
Article by: Will McMullen
遅いデータベースクエリは、開発者にもユーザーにも悪影響を及ぼします。
リソースを浪費し、テストの遅延を引き起こし、動作が重くなることによってユーザーは不満を抱きます。しかし、多くの場合、驚くほど意外な解決策があります。それがインデックスです。
ここでは、インデックスの仕組みと、その活用タイミングについて解説します。
スキーマの種類を問わず役立つ内容です。
すでにインデックスの基本と使い方を理解していて、遅いクエリの監視やデバッグ方法を知りたい場合は実践例をご覧ください。
インデックスとは?
インデックスとは何かご存じですか?
簡単にいえば、データベースの「GPS」のようなものです。
インデックスがないと、データベースは全ての行(レコード)を1つずつチェックしながら探し回らなければなりません。そうするとまるで迷子の観光客のように、目的地へ辿り着くまでに時間がかかってしまいます。
しかし、インデックスがあれば無駄な回り道をすることなく、一直線でユーザーの目的地(ここでいう処理)へ辿り着くことができます。
インデックスを技術的に解説すると、カラムの値を行にマッピングする小さなデータ構造のことを指しており、検索を高速化する役割を果たしています。
例を見てみましょう。
ユーザーテーブルやコレクションからメールアドレスを検索する場合、SQLデータベースではメールカラムに対するインデックスを次のように作成できます。

MongoDBやその他のNoSQLのドキュメント型データベースも、同様の方法でインデックスを活用します。例えば以下のコードのように、MongoDBではusersコレクションのemailフィールドを検索する際にインデックスを利用できます。

インデックスは決して魔法のように万能ではありません。アルゴリズムの観点では、まるで魔法のように感じられることがあります(バイナリ検索木やハッシュマップを思い浮かべてください)。
クエリがインデックス付きのフィールドを含む場合、データベースはテーブル内全ての探索を回避し、インデックスを使って効率的にデータを探します。これにより、クエリ速度が大幅に改善するのです。
インデックスは万能ではないことを理解し、適切に使わなければ逆効果になることもあります。
以下がその例の一部です。
・書き込みの遅延
データを追加・更新するたびにインデックスも更新されるため、書き込み処理が遅くなる
・ストレージの増加
インデックスを保持するための追加のストレージが必要
・パフォーマンスの低下
インデックスを増やしすぎると、データベースの最適化ツールが適切なインデックスを選びにくくなり、かえって処理が遅くなる
それでは次に、インデックスを適用すべきケースを具体的に見ていきましょう。
SQLとNoSQLにおけるインデックスの使いどき
すべてのカラムやフィールドに、インデックスを付ければよいわけではありません。
データベースへの負荷を抑えながら最適なパフォーマンスを得るには、インデックスの効果が最も大きい箇所に焦点を当てることが重要です。
どこにインデックスを適用すべきか、この後の内容を踏まえて検討してみましょう。
SQLで一般的なインデックス
- 主キー(Primary Key)
各テーブルには、一意の識別子となる主キー(例:id)があります。ほとんどのデータベースでは、主キーに対して自動的にインデックスが作成されるため、最も高速にデータを検索できます。 - 外部キー(Foreign Key)
テーブル同士を関連付けるキー(例:注文テーブルと顧客テーブルを結びつける customer_id など)のことです。
これらのフィールドにインデックスを設定すると、JOIN処理のパフォーマンスが大幅に向上します。 - フィルター付きカラム
WHERE・ORDER BY・GROUP BY などのフィルター条件に頻繁に使うカラムは、インデックスを設定することで検索速度を向上できます。例えば、次のSQLクエリをご覧ください。SELECT * FROM products WHERE category = ‘Electronics’;
この場合、category カラムに対してインデックスを作成すると、検索処理が大幅に高速化されます。
MongoDBで一般的なインデックス
- 頻繁にクエリされるフィールド
find({ status: “active” })のようなフィルターを多用するフィールドにインデックスを付けることで、MongoDBは一致するドキュメントを迅速に検索できます。 - ネストされたフィールド
MongoDBでは、データがしばしばネストされたオブジェクトとして保存されます。頻繁にクエリするこれらのフィールド(例:”customer.name”)にインデックスを付けると、検索が高速化されます。 - 複合フィールド
SQLの複合インデックスと同様に、複数の条件を含むインデックスは、組み合わせたキー値を保存し、MongoDBの一般的なクエリを最適化します。例えば、db.orders.createIndex({ customerId: 1, orderDate: -1 }) のようにクエリを作成することができます。
ヒント
インデックスの作成は強力な最適化手法ですが、すべてのフィールドに適用すべきではありません。次のようなケースでは、インデックスを避けるべきです。
- 選択性が低いフィールド
例:status のように active/inactive しかないフィールド - あまりクエリされないフィールド
- 頻繁に更新されるデータ
例:書き込み負荷の高いテーブルの last_seen タイムスタンプ
アプリケーション内でインデックスを付けるべきクエリの見つけ方と修正方法
1: パフォーマンスモニタリングから始める
クエリの詳細に入る前に、アプリケーションの高影響エリアに集中しましょう。データベースのパフォーマンスモニタリングツール(例:Sentry)を活用すれば、アプリケーション内で最も遅いデータベース操作を可視化できます。特に、次のポイントにご注目ください。
- 高影響のクエリ
実行時間が長いクエリや、重要なユーザーフローで頻繁に実行されるクエリを特定します。 - トランザクションのパターン
高トラフィックなエンドポイントや、繰り返し発生するトランザクションの中で、共通のボトルネックを見つけます。 - コンテキストの把握
遅いクエリがシステム全体のパフォーマンスにどのように影響を与えているのかを分析します。例えば、APIのレスポンスが遅延していないか、フロントエンドのレンダリングがブロックされていないか等です。
このアプローチにより、ユーザー体験を大幅に改善できる修正を優先し、目立たない処理の微細な最適化に留まらないようにできます。
2: データベースツールを使って診断する
問題のあるクエリを特定したら、データベースに組み込まれている診断ツールを活用し、さらに詳しく調査しましょう。
SQL: EXPLAIN を使用する

