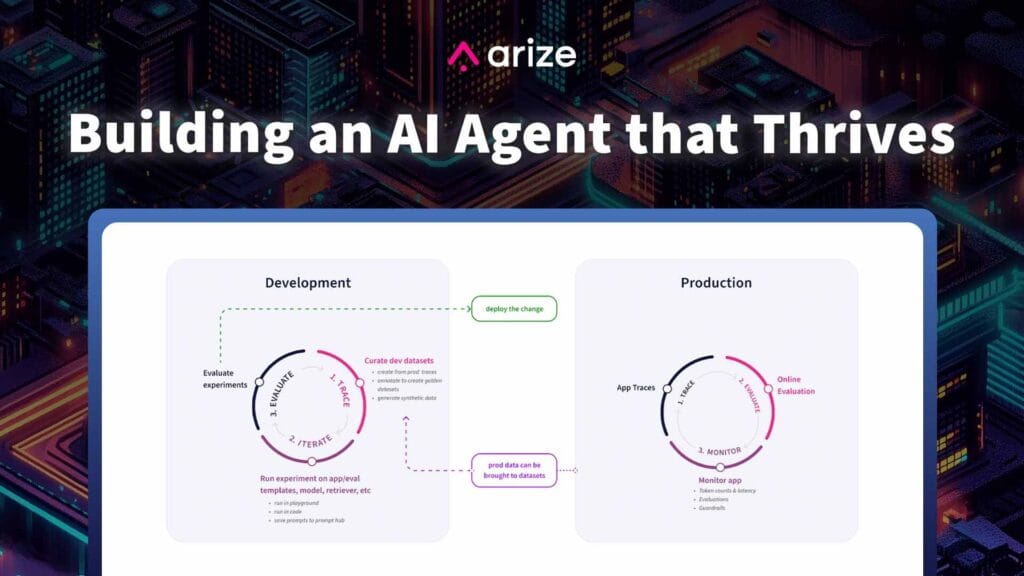
先日、Arize AI主催のワークショップ「RAG Time」に参加しました。
そこでは『LLM Evals と BenchmarkingでRAGを評価する』というタイトルのワークショップに参加しました。
アンバー・ロバーツ氏(Arize AIの機械学習グロースリード)とミキョー・キング氏(Arize AIのオープンソース責任者)が主催したこの講演は、重要な研究分野についての貴重な洞察を提供してくれました。
LlamaIndexを使用したRAGパイプラインの構築からPhoenixを活用した応答評価までをカバーするコードアロングエクササイズとともに、主な学びと収穫をご紹介します。

検索拡張生成(RAG)とは何か?
RAG (Retrieval-Augmented Generation)は、元の学習データソースを超えた権威ある知識ベースを活用することで、言語モデルの出力を強化します。
これにより、モデルは生成プロセス中に外部情報を参照して応答を改良します。
下図は、RAGがどのように機能するかを示しています。

