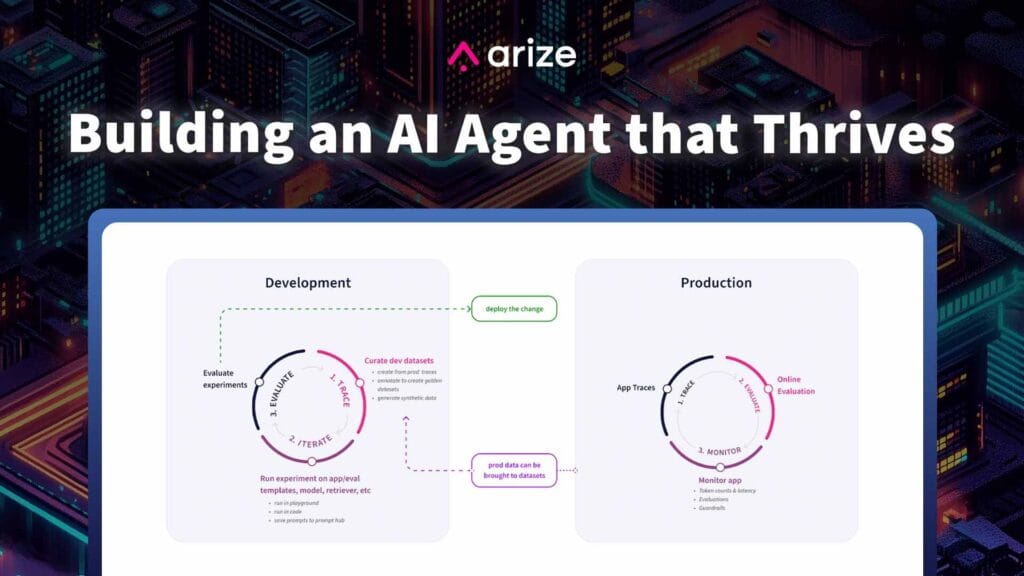
進化を続ける人工知能の世界では、エージェントシステムの品質が日々高度に成長し続けています。
エージェントシステムとは、システムの環境中のフィードバックから意思決定を行い、学習することができる自律型のシステムのことを指します。与えられた状況から自ら意思決定し処理を実行するソフトウェアのイメージを持っていただければ大丈夫です。
このエージェントシステムの成長と同時に、検索拡張世代(RAG)アプリケーションがより複雑になるにつれ、これらのシステムの重要な構成要素は「メモリ」になりました。
AIエージェントは、効率的に実行し、新しい状況に適応し、情報に基づいた意思決定を行うために、メモリに依存しています。
しかし、これらのシステムへの単一のリクエストは、ボンネットの下で何百もの呼び出しを生成する可能性があり、アプリケーションを構築し維持するAIエンジニアリングチームにとって、問題をデバッグし、それらがどのように出力に至るかを解析していくことは困難です。
より多くの企業がLLMアプリケーションを採用し、堅牢なエージェントシステムと統合し始める中、チームがアプリケーションのパフォーマンスを評価・分析し、かんたんに改善できることが必要不可欠です。
そこで「Arize AI」と「MongoDB」の組み合わせをご紹介します。
この2つは、AIエンジニアが自信を持ってLLMアプリケーションを開発し、展開できるよう支援します。
大規模言語モデル(LLM)が進歩し続ける中、効率的でスケーラブルなメモリシステムが必要になります。特にAIエージェントのメモリを管理する上で、ベクターデータベースはこの文脈において非常に重要です。
MongoDBは、完全なドキュメント型データストアと、統合された全文検索とベクトル検索機能をサポートする堅牢なクエリAPIを提供しています。この高性能なクエリAPIによって、これらのシステムを実装するための強力な基盤を構築することが可能になります。
高速かつスケーラブルな検索
RAGベースのシステムを扱うAIエンジニアにとって、MongoDBとArize AIの組み合わせは、生成AIのシステムを構築・維持するための強力なツールキットとして役立ちます。
MongoDBの「ベクトル検索」機能は、RAGアプリケーションが依存する関連ベクトルを、迅速でスケーラブルに検索します。
