RAGシステムの新しい評価手法が毎日のように発表されていますが、そのほとんどがフレームワークの検索段階に焦点を当てています。Arizeは、テストの詳細な分析を含む、検索段階に関するいくつかの記事を発表しました。
しかし、生成の側面、つまりモデルが検索された情報をどのように合成し、表現するかという点において、より重要ではないにしても、同等の重要性を持つかもしれません。
私たちが実運用で目にする多くのユースケースは、単にコンテキストから回答を返すだけでなく、より複雑なレスポンスに合成する必要があります。
数値データを物語的な分析に変換するのか、抽象的な概念を具体的な例に変換するのか、あるいは異種の情報の断片を統合するのかにかかわらず、生成プロセスは、RAGシステムの機能にとっては必要不可欠です。
私たちはGPT-4、Claude 2.1、Claude 3.0 Opusの生成機能を評価し、比較するためにいくつかの実験を行いました。
この記事では、私たちの研究方法と結果、そしてその過程で遭遇したモデルのニュアンスについて詳しく解説していきます。
研究で得たもの
- 最初の結果では、Claude がGPT-4を上回りました。しかし、その後のテストでは、戦略的なプロンプトエンジニアリングにより、GPT-4がより幅広い評価で優れたパフォーマンスを示したことが明らかになりました。RAGシステムでは、固有のモデル動作とプロンプトエンジニアリングが非常に重要であるといえます。
- プロンプトに 「Please explain yourself then answer the question(説明してから質問に答えてください)」と加えるだけで、GPT-4のパフォーマンスは大幅に(2倍以上)改善します。LLMが答えを話し出すと、アイデアを展開するのに役立つことは明らかです。モデルが説明することで、埋め込み/注意空間において正しい答えを再強化している可能性があります。
- RAGシステムの成功には、検索と同じかそれ以上に、生成ステップが重要です。
RAGの段階と生成が重要な理由
RAGシステムにおける最近の研究の多くが検索段階に向けられていることは、膨大な知識ベースから関連する情報を探し出し、抽出することの重要性を考えれば理解できます。
しかし、これらのシステムの全体的なパフォーマンスとユーザビリティにおいて同様に重要な役割を果たす、生成段階の重要性を見落としてはなりません。
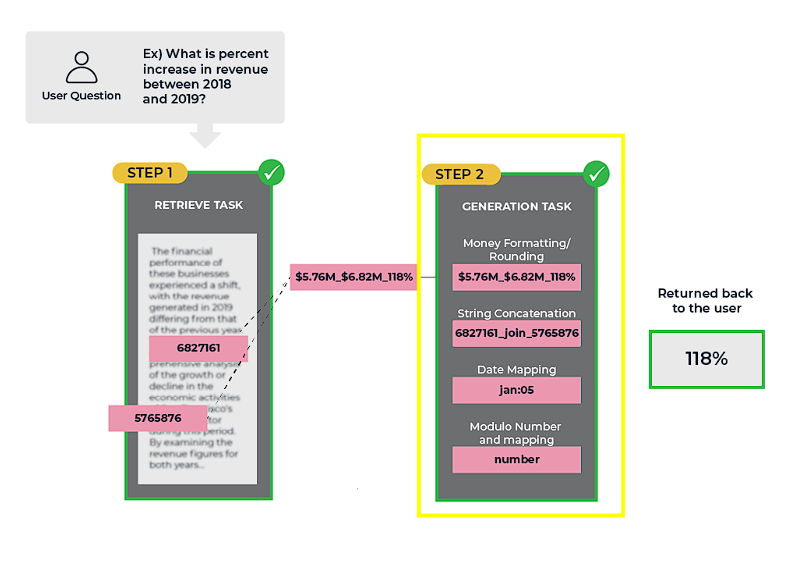
検索段階は、最も適切な情報を特定し、検索する役割を担っています。ここで生のデータを受け取り、意味のある、文脈上適切な回答に変換するのは生成段階です。生成段階は、検索された情報を合成し、ギャップを埋め、ユーザーのクエリに関連する、理解しやすい方法で提示する役割があります。