RAGは、特定のドメインや組織内部の知識リポジトリに対応するために、LLMの既存の堅牢な機能を強化します。
RAGは、LLMの出力を強化し、その関連性、正確性、およびさまざまなシナリオでの有用性を確保するためのコスト効率の高い方法を提供します。
RAGの長所には、独自のデータを活用することでLLMアプリケーションのパフォーマンスを向上させ、継続的な進歩の恩恵を受けて結果を改善することが挙げられます。
一方短所としては、RAGワークフローのトラブルシューティングに時間がかかる可能性があることと、システムが適切に監視されない場合に複数の障害が発生するリスクがあることが挙げられます。
RAG構築における重要なステップ
RAGには5つの重要な段階があり、これらは大規模なRAG構築の一部となります。
- Loading
この段階では、テキストファイル、PDF、Webサイト、DB、APIなどの多様なソースからデータを収集し、パイプラインに統合します。
- Indexing
ベクトル埋め込み、数値データ表現、文脈情報検索の精度を向上させるためのメタデータ戦略の活用によって、LLMに堅牢なデータ構造を構築します。
- Storing
インデックスの再作成を防ぎ、効率的なデータ検索を実現するためには、最初のインデックス作成後にインデックスとそのメタデータを保存することが重要です。
- Querying
サブクエリ、マルチステップクエリ、ハイブリッドアプローチなど、様々なクエリ手法を活用し、LLMとデータ構造を選択したインデックス戦略に統合します。
- Evaluation
代替案や修正案に対するアプローチの有効性を測定し、レスポンスの正確さとスピードに関する客観的な指標を提供するため、どのパイプラインにおいても極めて重要です。
LlamaIndexを使用してRAGパイプラインを構築する方法
RAGの仕組みと段階は理解できましたか?
それでは実際に、LlamaIndexを使ってRAGパイプラインを構築し、大規模な言語モデルの評価にPhoenix Evalsを使ってみましょう。
OpenAIのキーをお持ちの方は、こちらのGoogle Colabをチェックして、このデモを使ってみてください。
ライブラリのインストール

インストールされたライブラリをインポートする
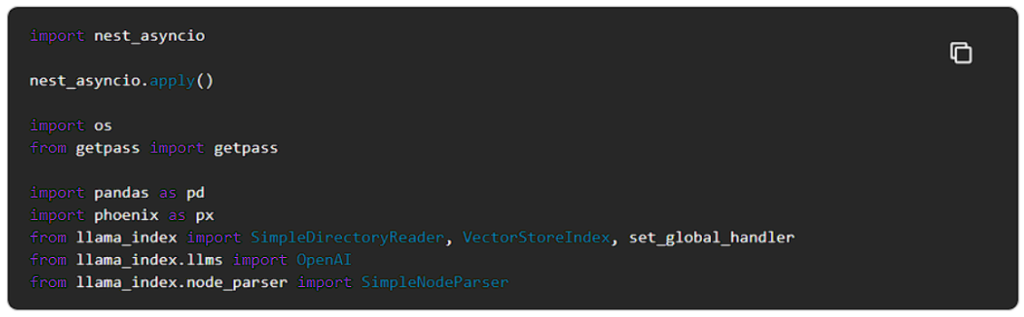
nest_asyncioモジュールは、すでに実行されている非同期ループの中に非同期関数を入れ子にすることができます。Jupyterノートブックは本質的に非同期ループで動作するため、これは必要です。nest_asyncioを適用することで、競合することなく、既存のループ内で追加の非同期関数を実行できます。
Phoenixアプリケーションの起動
この実装を通して、Phoenixトレースを使用してRAGパイプラインの評価に必要なすべてのデータを取得します。これを有効にするには、Phoenixアプリケーションを起動し、LlamaIndexを計測するだけです。

これは自分のインスタンスでサーバを実行しブラウザ上でLlamaIndexのset_global_handler(“arize_phoenix”)を使ってArize Phoenixにすべての情報を設定しています。
OpenAIは、合成データの作成や評価に使用する予定です。

インデックスのダウンロード、ロード、構築
ポール・グラハムのエッセイを使ってRAGパイプラインを構築して見ましょう。

LlamaIndexを使ってエッセイを解析し、chunk_sizeが512のドキュメントのチャンクを作り、それを埋め込みます。
次に、クエリを実行できるように、ローカルファイルをVectorStoreIndexとして保存します。
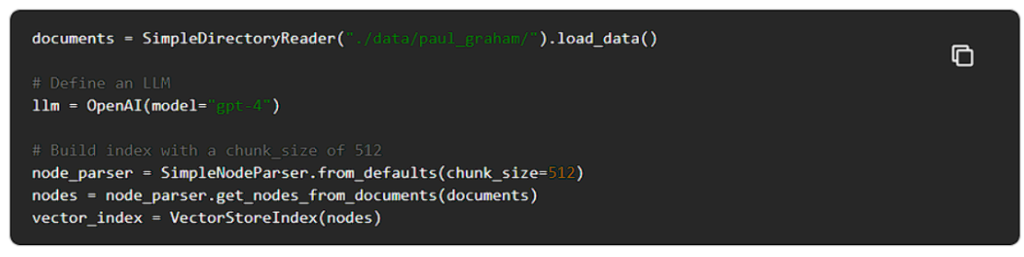
QueryEngineを構築し、クエリーを開始する

