アンバー・ロバーツ 機械学習エンジニア | 一月, 2024
検索と取得のユースケースを最大限に活用するために必要なステップを理解する
特定のビジネスニーズに合わせてカスタマイズされたチャットボットを作成するには、独自のナレッジベースを活用する必要があります。
検索拡張生成(RAG)を使用すると、チャットボットは独自のドキュメントから情報を組み込むことによって、その理解を強化することができます。
大規模言語モデル(LLM)によって生成されたコンテンツは、外部ソースから取得された関連資料を追加することによって、強化または増強されます。RAGの主な強みはそのデータ検索方法であり、LLMにコンテンツ生成プロセスを大幅に豊かにする追加コンテキストを提供します。
RAGロードマップは、データ検索から回答生成まで、RAGを支える複雑なプロセスの明確な道筋を示しています。
今回は、これらのステップを詳しくご紹介し、RAGのオンラインとオフラインのモードの違いを検証していきます。
RAGロードマップの旅は、技術的な側面に焦点を当てるだけでなく、検索および検索結果を評価する最も効果的な方法を示します。
LLM RAGを使う前に知っておくべきこと
どのようなロードマップでもそうですが、まず自分がどこへ向かっているのか、そしてどのようにそこへ向かっていくのかを知る必要があります。
RAGを使っているのであれば、以下ようなことを覚えておくと役に立ちます。
- コストとリスクを削減しようとし、パフォーマンスを最適化しようとしている。
- 独自のデータを使用している。使用しているLLMアプリケーションが応答を生成するために安全なデータを必要としない場合、LLMに直接プロンプトを表示し、追加のツールやエージェントを使用して応答を適切なものに保つことができる。
- プロンプトエンジニアリングの初心者である。LLMから最適な出力を得るために、プロンプトテンプレートとプロンプトエンジニアリングを試す。ただし、プロンプトはユーザーのクエリに追加のコンテキストを追加するものではない。
- LLMの微調整 LLMに明示的な例を提供することで、特定のタスクをよりうまくこなせるようにモデルを微調整する。ファインチューニングは、プロンプトエンジニアリングによるパフォーマンス改善やRAGによる関連コンテンツの追加を実験した後に行うのがベター。これは反復のスピードとコストに起因しており、検索インデックスを最新の状態に保つことは、LLMを継続的に微調整し再トレーニングするよりも効率的である。
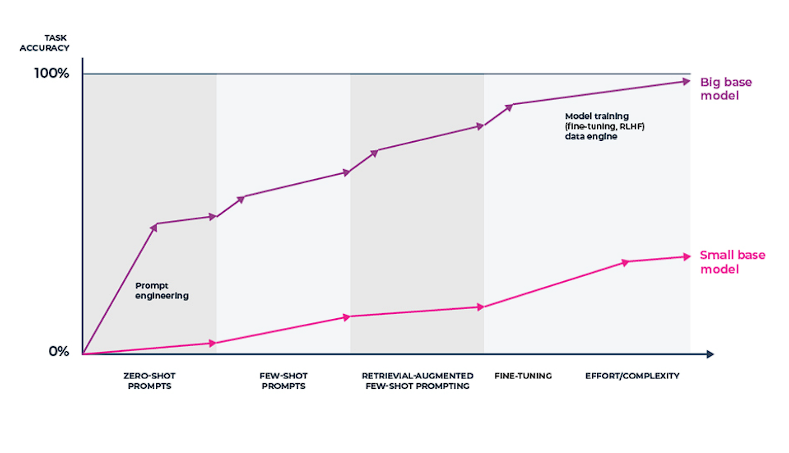
RAGシステムを構築している場合、検索された関連知識がクエリ応答における事実性を高め、モデルのハルシネーションを減らすことを期待して、LLMアプリケーションシステムに最近の新しい知識を追加していることになります。
LLM RAGの主な構成要素とは?