多くのアプリケーションにおけるRAGシステムの価値は、特定の事実や情報の一部を見つける能力だけでなく、より広い枠組みの中でその情報を統合し、文脈化する能力にあります。生成段階では、RAGシステムが単純な検索を超え、詳細な説明を提供したり、複数の情報源に基づいた洞察を提供したり、複雑な問題に対する創造的な解決策を生成したりするなど、真にインテリジェントで適応性のある応答を提供することを可能にします。
テストその1:日付のマッピング
最初のテストでは、ランダムに取得した2つの数字から日付文字列を生成しました。モデルには次のようなタスクを課しました。
- 1つ目の乱数取得
- 下一桁を分離して1ずつ増やす
- 結果から日付文字列の月を生成する
- 2つ目の乱数取得
- 2つ目の乱数から、日付文字列の曜日を生成する
例えば、乱数4827143と17は4月17日を表します。
これらの数字は、さまざまな長さのコンテクスト内のさまざまな深さに配置されました。モデルたちは当初、このタスクにかなり苦労していました。
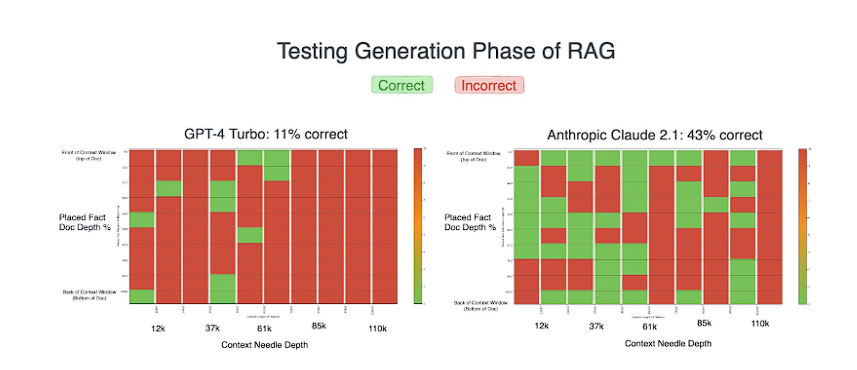
どちらのモデルも素晴らしいパフォーマンスを見せましたが、Claude 2.1 は最初のテストで GPT-4 を大きく上回り、成功率はほぼ4倍になりました。
これは Claude の冗長な性質(詳細で説明的な回答をする性質)が、GPT-4の最初の簡潔な回答と比較して、より正確な結果をもたらし、明確な優位性を与えたようです。
この予想外の結果に促されて、私たちは実験に新しい変数を導入しました。
GPT-4に「自分自身を説明してから質問に答えよ」と指示し、Claudeの自然な出力に似た『より冗長な回答』を促しました。この些細な調整の影響は大きかったです。
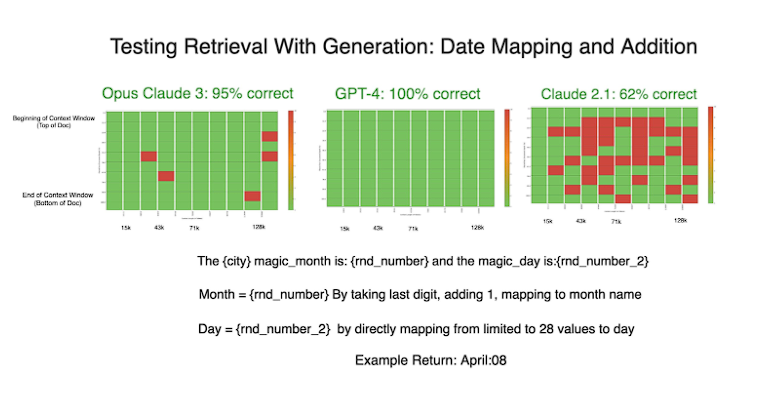
GPT-4のパフォーマンスは劇的に向上し、その後のテストでは完璧な結果を残したのです。Claudeの結果もまた、わずかですが向上しました。
この実験は、言語モデルの生成タスクへの取り組み方の違いを浮き彫りにしただけでなく、プロンプトエンジニアリングがその性能に与える潜在的な影響も示しています。
Claudeの長所と思われた冗長性は、GPT-4で再現可能な戦略であることが判明し、モデルが推論を処理し提示する方法が、生成タスクにおける精度に大きく影響することを示唆しています。
全体として、プロンプトに「自分自身を説明する」という一見とても小さなことかと思いますが、すべての実験においてモデルのパフォーマンスを向上させる役割を果たしました。
検索生成タスクのさらなるテスト

さらに4つのテストを実施し、検索された情報を合成し、さまざまな形式に変換するモデルの能力を評価しました。これらのテストには以下が含まれます。
- 文字列の連結: テキストの断片を組み合わせて首尾一貫した文字列を形成し、モデルの基本的なテキスト操作スキルをテストする。
- お金の書式設定: 通貨として数値をフォーマットし、四捨五入し、パーセンテージの変化を計算し、モデルの精度と数値データを扱う能力を評価する。