クエリーから得られるレスポンスをチェックし、それが私たちが探しているユースケースに合わせたものであることに気づくことができます。
『著者は短編小説を書き、プログラミングに取り組み、特に9年生の時にはIBM 1401コンピューターを使っていました。』
Phoenixサーバーに向かうと、クエリーとレスポンス、入力と出力が表示されます。
Phoenixは内部状態もトレースし、コサイン類似度、ドキュメントチャンク、メタデータを表示します。
しかし、LlamaIndexを使って1番目と2番目のtextnodesにあるテキストを取得したい場合は、以下のコードブロックを使うことができます。

get_span_dataframe()を使用して、Phoenixセッションからスパンを直接取得することで、トレースにアクセスすることができます。

ドキュメントのあるデータフレームに絞り込むことができます。

これで、RAGパイプラインを構築し、Phoenixを使って計測することができました。
次に、RAGのパフォーマンスを評価していきましょう。
RAGの評価
RAGアプリケーションの評価は、重要な指標として機能します。
様々なデータソースやクエリータイプを考慮し、パイプラインによって生成されたレスポンスの精度を評価します。
個々のクエリやレスポンスを分析することは価値がありますが、エッジケースや障害の数が増えるにつれて困難になります。より実用的なアプローチには、一連のメトリクスと自動化された評価の実装が含まれます。これらのツールは、システムの全体的なパフォーマンスに関する洞察を提供し、さらなる調査が必要な領域をピンポイントで特定することができます。
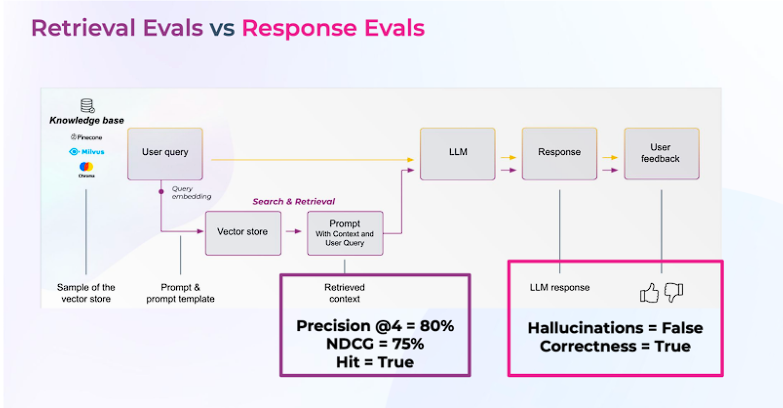
RAGシステム評価は、2つの重要な側面に焦点を当てています。これらをご紹介しましょう。
検索評価
検索された文書の正確性と関連性を評価する指標です。
- nDCG:ランキング上位の文書の効果を測定します。関連文書の位置を考慮します。
- ヒット率:関連するコンテキストを持つクエリの割合です。Hitはバイナリ指標(関連文書が検索されたか、されなかったか)を示しています。
- Precision@K:Precision(精度)=関連文書の割合。3件中1件が関連文書であれば、Precision@3 = 33%となります。
対応評価
コンテキストが提供されたときにシステムが生成した応答の適切性を測定します。LLMに根拠となる真実のラベルがない場合、以下の回答評価基準を使用して評価を行うことが可能です。
- 正確性:検索されたデータに基づいて、システムが質問に正しく回答したかどうか評価します。
- ハルシネーション:検索されたコンテキストに関連するLLMの幻覚(ハルシネーション)を検出します。
- 悪意性:回答が人種差別的、偏見的、または毒性的かどうかを識別します。
質問コンテキストのペアを生成する
RAGシステムの評価には、正しいコンテキストを取得し、適切なレスポンスを生成するクエリが不可欠です。
Phoenixのllm_generateを利用して、質問とコンテキストのペアを生成します。

