ハカン・テクグル(MLソリューション・エンジニア)|2023年5月21日号掲載
効果的な大規模言語モデル運用の3つの鍵
このブログの共著者はAparna Dhinakaranです。
本番環境における機械学習モデルの運用と効果的なモニタリング(MLOps)は、ここ数年新たなトピックとなっています。
本番環境でモデルが静かに故障し始めた場合、問題を理解し、タイムリーにモデルのトラブルシューティングを行うために、適切なセットアップを行うことが重要です。
GPT-4が従来の様々なモデル・タスクの代替として使用される機会は日々増加しています。
現在、多くのチームがモデルとみなしているものも、将来的にはプロンプトとレスポンスのペアになるかもしれません。
チームが大規模な言語モデルを本番環境に導入する際にも、パフォーマンスやタスクの測定に関する課題は依然として存在します。
したがって、LLMOpsは大規模な言語モデルをスケールし、効果的に本番環境にデプロイするために不可欠です。
LLMOpsとは何か?
大規模言語モデル運用(LLMOps)は、プロンプトエンジニアリング、LLMエージェントのデプロイ、LLMの観測性など、いくつかのテクニックを組み合わせて、言語モデルを特定のコンテキストに最適化し、ユーザーに期待通りの出力を提供できるようにするための分野のことです。
この記事では、それぞれのテクニックを詳しく取り上げ、プロダクトでLLMを維持するためのベストプラクティスについて解説していきます。

プロンプトエンジニアリング
プロンプトとレスポンスという概念は、大規模な言語モデルの導入後に普及し始めました。プロンプトとはユーザが言語モデルに提供する特定のタスクのことで、レスポンスとはタスクを達成するための言語モデルの出力のことです。
例えば、ユーザが最近の診断の医療レポートを提供し、ChatGPTにドキュメントの要約を依頼するとします。
この場合、医療文書と要約するアクションがプロンプトであり、要約自体がレスポンスを意味します。
プロンプトエンジニアリングとは、簡単に言えば、ChatGPTのようなAIソフトウェアと会話し、情報を受け取る能力のことです。
プロンプトエンジニアリングが上手であればあるほど、LLMに対する特定のタスクを完了させるために必要な指示が的確になります。
注意深く作られたプロンプトは、モデルが望ましいアウトプットを生成するように導くことができますが、一方、プロンプトの作りが悪いと、無関係な、あるいは無意味な結果をもたらす可能性があります。
プロンプト・エンジニアリングの一般的なアプローチとは?
プロンプトエンジニアリングの一般的なアプローチには、数発のプロンプト、インストラクターベースのプロンプト、思考の連鎖プロンプト、自動プロンプト生成などがあります。それぞれについて掘り下げてみましょう。
Few-Shotプロンプティング
Few-Shotプロンプティングは、プロンプトエンジニアリングのテクニックで、ユーザが大規模な言語モデルが実行すべきタスクのいくつかの例とタスクの説明を提供する。これは、タスクの具体例がある場合に使用すると非常に便利なテクニックです。
Instructor-Basedプロンプティング
Instructor-Basedプロンプティングは、LLMに特定の人物になりきってタスクを実行するよう指示するものです。
例えば、特定のトピックについてブログを書こうとしている場合、プロンプトの例としては、「あなた(LLM)はこのトピックに関する専門家として…」で始めることです。こうすることで、反応が最適化されます。
思考連鎖プロンプティング / CoTプロンプティング
思考連鎖プロンプティング(CoTプロンプティング)は、適切なレスポンスを得るために小さなタスクを段階的な順序で実行するよう指示する手法です。複雑なタスクを達成するために使用されます。CoTプロンプトをインストラクターベースのプロンプトや数発プロンプトと組み合わせることで、最良の結果を得ることができます。
プロンプトの自動生成
最後に、大規模な言語モデルを活用して、特定のタスクに対するプロンプトを生成することもできます。ユーザーは、達成したいタスクを数行記述するだけで、言語モデルにさまざまな選択肢を提示させることができます。その後、ユーザーは最適なプロンプトを検索し、最も興味のあるプロンプトを選択することができます。
なぜプロンプト・テンプレートが重要なのか?
