Ichizoku is on a mission to help Japan companies adopt AI faster and with greater success. An extremely important, but often overlooked, practice is LLM Observability. This is why we partnered with Arize AI.
Many companies are racing to deploy LLMs, but few have a good answer to the question, “How do you know if your LLM is performing well?” “How are you measuring success?” Aparna Dhinakaran, Co-Founder of Arize AI, in the below article discusses gaining comprehensive insight into every aspect of a software system that utilizes large language models (LLMs). The need for observability stems from the inherent complexities and challenges associated with bringing LLMs to production and keeping there performance at a high level. Issues such as hallucination, response quality, cost, and the complexity of managing third-party models are some of the challenges LLM teams face.
What you will learn from Dhinakaran’s article:
1. Common Issues with LLMs
2. LLM Observability vs. ML Observability: What’s the difference?
3. The Five Pillars of LLM Observability:
– LLM Evals
– Traces and Spans in Agentic Workflows
– Prompt Engineering
– Search and Retrieval
– Fine Tuning
4. Setting Up an Application for Observability
LLM observability is a crucial step in managing the complexity and maximizing the potential of LLM-based applications. Enjoy the article.
Jay Revels, CEO of Ichizoku.
Aparna Dhinakaran, Co-founder & Chief Product Officer
Introducing the five pillars of LLM observability
The tech industry changed forever in November 2022 when ChatGPT debuted and many saw for the first time the capabilities of large language models (LLMs).
Since that time, everyone has wanted a piece of the action. For example:
- Expedia is working on LLM-based travel planner
- Notion is offering in-line content generation
- Stripe is trying to use ChatGPT to manage fraud and increase conversions
- Duolingo and Khan Academy are trying to use LLMs to enhance learning
This is to say nothing of giants like Microsoft, Meta, and Google using LLMs throughout their products. Amazon is now getting into the race to allow sellers to auto-generate descriptions.
These products are in various stages of maturity, but it’s clear that there is a chasm between a demo of a machine learning system and the actual product. Productizing machine learning has always been a challenge, but with LLMs the challenge has become even harder.
What Are the Typical Use Cases for LLMs?
There are many use cases that are common across LLM applications. We’ll look at a small sampling here, and then each will be covered in more detail in a future post.
Chatbots
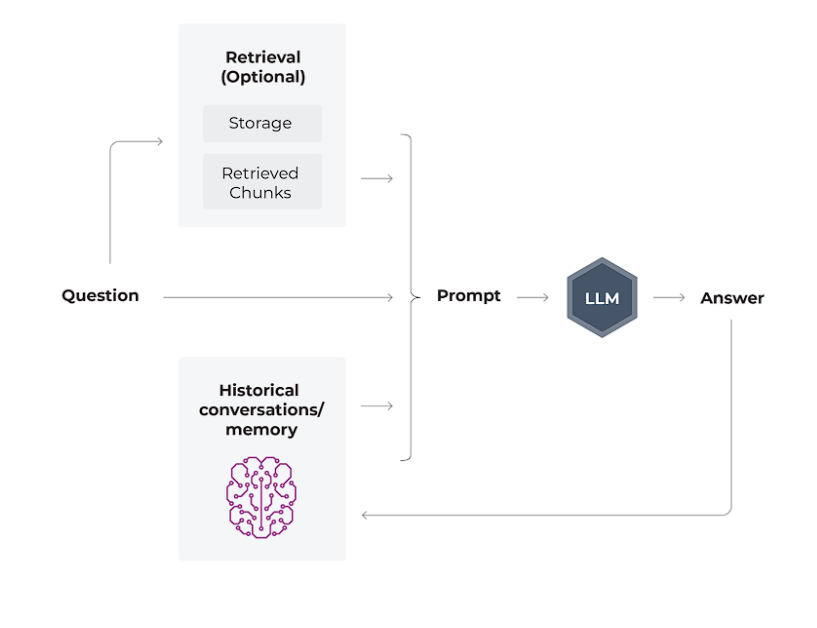
Since ChatGPT initially introduced the masses to LLMs through its chatbot, this use case is very common. It consists of the user asking a question, the system retrieving information to enrich the prompt, and then the LLM generating a response.