文書チャンクができたので、LLMにチャンクごとに3つの質問を生成するよう促してみましょう。
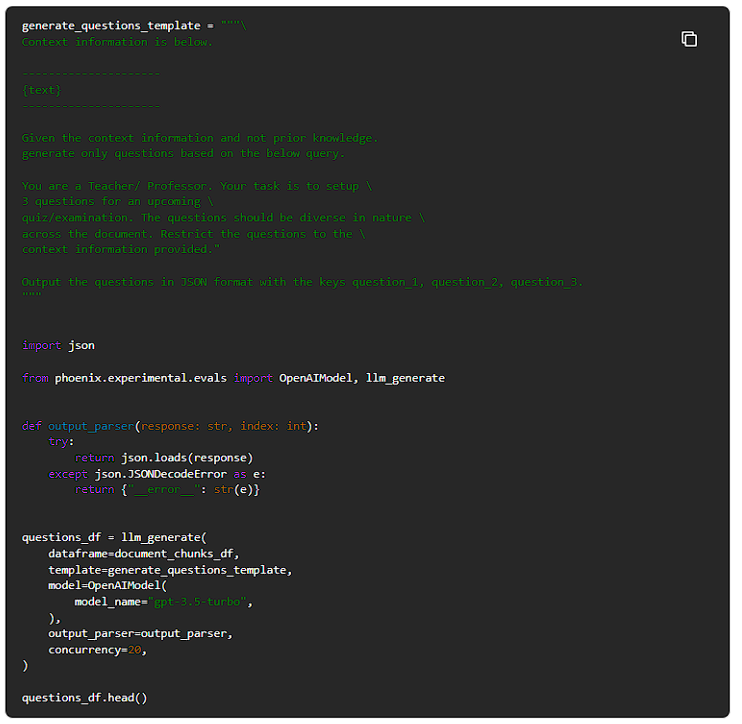
次に、質問とドキュメントチャンクのデータフレームを構築し、これらの質問をコンテキストと一緒にスタックします。
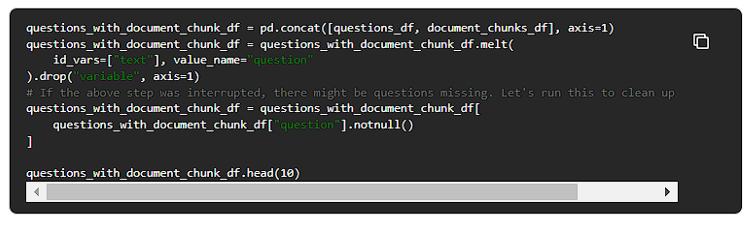
検索評価
前のステップで生成したクエリを実行し、正しいコンテキストが取得されたかどうかを検証します。しかし、最初に質問をループし、答えを生成します。

クエリを実行したので、RAGシステムが正しいコンテキストを取得できたかどうかの検証を開始します。
Phoenixに記録されたトレースから、get_retrieved_documents()を使って取得したドキュメントをすべて抽出してみましょう。