このコマンドを実行すると、クエリ実行計画(Query Execution Plan)が表示され、パフォーマンススコア、インデックスが使用されているかどうか、各行をスキャンしているか(フルテーブルスキャン)といった情報が得られます。下記で例を見ることができます。
もし Seq Scan(シーケンシャルスキャン)が表示された場合、それはインデックスが適用されていないフルテーブルスキャンを意味します。こうしたクエリは、インデックスを追加すべき箇所であるといえます。
NoSQL: .explain() を使用する

MongoDB などの NoSQL データベースでは、.explain() コマンドが同様のインサイトを提供します。例えば、COLLSCAN(コレクションスキャン)が表示された場合、それは全データをスキャンしている状態であるといえます。つまり、インデックスの追加を検討すべきタイミングであることを示しています。
3: インデックスを適用してテストする
SQL:
- 特定したカラムにインデックスを追加します。
過剰なインデックス作成を避けるため、できるだけ具体的に定義しましょう。
CREATE INDEX idx_products_category ON products(category);
その後、再度 EXPLAIN を実行し、以下の点を確認します。
・クエリが インデックススキャン(Index Scan)またはビットマップヒープスキャン(Bitmap Heap Scan) を使用しているか
・クエリの コストが削減されているか

NoSQL:
- .createIndex コマンドを使用してインデックスを追加します。db.products.createIndex({ category: 1 })
その後、.explain() を実行し、以下の点について確認します。
・クエリの実行計画にIXSCAN(インデックススキャン) が表示されているか
・以前 COLLSCAN(コレクションスキャン) だった場合、適切に切り替わっているか

