この記事は、Arize AIの創業エンジニア兼オープンソース責任者であるMikyo Kingと、Arize AIのAIエンジニアであるXander Songの共著です。
通常、RAGパイプラインのベースラインを構築することは難しくありません。
しかし、それを本番環境に適したものに強化し、回答の質を確保することは、ほとんどの場合難しいです。
RAGのための適切なツールやパラメータを選択することは、豊富なオプションがある場合、それ自体が困難な場合があります。
今回は、品質を確保しながらRAGを構築し、正しい選択が行えるようになるための強固なワークフローをご紹介します。
この記事では、以下のようなオープンソースのライブラリを組み合わせてRAGを評価、視覚化、分析する方法について説明します。
- ・合成テストデータの生成と評価のためのRagas
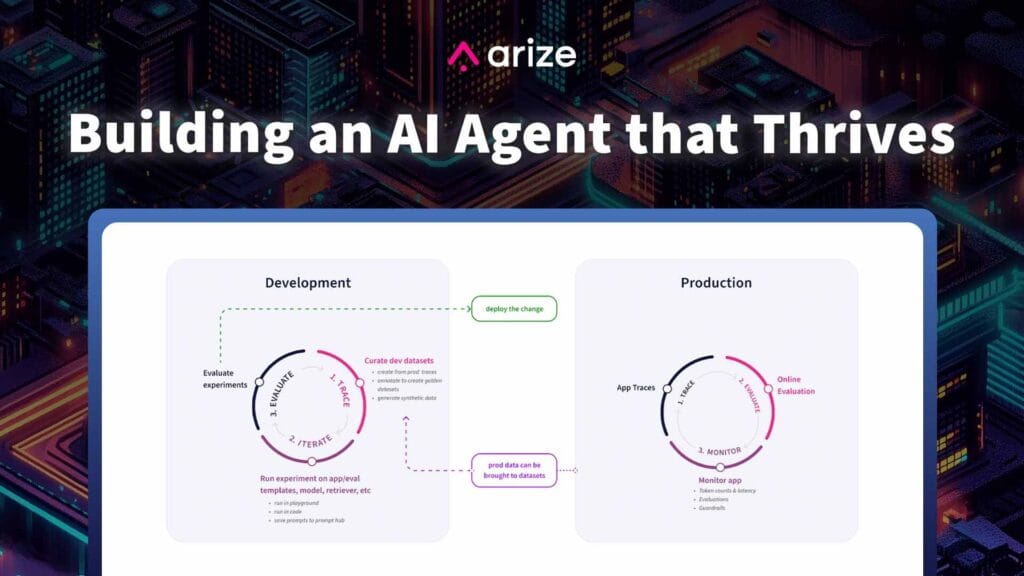
- Arize AIのPhoenix(トレース、可視化、クラスター分析用)
- RAGパイプライン構築のためのLlamaIndex
この記事では、RAGパイプラインを構築するために、プロンプト・エンジニアリングに関するarXiv論文のデータを使用します。
ℹ️ この記事では、OpenAIのAPIキーが必要となるので準備してください。
依存関係のインストールとライブラリのインポート
以下を実行して、Git LFSをインストールしてください。

Pythonの依存関係をインストールしてインポートします。