プロンプトエンジニアリング以外に、プロンプトテンプレートを使用することは、タスク固有のLLMを本番環境に導入する上で非常に重要です。プロンプトテンプレートは、ユーザーのプロンプトの直前に置かれるプリアンブルテキストとして定義できます。プロンプトテンプレートを使用することで、LLM開発者はユーザーが提供するプロンプトのシンプルさに関係なく、出力形式と品質を標準化することができます。
プロンプトテンプレートは、プロンプトを生成するためのスケーラブルで再現可能な方法を作成し、言語モデルへの指示、数ショットの例、または実行するアクションの異なるチェーンを含めることができます。具体的な例を見てみましょう。
プロンプト・テンプレート
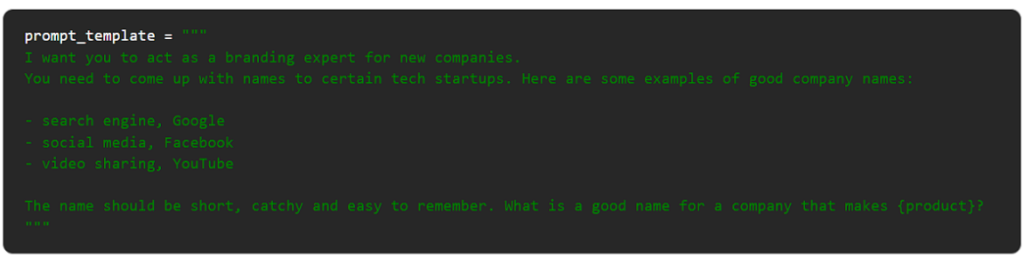
上の例は、再現可能なアウトプットのための言語モデルを準備するために、少数ショットと命令ベースの言語を使用するプロンプトです。このテンプレートを使って、異なる製品セットに固有の名前を生成できるLLMアプリケーションを展開することができます。ユーザーがしなければならないのは、製品の種類を入力することだけです!
プロンプトはどのように管理されるのか?
プロンプトエンジニアリングとプロンプトテンプレートのほかに、本番環境でのプロンプト管理を考慮することも重要です。LLMアプリケーション内では、さまざまなプロンプトテンプレートやユーザー入力が継続的に実行される可能性があり、プロンプトを保存し、そのワークフローを制御することは非常に重要です。したがって、アプリケーション開発中に本番用プロンプトを入れ替えたり、プロンプトを反復したりする機能を考慮する必要があります。たとえば、ユーザーからのフィードバックに基づいて、さまざまなプロンプトテンプレートを使用してA/Bテストを実施し、各プロンプトのパフォーマンスをリアルタイムで追跡することができます。
LLMエージェントとは何ですか?
プロンプトを効果的に管理することとは別に、特定のコンテキストやタスクに合わせた特定のLLMアプリケーションを開発することは、困難な取り組みであることがわかります。
これには通常、関連データを収集し、それを処理するためにさまざまな方法を利用し、LLMを微調整して、ビジネスコンテキスト内で最適な応答を提供できるようにすることが含まれます。