- 日付のマッピング: 数値表現を月名と日付に変換し、検索と文脈理解の融合を必要とする。
- モジュロ算術: モデルの数学的生成能力をテストするために複雑な数値演算を行う。
どのモデルも文字列連結で高い性能を示し、テキスト操作が大規模言語モデルの基本的な強みであるというこれまでの理解を再確認しました。
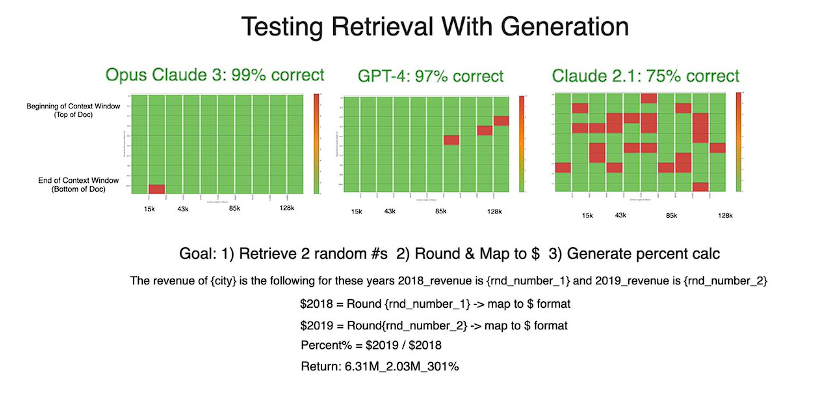
Claude 3とGPT-4は、お金の書式設定テストでほぼ完璧な性能を発揮しました。
一方、Claude2.1の成績は全体的に悪かったです。精度はトークンの長さによって大きく変わることはありませんでしたが、文脈の先頭に近いほど精度が下がりました。
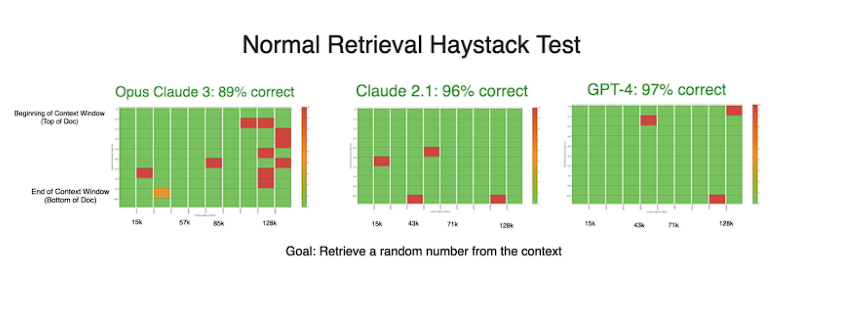
生成テストでは素晴らしい結果を残したにもかかわらず、Claude3の精度は検索のみの実験で低下しました。
理論的には、数字を操作するよりも、単に数字を検索する方が簡単なはずです。この結果は、私たちのプロセスに何か間違いがあるのではないかと思わせるほど奇妙なもので、私たちはさらなるテストを計画しています。
この直感に反する落ち込みは、RAGで開発する際には検索と生成の両方をテストすべきであるという考えをさらに裏付けるものです。
分析
さまざまな生成タスクをテストすることで、どちらのモデルも文字列操作のような単純なタスクには優れていますが、より複雑なシナリオではそれぞれの長所と短所が明らかになることが観察されました。
LLMはやはり数学が苦手なのです!
もう一つの重要な結果は「explain yourself(自分自身を説明してください)」というプロンプトを導入することで、GPT-4のパフォーマンスが顕著に向上したことです。
これは、正確な結果を得るためには、モデルがどのようにプロンプトを表示し、どのように推論を明確にするかが重要であることを強調しています。
これらの発見は、LLMの評価にとってより広い意味を持ちます。
饒舌なClaudeと、当初は饒舌でなかったGPT-4のようなモデルを比較した場合、評価基準は単なる正しさだけにとどまらないことが明らかになりました。
モデルの応答が冗長であるかどうかは、モデルの性能評価に大きな影響を与える可能性があります。
このニュアンスは、今後のモデル評価では、回答の平均長さを注目すべき要素として考慮すべきであり、モデルの能力をよりよく理解し、より公平な比較を保証することを示唆しています。
全体としてRAGの生成ステップは検索よりも注目されていませんが、同様に重要であるといえます。
単純なプロンプトエンジニアリングとモデルのニュアンスが、RAGのパフォーマンスに大きな違いをもたらす可能性があり、これらのシステムを構築する際には、厳密なテストと特定のユースケースに基づいた選択が必要であると、私たちは結論づけました。