そこで、Phoenix LLM evalsを使って関連性評価を実行してみます。
ドキュメントのチャンクがユーザーの質問に関連しているかどうかを知るため、LLMがその理由を説明するように促す説明をONにしました。
これはデバッグや潜在的な修正アクションを見つけるのに役立ちます。
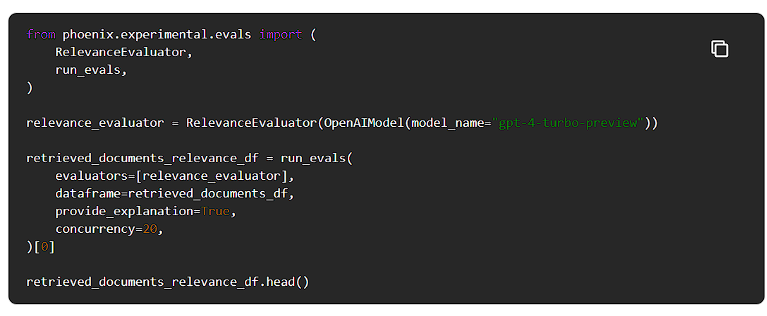
これで、文書と関連性評価を組み合わせて検索メトリクスを計算することができるようになりました。
RAGシステムのパフォーマンスを理解するのに役立ちます。

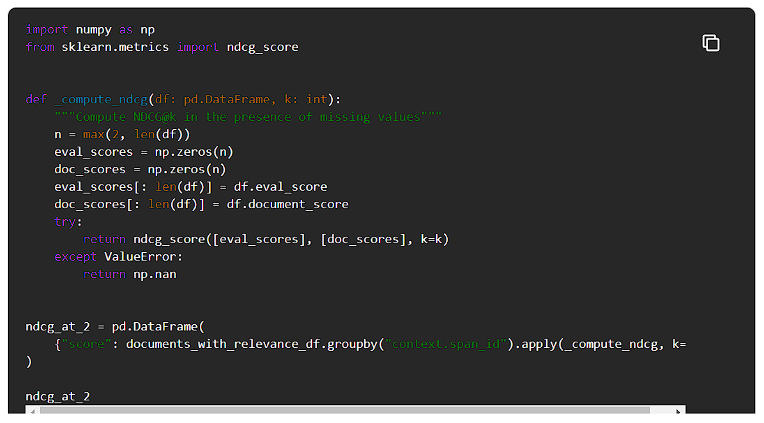
NCDGの計算
すべての検索ステップについて、正規化割引累積利得(NCDG)を2で計算してみましょう。
情報検索において、この指標はしばしば検索エンジンアルゴリズムや関連アプリケーションの有効性を測定するために使用されます。
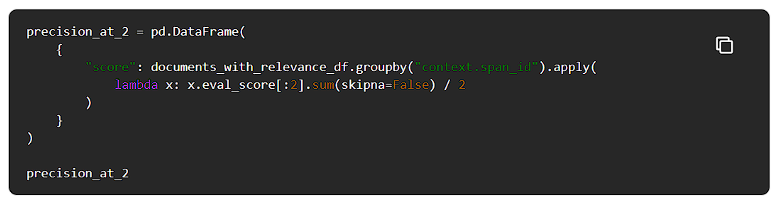
精度の計算
すべての検索ステップの精度を計算してみましょう。
ヒットの計算
最後に、各クエリに対して正しい文書がまったく検索されなかったかどうか(例えばヒットしたかどうか)を計算してみよう。