幸いなことに、プロセスを合理化し、アプリケーションをより効率的に拡張できるツールがいくつかあります。
LLM開発者の間で最も人気のあるツールの1つは、LLMエージェントです。このツールは、論理的な順序で関連するプロンプトと回答のシーケンスを作成することにより、ユーザが迅速に回答を生成できるように支援します。
LLMエージェントは、LLMを活用し、ユーザーの最初のプロンプトに基づいて、どのアクションを取るべきかを決定します。LLMエージェントは、ウェブサイトの検索やデータベースからの情報抽出などのタスクを実行するように設計されたさまざまなツールを利用し、ユーザーに包括的で詳細な回答を提供します。
基本的にエージェントはLLMとプロンプトテンプレートを組み合わせて、最終的にユーザーに回答を提供する一連のプロンプトと回答のペアを作成します。
エージェントは、様々なソースからコンテキストに特化したデータを引き出し、適切なプロンプトテンプレートを利用することで、ユーザーにとって最も価値のある情報を探し出す、エキスパートのブレンドとして機能することができます。LLMエージェントの最も顕著な例の一つがLangChainであり、一般的に検索拡張生成の概念を採用しています。このアプローチでは、ユーザのクエリに答える最も関連性の高い情報を特定するために、ドキュメントの一部を使用します。LLMエージェントのアーキテクチャ図を以下に示します。
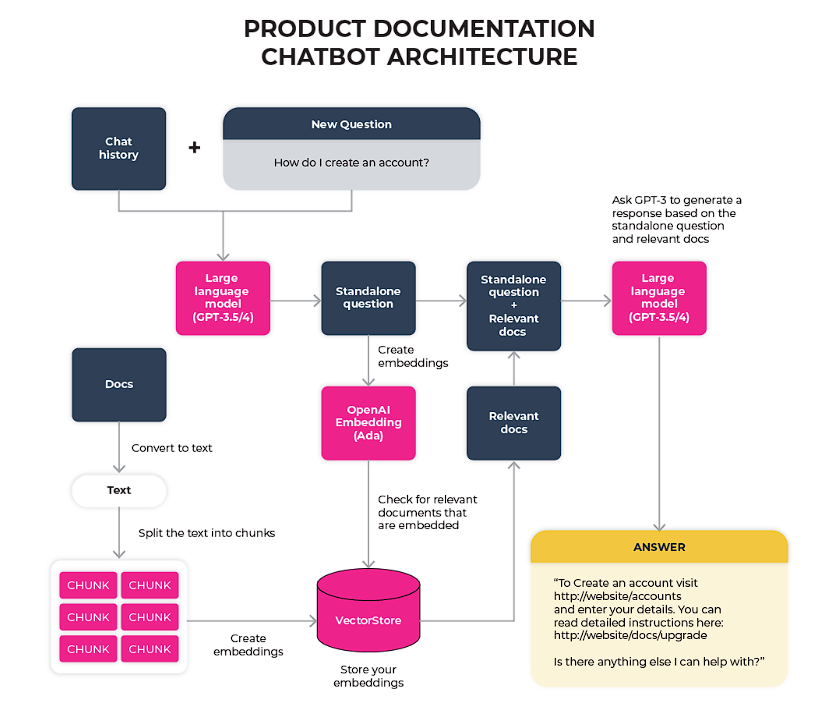
製品ドキュメンテーションチャットボットのためのLLMエージェントアーキテクチャの例
LLMの可観測性とは?
前述したように、多くの機械学習チームが達成しようとしていることは、将来的にはプロンプトやエージェントの連鎖で達成されるかもしれません。そのため、従来の機械学習の可観測性と同様に、LLMの可観測性は、LLMアプリケーションを大規模にデプロイするために必要不可欠です。
LLMの可観測性は、すべてのプロンプトテンプレート、プロンプト、および応答がリアルタイムで監視されていることを確認するためのツールであり、プロンプトエンジニアは、否定的なフィードバックの根本原因を容易に見つけ、理解し、プロンプトを改善することができます。
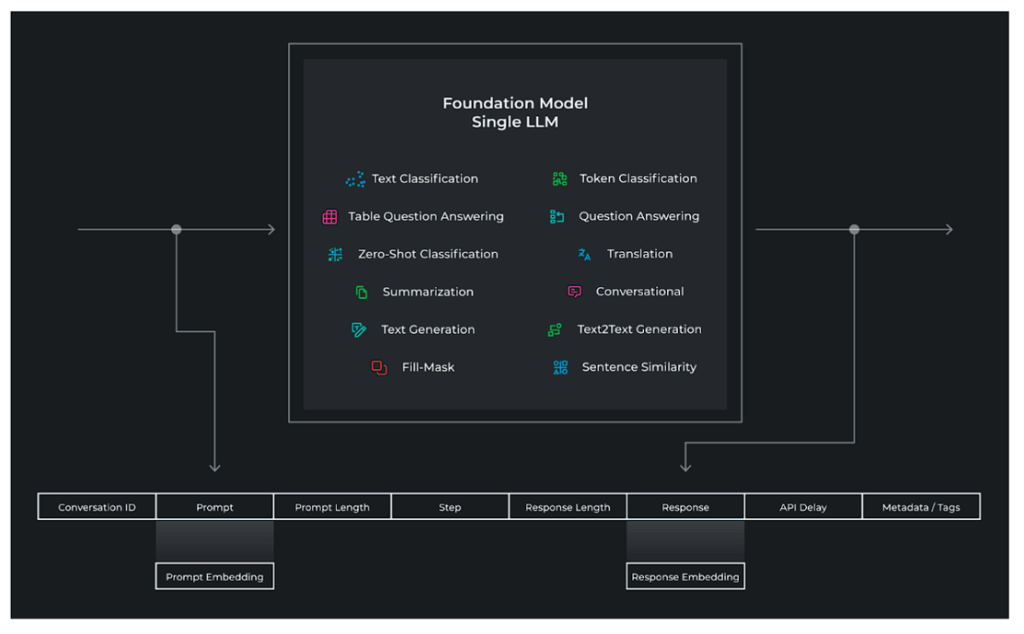
LLM観測システムが収集するデータとは?