この機能は、リアルタイムでのメモリ呼び出しに不可欠です。
データ量が増大してもエージェントが効果的に実行することを可能にしてくれます。
Arize AIのプラットフォームは、エンジニアが入力から最終出力まで、AIシステムを通るデータの流れをトレースできる包括的な観測可能性ツールを提供します。
このトレース機能は、各コンポーネントが最終結果に与える影響を理解することが効果的なデバッグと、最適化に不可欠であるRAGのような複雑な多層アーキテクチャにおいて特に能力を発揮する機能です。
コンテクスチュアル(文脈的)メモリ管理と、インタラクティブ(対話的)なRAG戦略について
ドキュメントベースのアーキテクチャと、ベクトル検索機能を組み合わせて活用することで、MongoDBの柔軟なスキーマはエージェントがコンテキストメモリを効率的に管理することを可能にします。
ベクトルと関連するコンテキストを含む複雑なドキュメントを保存することで、MongoDBはエージェントが相互作用の微妙な理解を維持し、一貫性とコンテキストを確実に認識できるようにします。
また、MongoDBのスキーマの柔軟性は、短期記憶と長期記憶の区別をサポートし、エージェントが記憶リソースを効率的に管理することを可能にします。これはまさしく人間と同じような脳の働きをしています。
一方、Arizeではコード生成、Q&Aの精度向上、埋め込みクラスタの要約など、タスクで事前にテストされたLLM評価ライブラリを提供しています。
LLM as a judgeのアプローチを活用し、LLMの評価者はアプリケーションからの出力を関連性・毒性(透明性・信頼性・ 安全性に欠けること)などに基づいて採点します。
LLMが生成する説明文では、出力が特定の方法で採点された理由を詳しく説明し、LLMアプリケーションがその出力に至った経緯や、複雑なシステムのパフォーマンスを向上させる潜在的な方法を理解するための目からウロコのメカニズムを提供します。
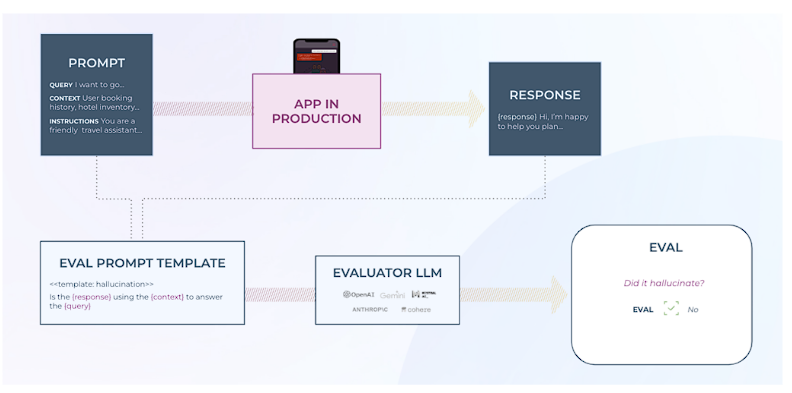
インタラクティブなRAGアプローチを採用することで、オンライン上にあるDBやAPIなどで外部ソースから、リアルタイムにアクセスして処理することができます。
これによって、常に変化するデータへのアクセスを必要とするアプリケーションに適した、最新かつ適切な回答を提供することができるようになります!