RAG(検索拡張生成)は、生成AIの強みと検索エンジンの機能を融合させた複雑なシステムのことです。
RAGを完全に理解するためには、その主要なコンポーネントを分解し、それらがシームレスなAIエクスペリエンスを生み出すためにどのように機能するのかを知ることが必要不可欠です。
RAGの主要な構成要素をいくつかご紹介します。
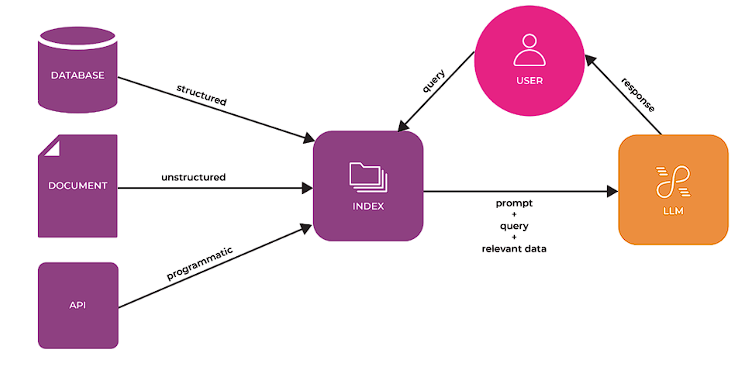
- 検索エンジン
これはRAGプロセスの最初のステップです。膨大な情報のDBから、入力されたクエリに対応する関連データを検索します。このエンジンは高度なアルゴリズムを使用して、検索されたデータが最も関連性が高く、最新のものであることを保証します。 - オーグメンテーション・エンジン
関連データが検索されると、オーグメンテーション・エンジンの出番です。検索されたデータを入力クエリと統合し、コンテキストを強化し、回答を生成するためのより多くの情報を提供します。 - ジェネレーション・エンジン
ここで実際のレスポンスが生成されます。増強された入力を使用して、生成エンジン(通常は高度な言語モデル)は、首尾一貫した、文脈に関連したレスポンスを作成します。このレスポンスは、モデルの既存の知識に基づくだけでなく、検索エンジンによってソースされた外部データによって強化されます。
RAGロードマップ
LLM RAGシステムが、入手可能な最新かつ関連性の高い情報に基づいて正確な回答を提供することを保証するにはどうすればよいでしょう?
RAGのプロセスは一連のステップとみなすことができ、それぞれが最終的なアウトプットに貢献します。
以下は、ステップ・バイ・ステップのRAGロードマップです。
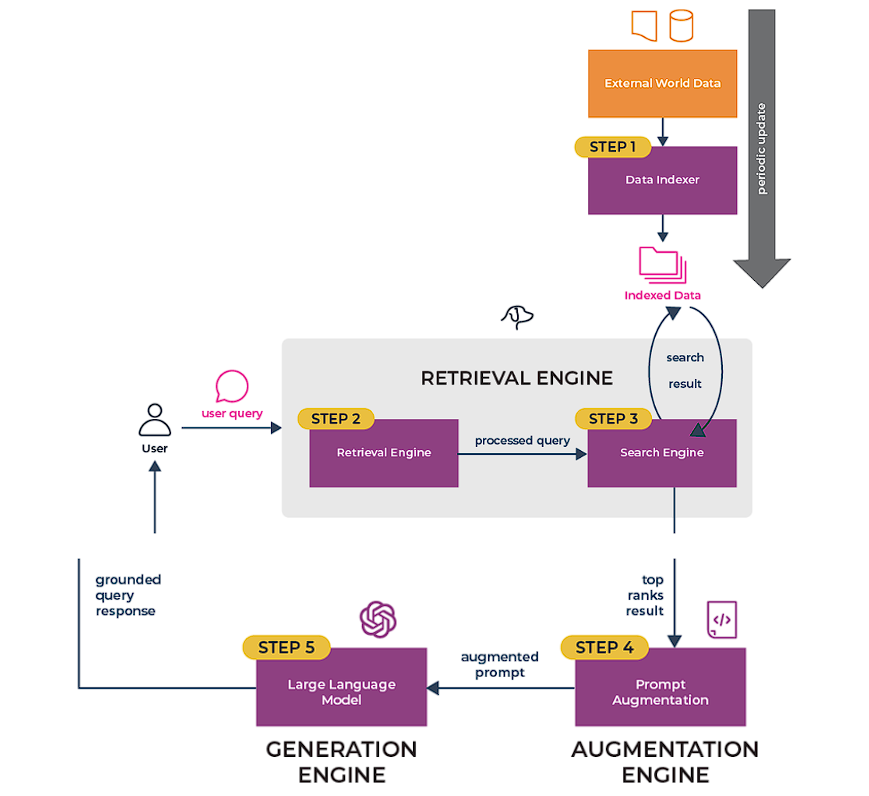
正確性と妥当性を確保するため、RAGには6つの段階があり、それは順次より大規模なRAGの一部となります。
- データのインデックス化
RAGが情報を検索する前に、データはインデックスに集約され、整理されなければなりません。このインデックスは検索エンジンの参照点として機能します。 - 入力クエリー処理
ユーザーの入力はシステムによって処理・理解され、検索エンジンの検索クエリの基礎となります。 - 検索とランキング
検索エンジンはインデックスされたデータを検索し、入力クエリとの関連性の観点から結果をランク付けします。 - 迅速な補強
最も関連性の高い情報を元のクエリと組み合わせます。この拡張されたプロンプトは、応答生成のための豊富なソースとして機能します。 - レスポンス生成
最後に、生成エンジンはこの拡張されたプロンプトを使用して、情報に基づいた文脈に正確なレスポンスを作成します。 - 評価
どのようなパイプラインでも重要なステップは、他のストラテジーとの相対的な効果や、変更を加えたときの効果をチェックすることです。評価では、応答の正確さ、忠実さ、スピードについて客観的な尺度を提供します。