Structured Data Extraction

In a structured data extraction use case, the LLM receives unstructured input together with a schema and outputs a structured representation of the information. This is often useful in the context of a larger software system.
Summarization

Natural language processing (NLP) has long searched for good summarization solutions. Many of the traditional extractive and abstractive summarization techniques have now been superseded by LLMs.
Other Use Cases
In addition to these, there are many more specialized use cases, like code generation, web scraping, and tagging and labeling.
LLMs are also employed in more complex use cases like Q&A assistant and chat-to-pay. These are composed of steps (spans) that achieve a higher-order objective. Spans can be other LLM use cases, traditional machine learning systems, or non-ML software-defined tools (like a calculator).
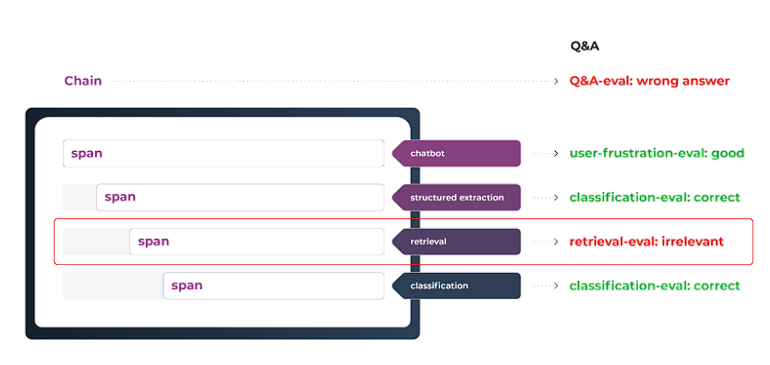
These workflows are useful but also very complex because they require proper orchestration on multiple systems, any one of which can have unique problems. These workflows do not require much code, but do not confuse that brevity for simplicity. Even a few lines can kick off very long chains of computation with multiple opportunities for error (see inset).
That complexity leads to the difficulties experienced by today’s LLM projects as they progress from “Twitter Demo” to customer use.
What Issues Arise With LLMs?
Here are several common issues.
- Hallucination: The model’s objective in training is to predict the next few characters. Accuracy of the responses is more of a side effect. As such, hallucinations, or made-up responses not grounded in facts, are common and unpredictable. You use an LLM as a shortcut, but if you have to double check everything it says, it may not be that useful. If you don’t check, however, you may get into real trouble.
- Proliferation of calls: Even solving hallucination issues can lead to greater problems. For example, one way around the above-mentioned problem is Reflexion, which asks an LLM to analyze its own results. This technique is powerful but it makes the already-complicated system even more so. Now instead of one call, you have a whole chain of calls. This is true at every span, so for complex use cases we talked about above, there are multiple calls inside multiple spans.
- Proprietary data: When you add proprietary data to the mix, things get even more interesting. The reality is that much of the data we need to answer complex questions is proprietary. Access control systems on LLMs are not as robust as they are in traditional software. It is possible for proprietary information to accidentally find its way into a response.
- Quality of response: Response quality can often be suboptimal for other reasons too. For example the tone can be wrong, or the amount of detail can be inappropriate. It is very difficult to control the quality of largely unstructured responses.
- Cost: Then there is the elephant in the room: cost. All of those spans, Reflexion, and calls to LLMs can add up to a significant bill.
- Third-party models: LLMs accessed through third-party providers can change over time. The API can change, new models can be added, or new safeguards can be put in place, all of which may cause models to behave differently.
- Limited competitive advantage: The bigger problem, perhaps, is that LLMs are hard to train and maintain. Therefore your LLM model is the same as that of all of your competitors, so what really differentiates you is prompt engineering and connection to proprietary data. You want to make sure you are using them well.
These are hard problems, but fortunately the first step in tackling all of them is the same: observability.
What Is LLM Observability?
LLM observability is complete visibility into every layer of an LLM-based software system: the application, the prompt, and the response.
LLM Observability vs ML Observability
While large language models are a newer entrant to the ML landscape, they have a lot in common with older ML systems, so observability operates similarly in both cases.