上の図は、LLMの可観測性が基礎モデルの世界でどのように見えるかを示しています。システムへ出入りするインターフェースは、プロンプトとレスポンスのペアの文字列です。入力と出力は、可観測システムによって収集される、以下のようなデータで構成されています。
- プロンプトとレスポンス
- プロンプトとレスポンスの埋め込み
- プロンプトテンプレート
- プロンプトトークンの長さ
- 会話のステップ
- 保存ID
- レスポンス・トークンの長さ
- 構造化メタデータ、予測グループのタグ付け
- 埋め込まれたメタデータ、埋め込まれた追加メタデータ
埋め込み
エンベッディングとは情報の内部潜在表現であり、モデルが何を「考え」、特定のデータをどのように「見ているか」の内部表現のことです。GPT-4のような基礎モデルでは、チームはその特定のモデルの内部エンベッディングにアクセスすることはできませんが、エンベッディング生成モデルを使用してエンベッディングを生成することはできます。埋め込み生成モデルは、GPT-JやBERTのようなローカルで実行されるモデルのことです。
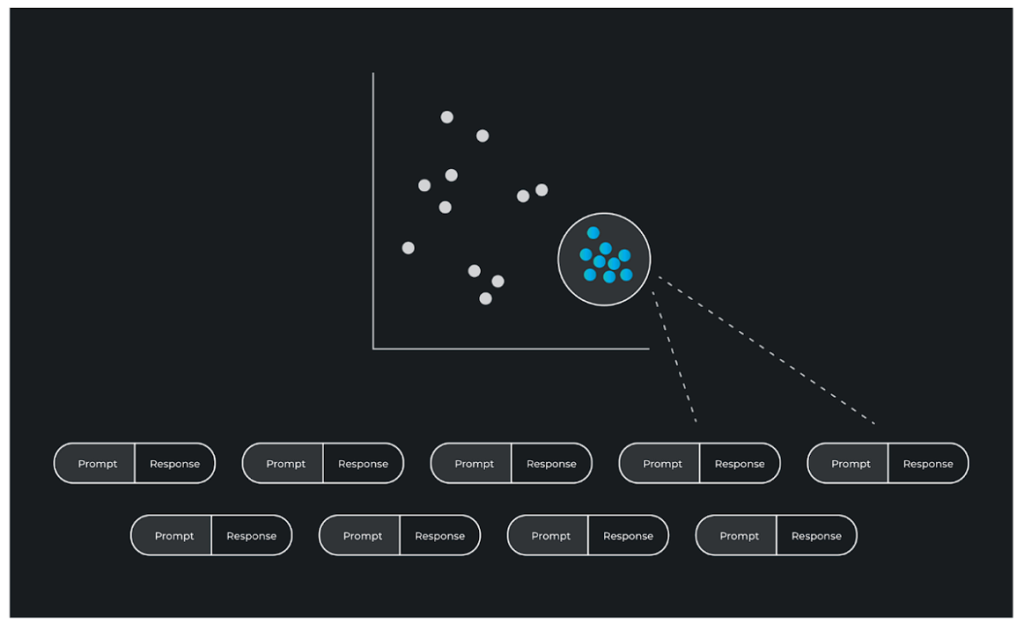
これらの埋め込みは、高次元空間をリアルタイムで監視することができ、行動の変化やユーザーからの否定的なフィードバックは、LLMアプリケーション内の問題を示すことができます。問題のある応答を見つける1つの方法は、プロンプトと応答をクラスタリングし、クラスタごとの評価指標、クラスタごとのドリフト、またはクラスタごとのサムアップ/サムダウンなどのユーザーフィードバックを調べることによって、問題のあるクラスタを見つけることに繋がります。
トラブルシューティングのワークフローと例
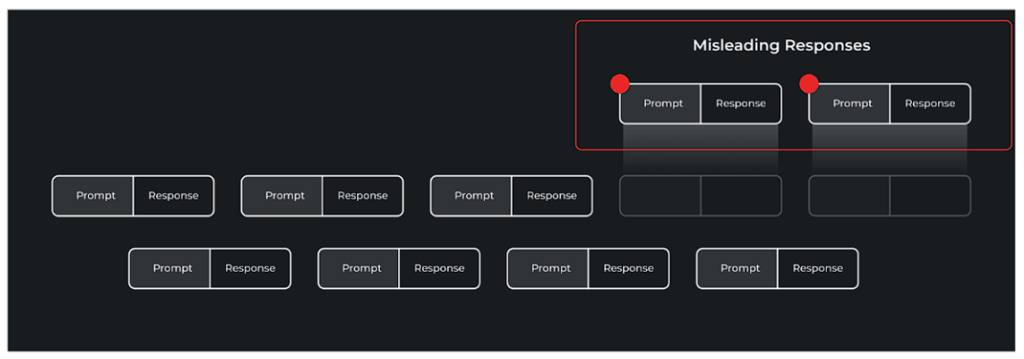
検出の一部として捕捉された問題は上に示されており、特定の形式の誤解を招く回答がグループ化され、強調表示されています。これらの誤解を招くような回答は、プロンプトエンジニアリングやファインチューニングを通じて、多くの反復ワークフローを通じて修正することができます。
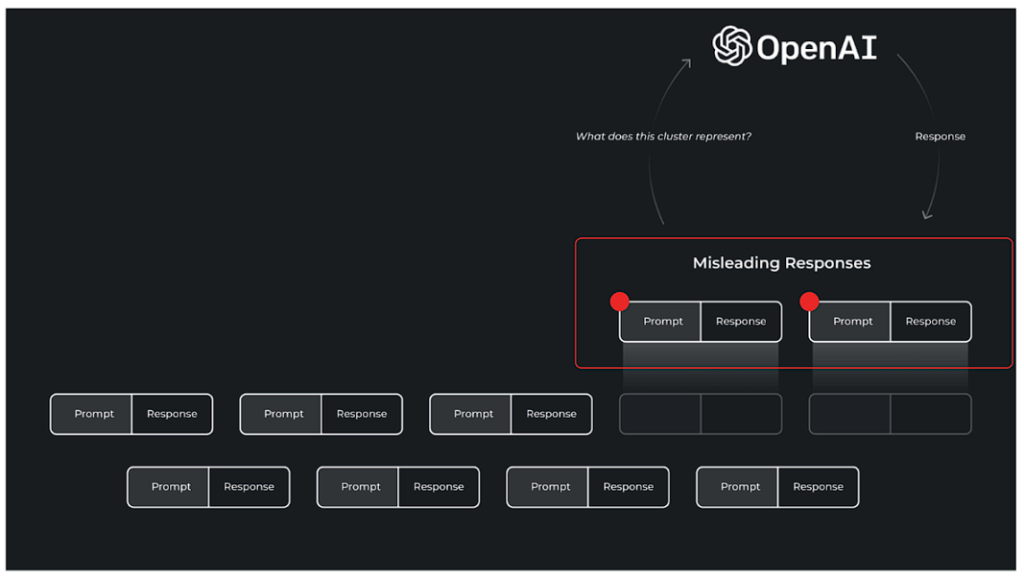