OpenAI API キーを設定する
OpenAI API キーが環境変数に設定されていない場合は、設定します。
合成テスト・データセットの作成
評価のためのテストデータセットの作成は、現実的ではない、長く、退屈で、高価なプロセスである可能性があります。
これは、高品質のデータ・ポイントを合成的に生成し、開発者が検証することで解決できます。これにより、テスト・データの収集にかかる時間と労力を90%削減することができます。
以下を実行すると、arXivからPDF形式のプロンプト・エンジニアリング論文のデータセットをダウンロードし、LlamaIndexを使ってこれらの文書を読むことができます。
理想的なテストデータセットは、本番中に観測されたものと同様の分布から、高品質で多様な性質を持つデータポイントを含むべきです。Ragasはユニークな進化ベースの合成データ生成パラダイムを使用し、最高品質の問題を生成します。
RagasはデフォルトでOpenAIのモデルを使用していますが、お好きなモデルを自由に使用することができます。Ragasを使って100点のデータを生成してみましょう。
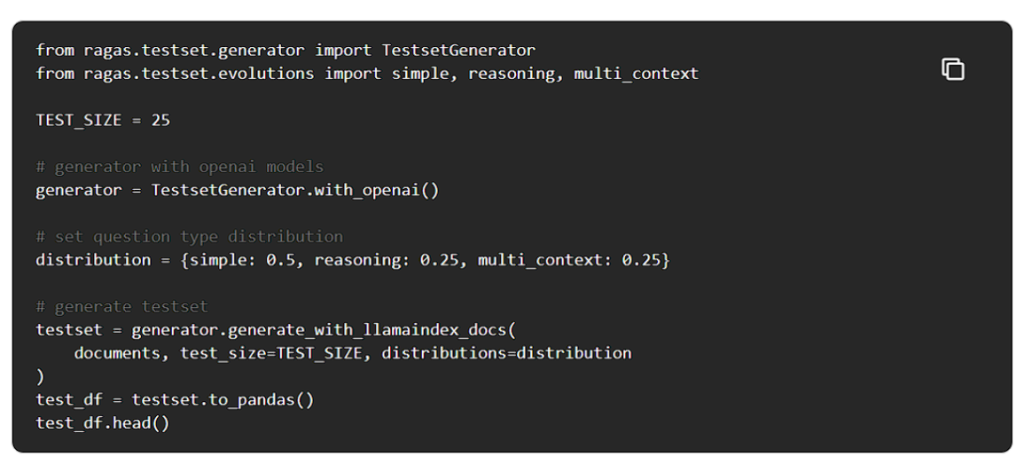
質問タイプの分布は、必要に応じて自由に変更してください。テストデータセットの準備ができたので、次にLlamaIndexを使用して簡単なRAGパイプラインを構築しましょう。
LlamaIndexでRAGアプリケーションを構築する