- Just as in ML observability, embeddings are extremely useful to understanding unstructured data, and embedding techniques similar to those we have discussed in the past are even more important in LLMs.
- Understanding model performance and tracking it over time is still as important as ever. Data drift and model drift are important to understand, for reasons we covered in section 3.
- Data collection (history of prompts/responses) is still very important with LLMs for understanding drift and fine-tuning models.
But there are some important differences too:
- The model of LLM deployment is very different from more traditional ML. In the vast majority of cases, you have much less visibility into the model internals because you are likely using a third-party provider for your LLM.
- Evaluations are fundamentally different since you are evaluating generation and not ranking. This necessitates a whole new set of tools, some of which are only made possible by LLMs to begin with.
- If you are using vector stores (and most retrieval cases do), there are unique challenges that may prevent optimal retrieval and thus produce less-than-ideal prompts.
Agentic workflows and orchestration frameworks like LlamaIndex and LangChain present their own challenges that require different observability approaches.
Introducing the Five Pillars of Large Language Model Observability

Let’s understand the five pillars of LLM observability in order of importance. Each merits its own research and piece, but here is a quick summary.
LLM Evals

Evaluation is a measure of how well the response answers the prompt. This is the most important pillar on LLM observability.
You can have an evaluation for individual queries, but we typically start by trying to find patterns. For example, if you look at embedding visualization for prompts and separate good responses from bad responses, patterns will begin to emerge.
- How do you know if the response was good in the first place? There are several ways to evaluate. You can collect the feedback directly from your users. This is the simplest way but can often suffer from users not being willing to provide feedback or simply forgetting to do so. Other challenges arise from implementing this at scale.
- The other approach is to use an LLM to evaluate the quality of the response for a particular prompt. This is more scalable and very useful but comes with typical LLM setbacks.
Once you have identified the problem region(s), you can summarize the prompts that are giving your system trouble. You can do this by reading the prompts and finding similarities or by using another LLM.
The point of this step is simply to identify that there is a problem and give you your first clues on how to proceed. To make this process simpler, you can use Arize’s open-sourced Phoenix framework.
Traces and Spans In Agentic Workflows
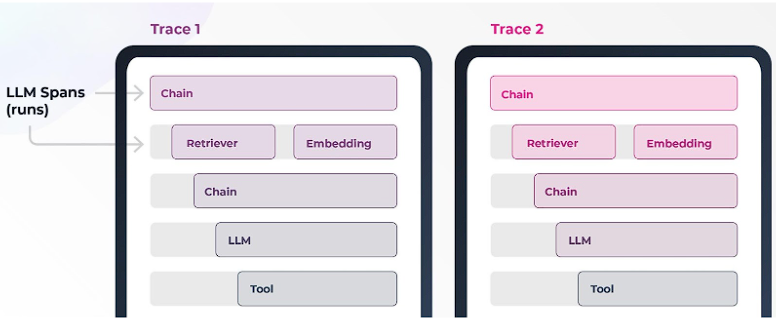
For more complex or agentic workflows, it may not be obvious which call in a span or which span in your trace (a run through your entire use case) is causing the problem. You may need to repeat the evaluation process on several spans before you narrow down the problem.
This pillar is largely about diving deep into the system to isolate the issue you are investigating. This may involve retrieval steps or LLM use case steps.
Prompt Engineering
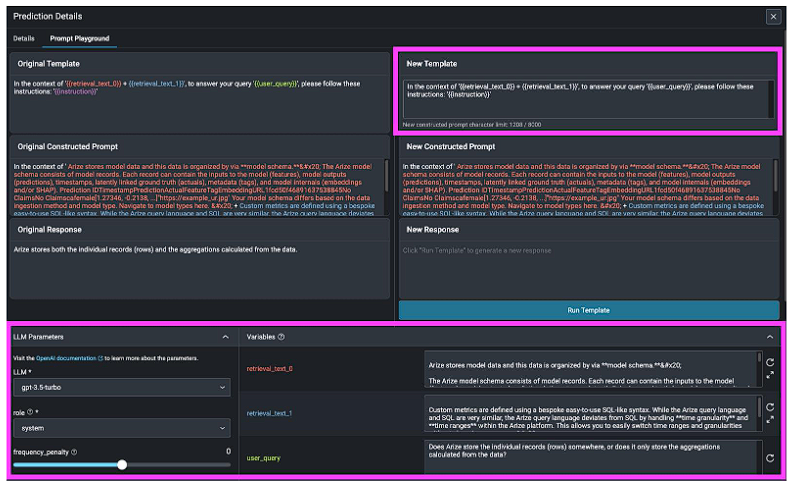
Example of Iterating and Comparing Responses Across Prompt Templates in Arize
Prompt engineering is the cheapest, fastest, and often the highest-leverage way to improve the performance of your application.
