、簡単に移動することができます。1つのビューで両方を確認することができます。
トレースとプロファイリングを一緒に使用する簡単な例を見てみましょう。
SentryのAPIの一つ(実は、Sentryを監視するためにSentryを使っているんです)を例にして、CPUに負荷のかかるワークロードを探ってみます。
ここに私たちの/コンシューマーエンドポイントからのトランザクションがあります。
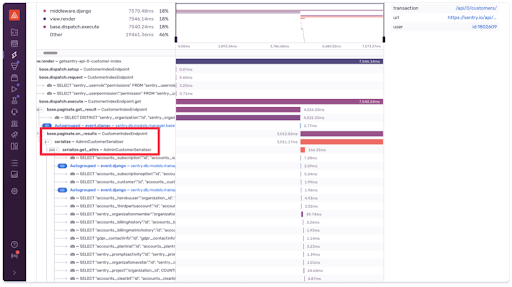
トランザクションデータから、CustomerIndexEndpointページでデジタルコンテンツを分離する場合、AdminCustomerSerializerにかなりの時間が費やされていることがわかりますね。
この時間に関与している生のSQLクエリを以下で見ることができます。
しかし、これらのクエリがコードのどこで実行されているのかを理解することは困難です。
プロファイルデータの中身を見てみると、以下のように表示されます。
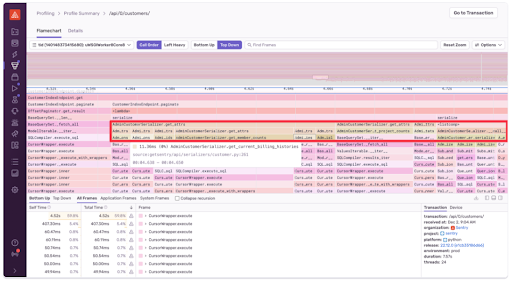
ここから、AdminCustomerSerializer.get_member_counts やAdminCustomerSerializer.get_current_billing_histories などの関数を簡単に特定することができます。
これらは、SQLクエリーが実行されるコード内の場所です(関数コール・スタックのさらに下、CursorWrapper.executeまで読むと分かると思います)。
ここから、フレームをクリックしてGitHubで開くと、コードに直接誘導することができます。
解析→問題箇所の発見→(修正するために)問題箇所へのリンク…という一連の導線が構築されているため、簡単に利用できます。
結論
プロファイラとは、コードのホットスポット(処理が重い、遅い箇所)を特定するための非常に便利なツールです。
ローカルで動作するプロファイラも、本番環境で動作するプロファイラも、どちらも有用です。しかし、長期間稼働する最新のプロファイラを本番環境で使用することが、最も簡単な方法です。
- ユーザー体験を正確に把握する
- パフォーマンスの問題を解決するために、実用的で正確な情報を得る
Sentryのプロファイリングを試す準備はできていますか?
Sentryは、PythonとNode(ベータ版)、AndroidとiOS(ベータ版)用のトランザクションベースのプロファイラを備えています。
これを使えば、CPU使用率の急上昇やレイテンシーの問題を引き起こしているコードの正確な行を見つけることができます。
「まずはもっと知りたい」という方は、プロファイリング入門101:プロファイリングとは何か?をぜひご覧ください。
また、感想や質問を [email protected] に書き込んだり、私たちのDiscordに参加して#profilingチャンネルに参加することもできます。
お気軽にご意見や感想、質問などをお送りください!
Sentryは、アプリケーションコードの健全性を監視するために不可欠です。
エラートラッキングからパフォーマンスモニタリングまで、フロントエンドからバックエンドまで……アプリケーションをより明確に把握し、より迅速に解決し、継続的に学習することができます。
Sentryは、世界中の350万人以上の開発者と85,000以上の組織に愛され、Disney、Peloton、Cloudflare、Eventbrite、Slack、Supercell、Rockstar Gamesといった世界で最も有名な企業の多くにコードレベルの観測機能を提供しています。
毎月、世界中で人気のあるサービスから、数十億の例外を処理し続けています。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。