LlamaIndexは、RAGアプリケーションを構築するための使いやすく柔軟なフレームワークです。
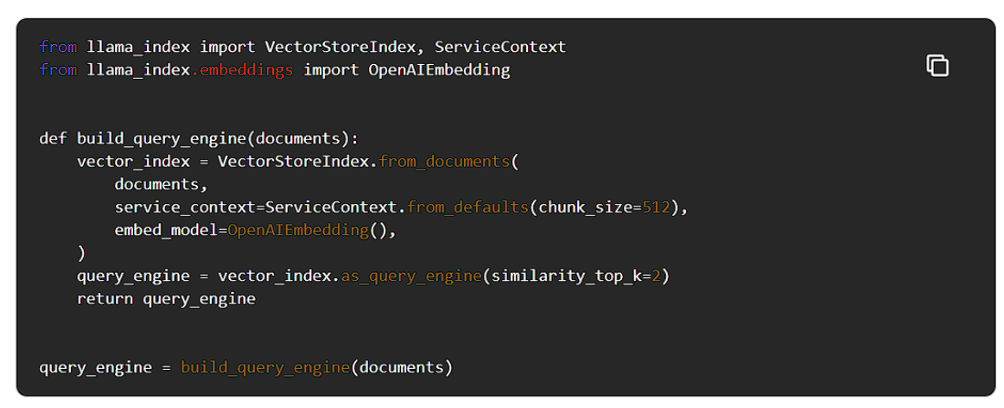
今回は簡単に構築するため、デフォルトのLLM(gpt-3.5-turbo)とエンベッディングモデル(openai-ada-2)を使用して進めていきます。
Phoenixをバックグラウンドで起動し、OpenInferenceのスパンとトレースがPhoenixに送信され、Phoenixによって収集されるように、LlamaIndexアプリケーションをインスツルメンテーションします。OpenInferenceはOpenTelemetryの上に構築されたオープンスタンダードで、LLMアプリケーションの実行をキャプチャして保存します。これは、LLMの実行や、ベクターストアからの検索、検索エンジンやAPIなどの外部ツールの使用など、周囲のアプリケーションコンテキストを理解するために使用されるテレメトリーデータのカテゴリとして設計されています。

クエリーエンジンを構築します。
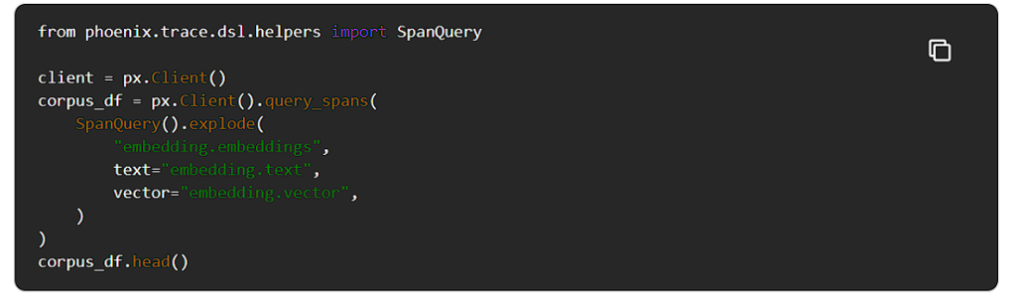
Phoenixをチェックすると、コーパスデータがインデックスされた時からの埋め込みスパンが表示されるはずです。
後でノートブックで可視化するために、これらの埋め込みデータをデータフレームにエクスポートして保存します。
Phoenixを再起動して、蓄積された痕跡を消去します。

LLM申請書の評価