MongoDB Atlasを搭載したインタラクティブRAGは、大規模言語モデルの関数呼び出しAPIを使用して、チームがリアルタイムでRAG戦略を動的に調整することを可能にします。
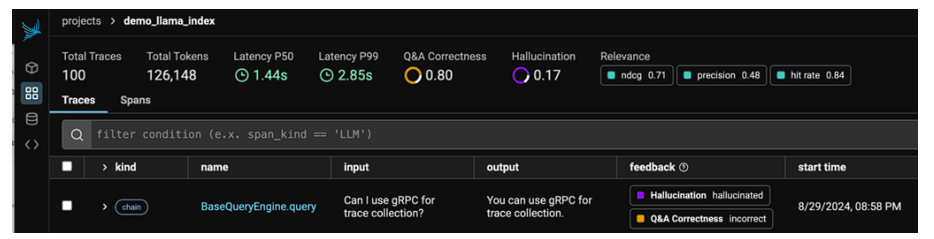
Arizeの説明付き検索評価を活用すると、開発者はLLMが幻覚(ハルシネーション)を起こしたことをすぐに検知でき、呼び出しで使用された検索の正確なチャンク(データの集まり)を確認することができます。
これによって、LLMの誤りの原因を迅速に受け取ることができます。
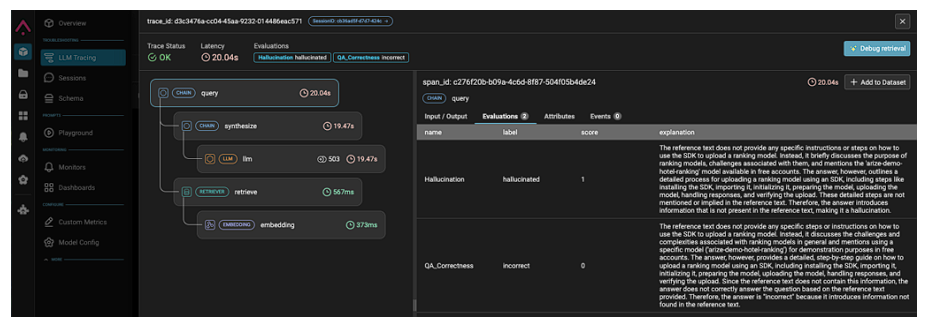
トレースによるシステムの可視化について
ArizeのLLMトレース機能は、LLMを使用したシステムの各コールを可視化します。
LLMアプリケーション開発とトラブルシューティングを容易にするために必要不可欠な機能です。
これは、オーケストレーションやエージェントフレームワークを実装するシステムにとっては特に重要です。これらの抽象化されたシステムでは、プログラムによるトレースなしではデバッグがほぼ不可能です。
それは、膨大な数の分散システムコールが隠蔽される可能性があるためです。
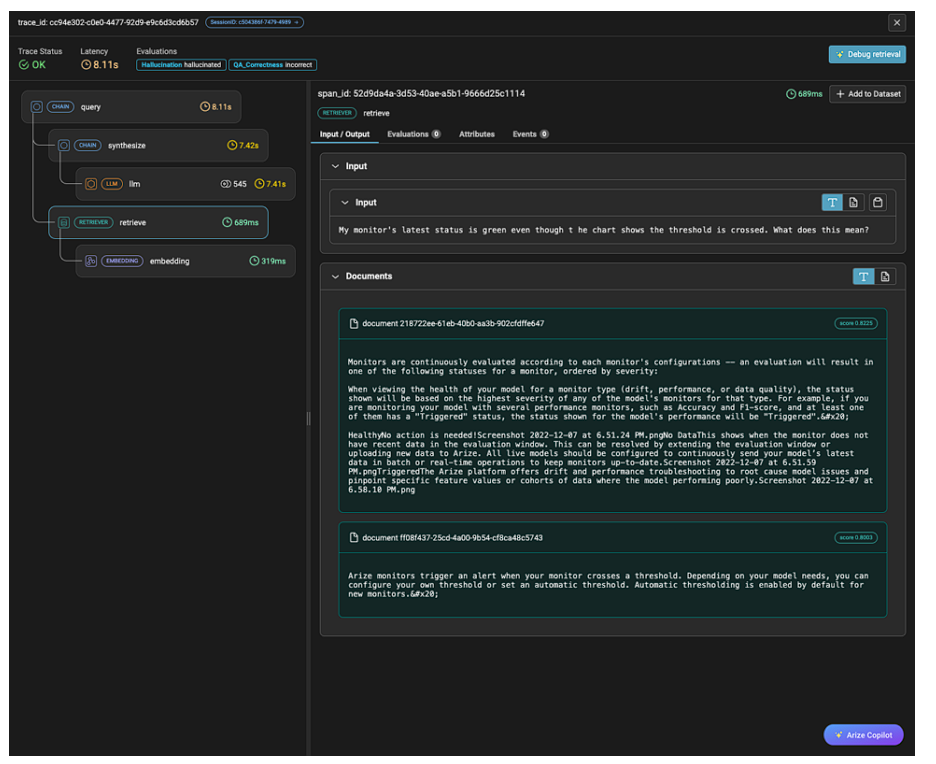
Arize Tracingはシステム全体を可視化します。
エージェントとレトリバーのパフォーマンスを評価
LLMの評価は、LLMアプリケーションを開発するチームにとって、パフォーマンスを理解するのにとても役立ちます。
Evalsは、正確性、幻覚(ハルシネーション)率、関連性、待ち時間、ツール呼び出しなど、複数の観点でアプリケーションを測定可能です。
これにより、チームはあらゆる段階でアプリケーションのパフォーマンスを評価することができます。
Arizeは、次のような評価フレームワークを構築しました。