このように、影響範囲の広いクエリに焦点を当てて修正をテストすることで、データベースのパフォーマンスを迅速に改善できます。
パフォーマンスモニタリングを活用すれば、正しい問題にアプローチできていることを確認でき、インデックス作成はその解決策の重要な一部となります。
インデックスがアプリケーションの高速化にどのように貢献するのか、素早く効果的な改善策を見つける方法、インデックスを作成し、適用後のパフォーマンス向上を確認する方法をご紹介してきました。
ここからは、Sentryを使用して、欠落しているインデックスの発見とデバッグのプロセスをどのように効率化できるか、実例を交えてご紹介していきましょう。
Sentryを使って習慣追跡アプリのインデックス不足を見つけて修正する
SentryのInsightsチームのプロダクトリードであるBenjamin Coeの最近の例を見てみましょう。彼はデモ用に習慣追跡アプリを立ち上げましたが、ユーザーがホームページとインタラクションするたびに顕著に遅くなっていました。
1:膨大なデータの中から問題のクエリを見つける
まず最初にやるべきことは、Sentryを導入することでした。私たちはPostgresデータベースをJavaScriptで使用していたため、特別な設定は不要でした。MongoDB、MySQL 1/2、GraphQLなどは、Sentryによって自動的にインストゥルメント化(計測可能状態にすること)されます。
次にすべきことは、SDK設定でトレーシングが正しく設定されていることを確認することだけです。それでは、さっそく始めましょう。
設定してから数分後。
ユーザーのトランザクションが流れ始め、バックエンドインサイトタブを開いて、フルスタックで最も時間がかかっているクエリを確認しました。そこで、気になるクエリを見つけました。
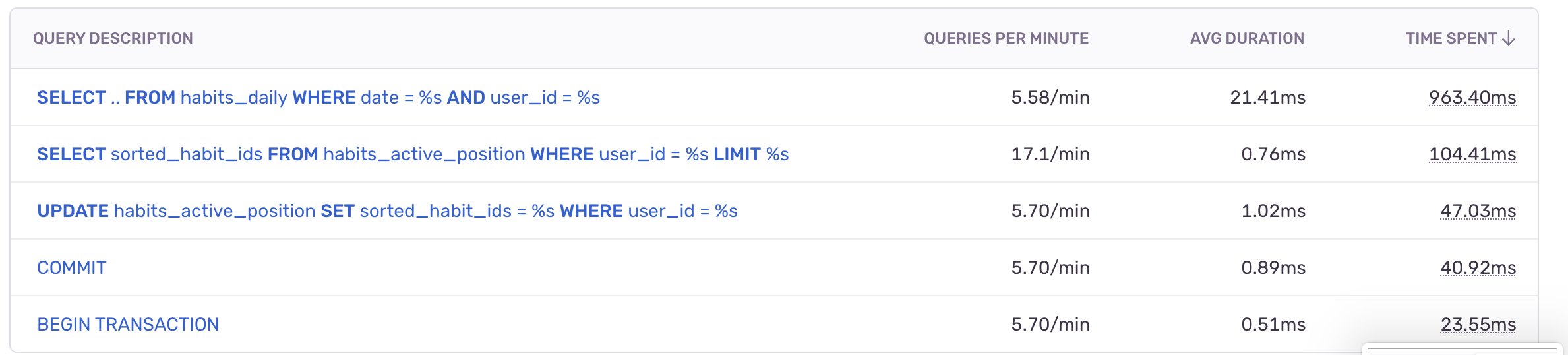
トップのSELECTクエリは、次に遅いクエリの約20倍の時間を要しており、他のどのクエリよりも約10倍の合計処理時間を費やしていました。クリックすると、完全なクエリが表示されました。