これらのステップに従うことで、RAGシステムは正確なだけでなく、利用可能な最新の関連情報を反映した回答を提供することができます。このプロセスは、オンラインとオフラインの両方のモードに適応可能であり、それぞれに独自の用途と利点があります。
RAG(検索拡張生成)の応用例
RAGの実用的なアプリケーションを理解するために応用例を挙げましょう。
プライベートな知識ベースを照会するように設計されたチャットボットにRAGが採用されている、というシナリオです。

シナリオ カスタマーサービスにおけるAIチャットボット
大手電機メーカーのカスタマーサービス用チャットボットを想像してみてください。このチャットボットには、顧客からの問い合わせをより効果的に処理するためのRAGシステムが搭載されています。
以下のような処理を行います。
- 顧客からの問い合わせ処理
顧客が「スマートウォッチシリーズの最新アップデートは何ですか」などの質問をすると、チャットボットはこの入力を処理してクエリのコンテキストを理解します。
- ナレッジベースからの検索
検索エンジンは、最新のスマートウォッチのアップデートに関連する情報を、会社の最新の製品データベースから検索します。 - クエリの補足
検索されたスマートウォッチのアップデートに関する情報は、元のクエリと組み合わされ、チャットボットの応答のコンテキストを強化します。 - 情報に基づいた応答の生成
チャットボットは、RAGの生成エンジンを使用して、内部の知識ベースに基づいて質問に答えるだけでなく、新機能や価格など、取得した最新情報を含む応答を作成します。
このシナリオは、RAGがカスタマーサービスにおけるAIの有効性をいかに高め、正確かつ最新の回答を提供できるかを示しています。
RAGを統合することで、チャットボットは最初のプログラミングには含まれていないような情報を提供できるようになり、理想的にはユーザーのニーズにより敏感に反応できるようになります。
検索機能と生成AIをシームレスに統合することで、RAGシステムは従来の言語モデルとは比較にならないレベルの応答性と精度を提供可能になります。
RAGの重要性は、リアルタイムの外部ソースデータでAIの応答を強化し、AIのインタラクションをより適切で情報に基づいたものにする能力にあります。
これは、カスタマーサービス・チャットボットの改善から、複雑な調査やデータ分析作業の支援まで、様々な分野にわたって大きな意味を持ちます。
さて、もしあなたがこのロードマップを、他の人たちのためにも再現可能にしたいと思ったとします。
そんな場合は、LLMの観測可能性が活用できます。
スタート
Arize-Phoenixは、AIの可観測性と大規模言語モデル評価のためのオープンソースソリューションです!ぜひお試しください!