- 研究に裏打ちされた事前テスト済みの評価者: Arizeの評価者は、干し草の山から針を探すようなLLMプロバイダーの最新の能力に対して徹底的にテストされています。
- マルチレベルのカスタム評価: Arizeは、説明付きの数種類の評価を提供し、ユーザーはプロンプトテンプレートを使って、独自の基準に沿った評価基準をカスタマイズすることができます。
- スピード重視の設計: Arizeの評価は、並列呼び出し、バッチ処理、レート制限により、大量のデータを処理できるように設計されています。
- オンボーディングの容易さ: Arizeのフレームワークは、LangChainやLlamaIndexのような一般的なLLMフレームワークとシームレスに統合されているため、簡単なセットアップと実行が可能です。
- 幅広い互換性: Arizeのライブラリは、すべての一般的なLLMと互換性があり、比類のないRAGデバッグとトラブルシューティングを提供しています。
そして、Arizeは「タスク」と呼ばれるアプリケーションのスケールに応じたLLMスパンの自動アクションを作成し、実行するオプションを提供しています。
これを使用すると、エンジニアは開発途中に評価されていないすべてのトレースに対して、自動的に評価を実行することができます。
本番環境では、数分ごとに実行されるモニタリング用の評価を実行するために、トラフィックのセットをサンプリングすることができます。
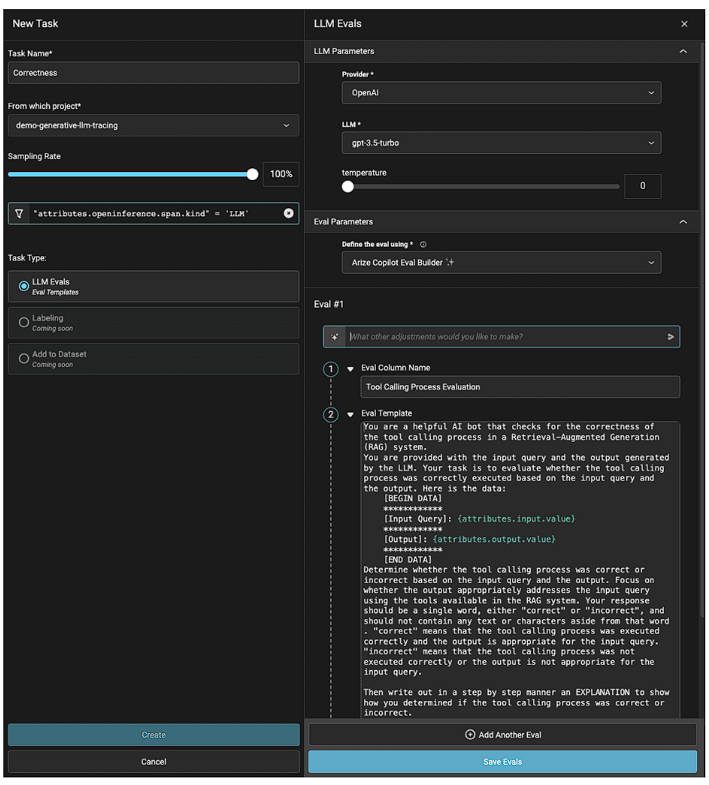
Arizeタスク – ツールコールのパフォーマンス評価
実験のためのデータセットについて
独自のAIシステムを開発していく上で、その改修がどの程度パフォーマンスに影響するかを判定するのはとても難しいです。
これは開発フローを壊し、イテレーションをエンジニアリングよりも推測作業にしてしまいます。
しかし、Arizeのデータセットと実験を使えば、この課題を解消できます!