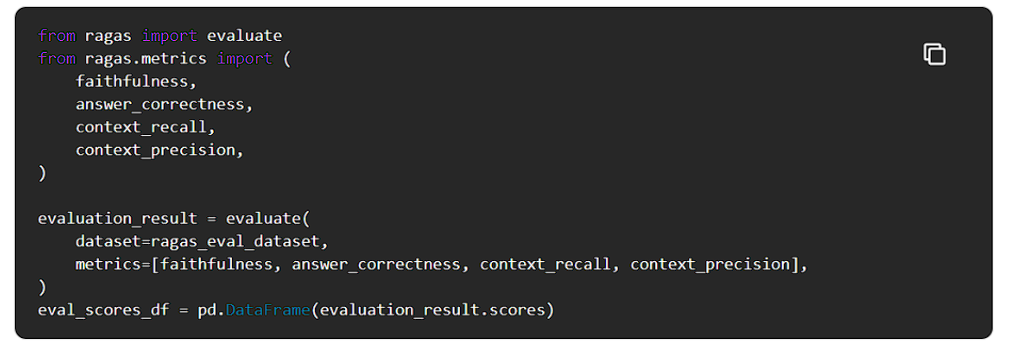
RagasはRAGパイプラインをコンポーネント単位とエンドツーエンドの両方で評価するために使用できるメトリクスの包括的なリストを提供します。
Ragasを使用するために、まず生成された質問と回答、取得されたコンテキスト、およびグランドトゥルースの答え(与えられた質問に対する実際に期待される答え)からなる評価データセットを形成します。
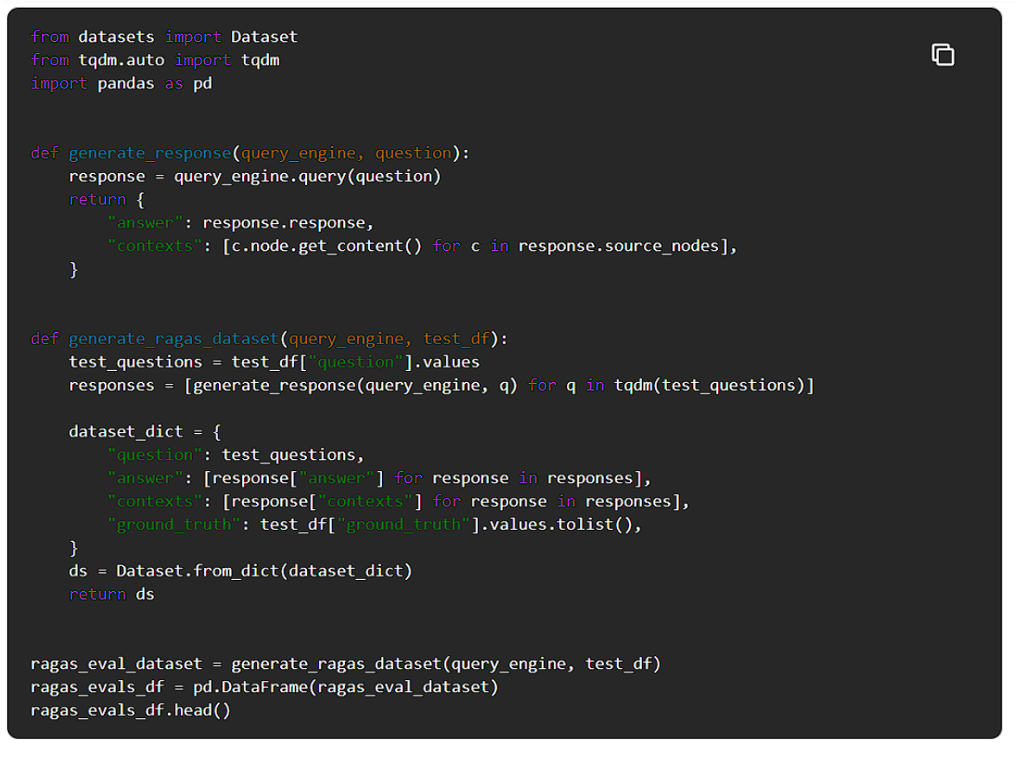
Phoenixをチェックして、LlamaIndexアプリケーションのトレースを表示しましょう。

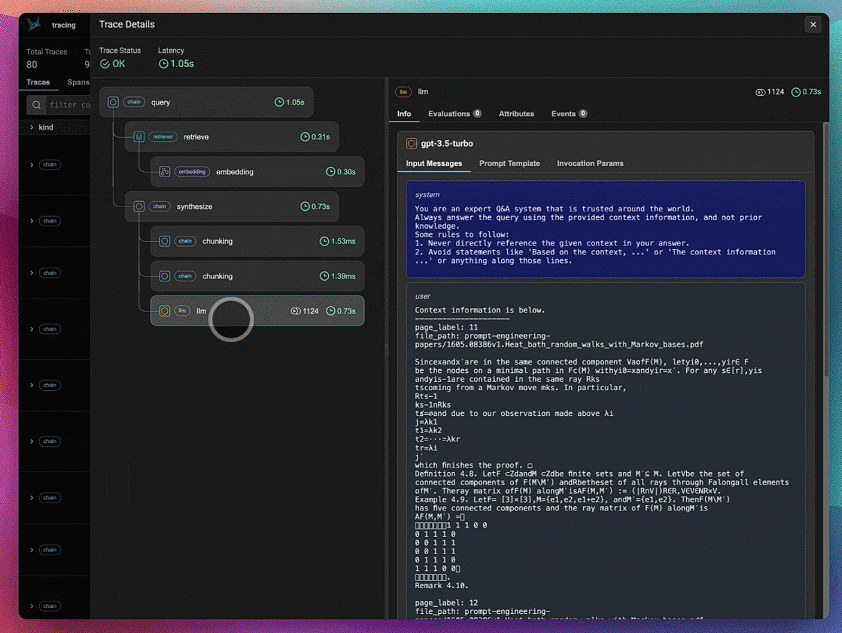
1つは後で可視化する埋め込みデータ、もう1つはRagasを使って評価する予定のトレースとスパンをエクスポートしたものです。
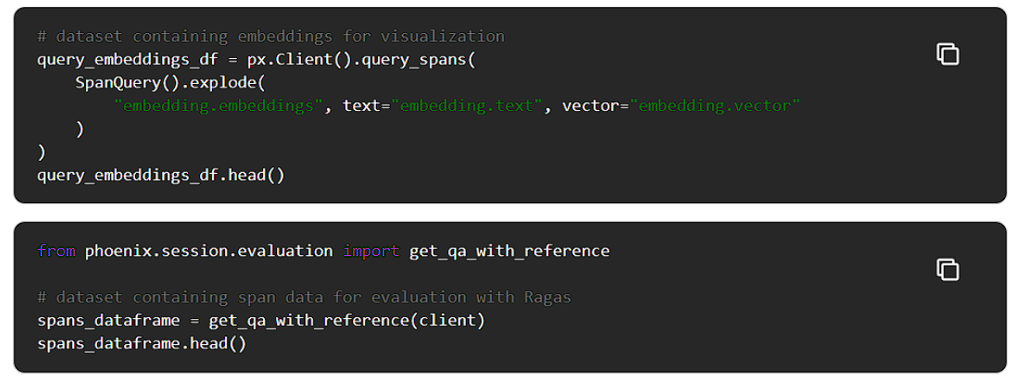
RagasはLangChainを使ってLLMアプリケーションのデータを評価します。LangChainをOpenInferenceで計測して、LLMアプリケーションを評価するときに何が起こっているのか見てみよう。

LLMの軌跡を評価し、評価スコアをデータフレーム形式で表示します。
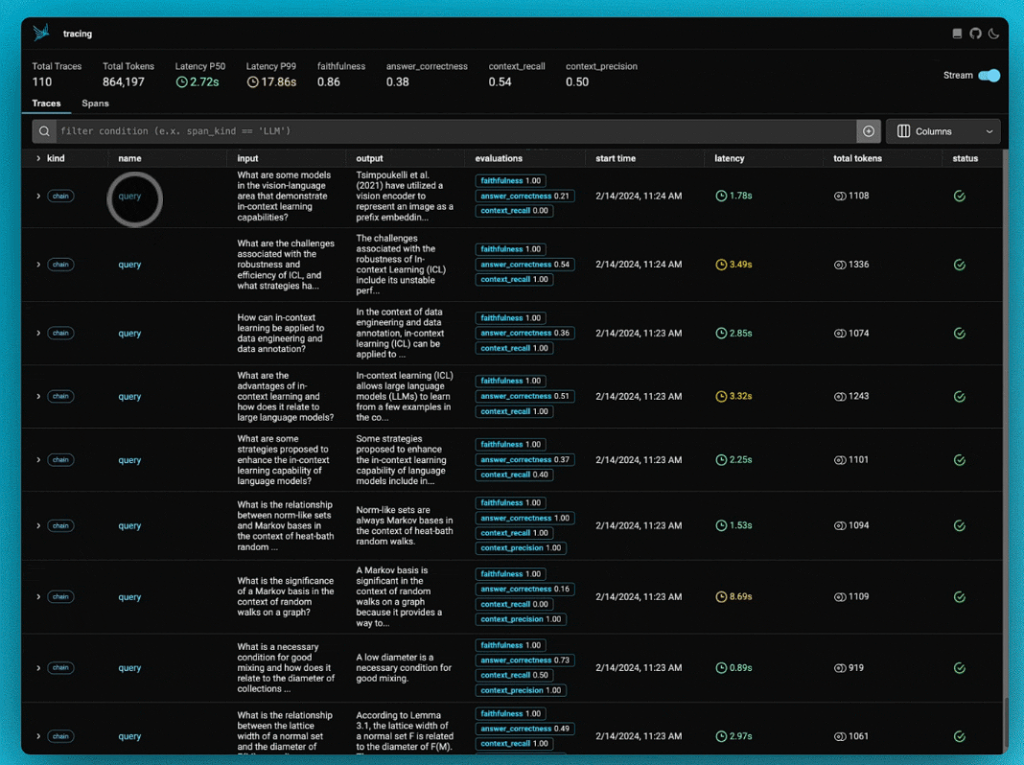
評価をPhoenixに連携すると、スパン上の注釈として表示されます。
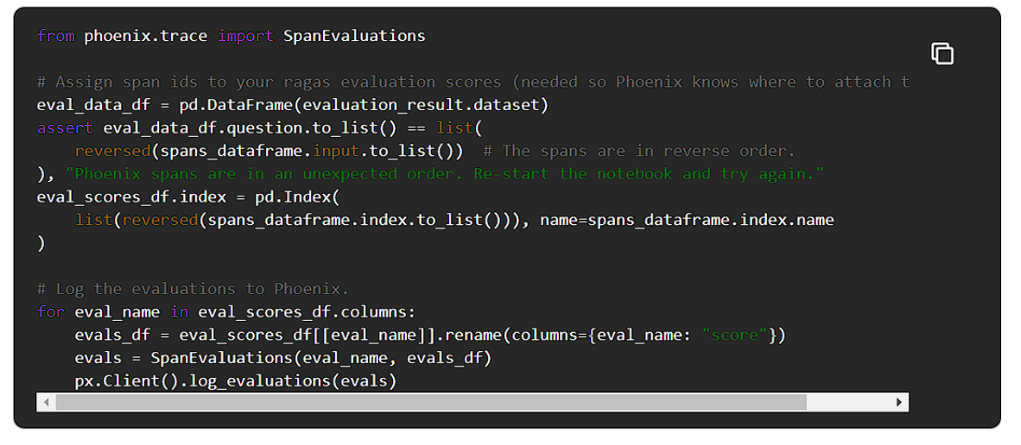