This is similar to how humans think. You are going to have a pretty hard time answering the question “Who is that?” in isolation, but if you get a little more context – “Who is that on the moon, next to the Apollo 11 landing module?” – the number of reasonable answers is narrowed down right away.
LLMs are based on the attention mechanism, and the magic behind the attention mechanism is that it is really good at picking up relevant context. You just need to provide it.
The tricky part in product applications is that you not only have to get the right prompt, you also have to try to make it concise. LLMs are priced per token, and doubling the number of tokens in your prompt template in a scaled application can get really expensive. The other issue is that LLMs have a limited context window, so there is only so much context you can provide in your prompt.
Search and Retrieval

The other way to improve performance is with more relevant information being fed in. This is a bit harder and more expensive but can yield incredible results.
If you can retrieve more relevant information, your prompt improves automatically. The information retrieval systems, however, are more complex. Perhaps you need a better embedding? Perhaps you can make retrieval a multi-step process?
To do this, you may first embed the documents by summaries. Then at retrieval time, find the document by summary first, then get relevant chunks. Or you can embed text at the sentence level, then expand that window during LLM synthesis. Or maybe you can just embed the reference to the text or even change how you organize information on the back end. There are many possibilities to decouple embeddings from the text chunks.
Fine Tuning
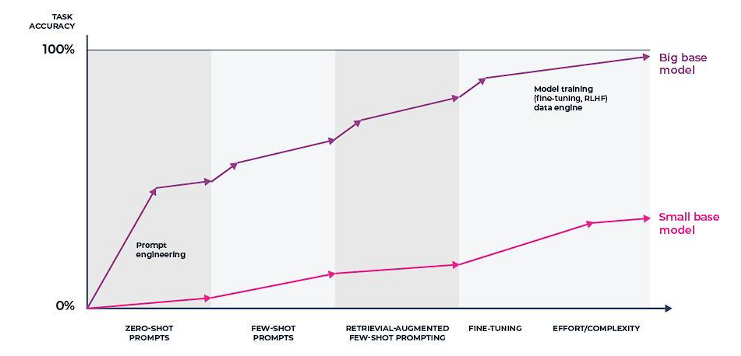
Finally, you can fine tune your model. This essentially generates a new model that is more aligned with your exact usage conditions. Fine tuning is expensive, difficult, and may need to be done again as the underlying LLM or other conditions of your system change. This is a very powerful technique, but you should be very clear about your ROI before embarking on this adventure.
How To Set Up An Application for Observability
There is no universal way to set up your application. There are many different architectures and patterns, and setting up your application is largely dependent on the particulars, but here are a few pointers.
- Human feedback: If you are lucky enough to collect user feedback, you should store your feedback and responses for future analysis. Otherwise you can generate LLM-assisted evals and store those instead.
- Multiple prompt templates: If you have multiple prompt templates, compare between them. Otherwise iterate on your prompt template to see if you can improve performance.
- Using retrieval augmented generation (RAG): If you can access the knowledge base, evaluate if there are gaps in it. Otherwise use prod logs to evaluate if the retrieved content is relevant.
- Chains and agents: Log spans and traces to see where the app breaks. For each span, use the suggestions from above on human feedback.
- Fine tuning: If you fine tune, find and export example data that can be used for fine tuning.
Conclusion
Large language models have seen an explosion in both use cases and interest in the past year. The opportunities they bring are exciting, and the power of these techniques is only beginning to be realized. Implementation is fairly easy because of abstraction, but that same abstraction and inherent system complexity make it essential that you have a good understanding of how every element of the system is performing. In short, you need LLM observability to run a reliable LLM app.