これはかなりシンプルなフェッチのはずです — 特定の日付と特定のユーザーに対する全ての習慣を取得しているだけです。なぜこんなに時間がかかっているのでしょうか?
2: EXPLAINクエリを実行してインデックスが正しく設定されているか確認する
データベースサーバーにSSHで接続し、問題のクエリに対してEXPLAINを実行することで、クエリの実行計画を分析しました。
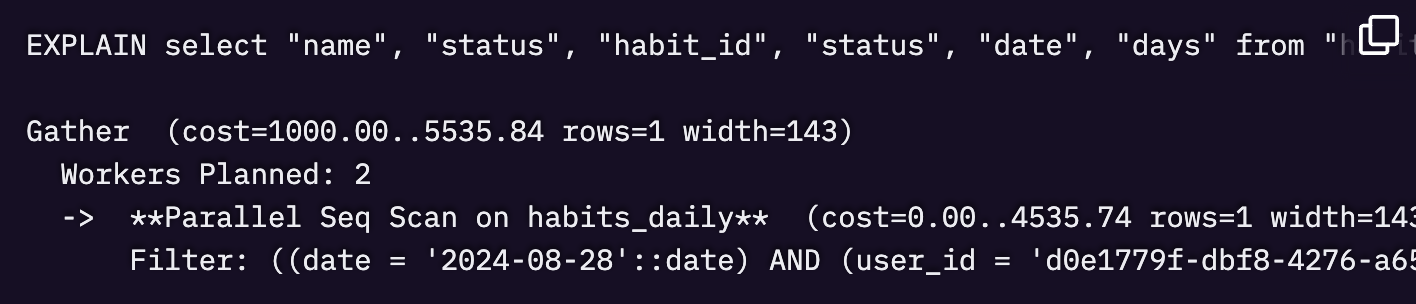
その結果、このクエリはフルテーブルスキャン (Parallel Seq Scan) を実行しており、データを収集するために 2 つの並列ワーカーを使用しようとしていることが判明しました。
わずか 143 バイトのデータを取得するために、ここまでの負荷がかかるのは明らかに非効率だといえます。
インデックスを追加すればすぐに改善できるはずなので、試してみることにしました。
注意:SentryはSQL内で変数を使用してインサイトを探しますが、EXPLAINは変数(例:date = $1 AND habits_daily.user_id = $2)では機能しません。変数を具体的な値に置き換える必要があります。
Sentryを使えば、特定のトレースにアクセスし、そこからクエリをコピーして、そのままEXPLAINに貼り付けて、再現することが簡単にできます。
3: 問題のクエリにインデックスを追加する
このテーブルの日付(dateカラム)にインデックスを付けるのは非常に簡単です。
DB CLIを開き、次のコマンドを実行しました。