Phoenixをチェックアウトすると、Ragasの評価がアプリケーションスパンの注釈として表示されます。

エンベッディングの可視化と分析
エンベッディングは、検索された文書やユーザークエリの意味をエンコードします。
エンベッディングはRAGシステムにとって不可欠な要素であるだけでなく、LLMアプリケーションのパフォーマンスを理解し、デバッグするために非常に有用です。
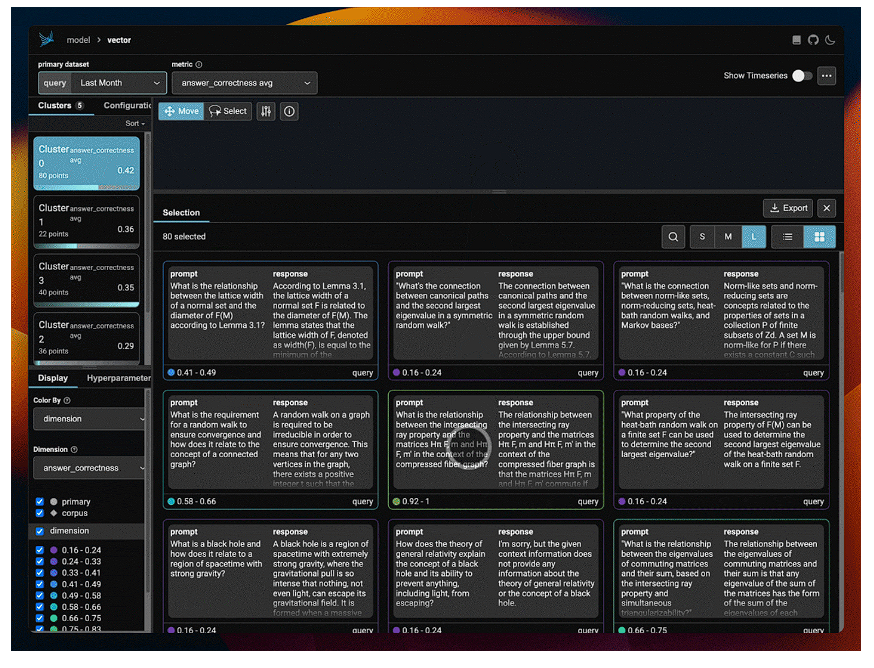
Phoenixは、RAGアプリケーションから高次元の埋め込みデータを取り出し、その次元を減らし意味を持つデータ群にクラスタ化します。その後、アプリケーションのパフォーマンスを視覚的に検査し、問題のあるクラスタを表面化するために、任意のメトリック(例えば、Ragas-computed faithfulnessまたはanswer correctness)を選択することができます。
このアプローチの利点は、データセット全体のパフォーマンスを単にグローバルに分析するだけでなく、ローカルに分析するのに役立つ、データの粒度が細かく、かつ意味のあるサブセットに関するメトリクスを提供することです。また、LLMアプリケーションがどのようなクエリに苦戦しているのかを直感的に把握するのにも役立ちます。
Phoenixをエンベッディングビジュアライザーとして再度起動し、テストデータセット上でのアプリケーションのパフォーマンスを検査します。