ひとたび問題のクラスターを見つけたら、そのクラスターの中で具体的に何が問題なのかを理解するには、それなりに作業が必要になります。
LLMを統合して、重い作業を行うことをお勧めします。LLMの可観測性ツールには、クラスタ分析およびベースラインデータセットとのクラスタ比較を行うための、クラスタデータを含むLLM用のプロンプトテンプレートが用意されているはずです。
完全なデータストリームのクラスター分析に加えて、多くのチームは、プロンプトとレスポンスのペアに関連する構造化データでデータをセグメント化する可観測性ソリューションを望んでいます。このメタデータはAPIレイテンシ情報となり、チームはクラスタにズームインする前に、大きな遅延を引き起こしているプロンプト/レスポンスのペアに焦点を絞って調査できます。
あるいは、プロダクション・インテグレーションによって提供される構造化されたメタデータに基づいて掘り下げることもできます。これらは、プロンプト前のタスクカテゴリや、予測に関連するあらゆるメタデータに関連することができます。
結論
結論として、様々なアプリケーションにおける大規模言語モデルの急速な増加により、効果的な運用戦略の開発が必要となり、これらのモデルが本番環境で最適に動作することを保証するために、LLMOpsという比較的新しい分野が必要となりました。
LLMOpsの主な構成要素には、プロンプトエンジニアリングと管理、LLMエージェント、LLM可観測性などがあります。
これらの技術を採用することで、開発者は特定のタスクを処理するためにLLMを最適化し、プロンプトを効率的に管理し、モデルのパフォーマンスをリアルタイムで監視することができるようになります。
LLMの採用が拡大し続ける中、LLMの可観測性により、プロンプトエンジニアリングワークフローの微調整と反復が可能になります。
問題のある回答のクラスターを特定することで、開発者はプロンプト・エンジニアリングのテクニックを改良したり、モデルのパフォーマンスを向上させるために微調整を行ったりすることができます。この反復プロセスにより、LLMアプリケーションの継続的な改善が保証され、より良いユーザー体験へつながります。