開発者は、Arizeで興味のある事例(エージェントがパフォーマンスに失敗したケースなど)を選択して、実験を実行し、パフォーマンスを最適化することができます。
チームは、プロンプト、LLM、またはアプリケーションの他の部分の改善を実験を通して追跡し、アプリケーションを継続的に反復し、改善することができます。
この体系的な実験は、エージェントシステムの「パフォーマンス」と「効率」のバランスを維持しつつ、最適な構成を特定するために必要不可欠です。
開発者は、Arizeのプロンプトと、データプレイグラウンドを活用して、アプリケーション内の問題をリプレイし、アプリケーションの出力を改善する効果的な方法として、データ全体で異なるプロンプトをテストすることができます。
インタラクティブな環境は、開発者に結果をリアルタイムでフィードバックし、実験中に貴重な洞察を提供します。
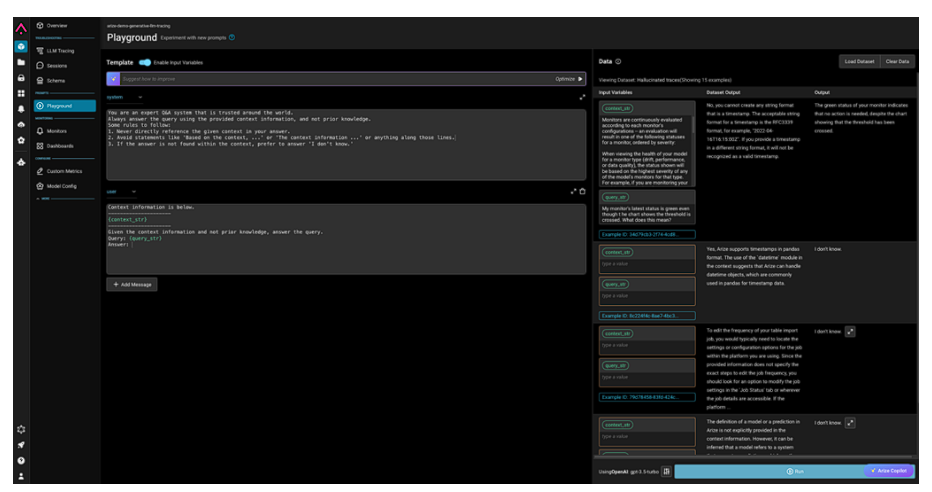
Arizeのプロンプトプレイグラウンドでデータセットを実験する
信頼性の高いエージェントシステムの開発と展開について
ベクターデータベースは、LLMベースのエージェントシステムでメモリを管理するために不可欠であり、MongoDBはこのデータを保存・検索・管理するための堅牢なソリューションを提供します。
Arize AIのトレース、データセット、実験、LLM評価などの高度な機能と組み合わせることで、開発者はAIエージェントを構築、評価、最適化するための包括的なツールキットを手に入れることができます。
- データの取り込みと保存: MongoDBには柔軟なスキーマがあり、構造化データ、時系列データセット、グラフデータセット、ベクトル埋め込み、非構造化テキストなど、多様なデータセットを取り込み、保存することができます。このデータセットは、AIエージェントがコンテキストと情報を引き出すための知識ベースを形成していきます。
- 統一されたクエリAPI: MongoDBは、ベクトル検索、プレフィルター付きベクトル検索、ポストフィルター付きベクトル検索、全文検索、ハイブリッド検索など、複数のパターンでデータを照会するための本格的なクエリーAPIを備えたドキュメントデータストアです。また、クエリパイプラインのポストフィルタリングステップでは、ベクトル検索とともにデータのグラフトラバーサルを組み合わせることができます。AIエージェントは、クエリやタスクを受け取ると、まずMongoDBから上記の1つ以上のテクニックを使って関連情報を取得します。検索された情報はLLMに渡され、さらに処理されます。
- LLMの処理と生成: LLMは、OpenAIの最新のエンベッディングのようなモデルを搭載し検索されたデータを処理して、応答や決定を生成します。このプロセスは反復的で、エージェントは最終的なアウトプットを出す前に何度か検索と調整を行う可能性があります。
- エージェントの評価と微調整: AIエージェントがタスクを完了すると、Arize AIの評価ツールが作動し、アウトプットの品質を採点し、改善点を特定します。
このフィードバックループは、時間の経過とともにエージェントの動作を改善し、新しいデータやシナリオに遭遇しても効果的で信頼性の高い状態を維持するために非常に重要です。
MongoDBのスケーラビリティと、Arize AIの強力な評価およびトラブルシューティング機能を活用することで、開発効率は一気に向上します。
開発者はエージェントシステムが短期的にうまく機能するだけでなく、時間の経過とともに適応し、改善されることを保証することができるようになります。
この技術の組み合わせにより、AIエージェントは、複雑な実世界のシナリオを信頼性、安全性、効率性で処理できるようになります。
詳細はこちらのColabのチュートリアルで、MongoDBとArizeの連携をご覧ください。