これで habits_daily テーブルの date カラムにインデックスが作成されました。
EXPLAINを再実行して、結果を見てみましょう。

明らかに ビットマップヒープスキャン (Bitmap Heap Scan) に切り替わっている ことがわかります。これにより、テーブル全体をスキャンするのではなく、インデックスを参照して直接行ポインタを取得 するようになりました。
結果として、推定コストが 4535.74 から 4.35 に低下し、約 1000 倍の改善 が見られました。
注意:user_id はこのテーブルの主キーであり、デフォルトでインデックスが付与されています。ただし、もし user_id にインデックスが付いていなかった場合、またはこのような検索が頻繁に行われる場合は、CREATE INDEX […] ON habits_daily(user_id, date) のように複合インデックスを作成するとさらに効果的です。
4: Sentryで修正を実際に確認する
Sentryのバックエンドインサイトタブに戻り、修正が本番環境でユーザーに対してどのような影響を与えているのか確認してみましょう。
確かに、速度が約20倍向上しています!
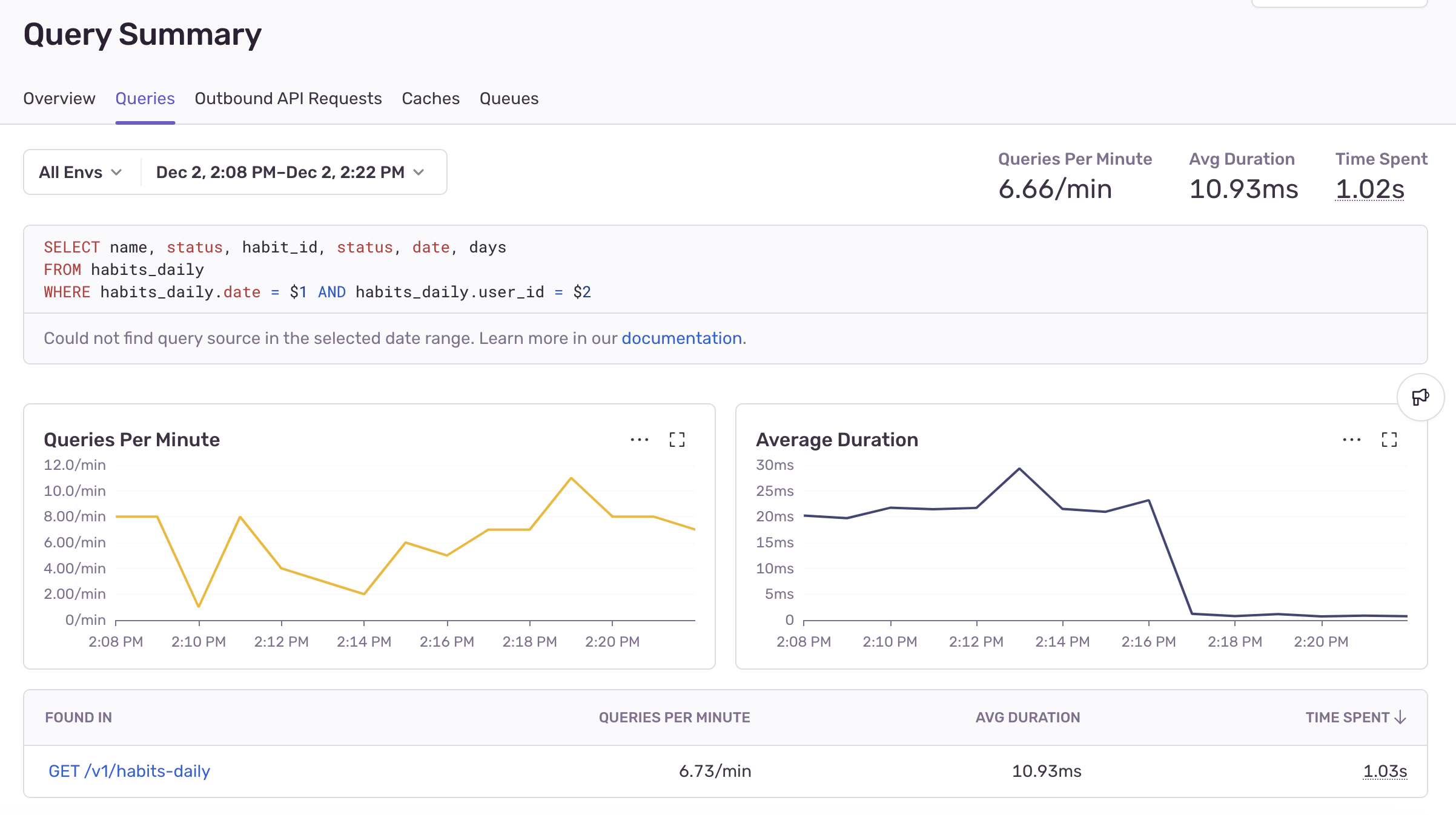
このプロセス全体で、識別から解決および検証までにかかった時間はおそらく15分ほどでした。データベースを掘り下げて、すべてのテーブルのインデックスを手動でテストする代わりに、問題のクエリを瞬時に見つけ、適切なインデックスをテストし、実際のプロダクション環境でクエリの修正を確認することができました。
Sentryで遅いクエリを見つけて高速化する
それでは最後にまとめます。
Sentryのバックエンドインサイトは、遅いクエリを特定し、バックエンドのどこで遅延が発生しているかを可視化します。
それが最適化されていないクエリであれ、インデックスの不足であれ、効率の悪いトランザクションであれ、パフォーマンスのボトルネックをわかりやすく表示します。
これは、Sentryの分散トレーシングとインサイトを使用して、バックエンドのパフォーマンスバグを発見する方法の一つに過ぎません。
将来的に、今後の投稿では、キャッシュ、キュー、データベース操作などについても取り上げていく予定です。
まずは、Sentryのトレーシングを使ってアプリを計測し、バックエンドインサイトで問題箇所を特定し、遅いクエリの診断と修正手順を進めてください。
Sentryアカウントをお持ちでない場合は、こちらから無料で始めることができます。
質問があれば、いつでもDiscordでご質問ください。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