Phoenixを起動したら、任意の指標を用いてデータを可視化することができます。以下の手順で行うことができます。
- ベクトル埋め込みを選択します。
- Color By > dimension を選択し、次に選択したディメンションを選択します。
特定のフィールド、例えば忠実度や解答の正しさなどのRagas評価スコアでデータを色分けすることができます。 - クラスタごとの集計メトリクスを表示するには、メトリクスのドロップダウンから希望のメトリクスを選択します。
総括
おめでとうございます!
あなたはRagasとPhoenixを使ってLlamaIndexクエリー・エンジンを構築し、評価しました。最後に復習しましょう。
Ragasでは、LlamaIndexクエリーエンジンを評価するために、テストデータセットをBootstrapし、忠実度や正答率などのメトリクスを計算しました。
OpenInferenceでは、LlamaIndexとRagasの両方の内部動作を観察できるように、クエリーエンジンを計測しました。
Phoenixでは、スパンやトレースを収集し、評価をインポートして簡単に検査できるようにし、埋め込みクエリや検索されたドキュメントを視覚化することで、パフォーマンスが低下している箇所を特定しました。
今回の記事は、RagasとPhoenixの機能の紹介に過ぎません。
もっと詳しく知りたい方はRagasとPhoenixのドキュメントをご覧ください。
このチュートリアルを楽しんでいただけたら、ぜひGitHubに ⭐ をつけてください。