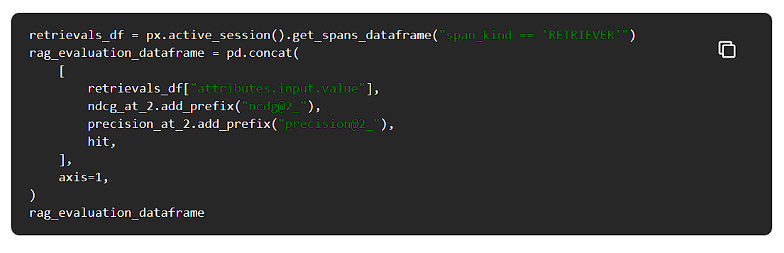
それでは、結果を結合したデータフレームで確認してみましょう。
スコアの集計
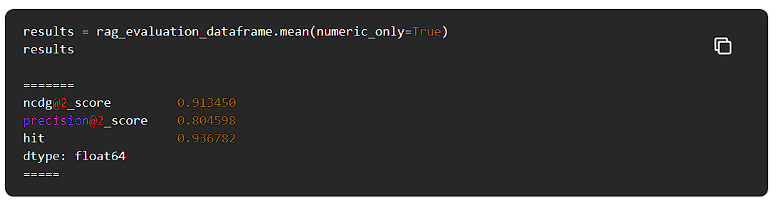
RAGシステムがどの程度機能しているかを知るために、結果を集計してみます。
Phoenixのログ評価
上記の数字から、私たちのRAGシステムは完璧ではなく、最初の2つのドキュメント内で正しいコンテキストを検索できないことがあります。
また、正しいコンテキストが上位2つの検索結果に含まれていても、関連性のない情報がコンテキストに含まれていることもあります。これは、検索戦略を改善する必要があることを示しています。
可能な解決策の一つは、検索される文書の数を増やし、より洗練されたランキング戦略(リランカーなど)を使って正しいコンテキストを選択することです。
これでRAGシステムの検索性能を評価することができました。
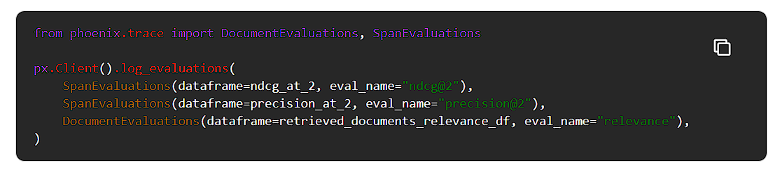
これらの評価をPhoenixに記録して視覚化してみましょう。
対応評価
この検索評価は、我々のRAGシステムが完全ではないことを示しています。しかし、LLMは文脈が正しくない場合でも正しい応答を生成できる可能性があります。
LLMが生成した応答を評価してみましょう。

質問、文脈、応答のデータセットができたので、LLMがどの程度クエリに応答しているかを測定することができます。
QAの正しさの評価の詳細については、LLM Evalsのドキュメントを参照してください。
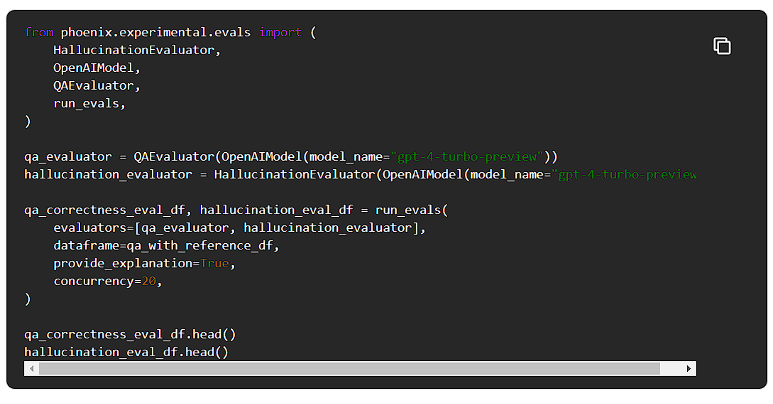
スコアの集計
それでは、この結果を集計して、LLMがどの程度の文脈で質問に答えているのか確認してみましょう。

QAの正答率は0.91、幻覚(ハルシネーション)率は0.05であり、生成された回答は91%の確率で正しく、5%の確率で幻覚が含まれていることになります。
Phoenixへの評価ログ
RAGシステムのQA性能と幻覚性能を評価したので、これらの評価をPhoenixに送って可視化します。

結論
この記事では、LlamaIndexとオープンソースのPhoenixを使ってRAGパイプラインを構築し、評価する方法を説明しました。
詳細については、LLM Evalsのドキュメントを参照してください。
また、意見や感想があれば、お気軽にArizeコミュニティまでご連絡ください。