私のプロフェッショナルなキャリアで触れたデータベースは、100%がSQLデータベースだったため、私のデータベースに対する考え方(この言葉遊びを楽しんでください!)は常にリレーショナルモデルが基本でした。
しかし、2020年に小さなサイドプロジェクト(Twitchのストリームにインタラクティブ性を提供するBot)を立ち上げた際、当時のデータ保存要件にはリレーショナルモデルは必要なく、NoSQLソリューションであるMongoDBを選びました。
4年後の2024年、この小さなサイドプロジェクトは予想以上に大きく成長し、テキストベースのゲーム「Pantherworld」へと進化しました。この進化について興味がある方は、どのように小さなTwitchボットからゲームに成長したかを解説した私の2024年のカンファレンス講演「Entertainment as Code」をYouTubeでチェックしてください。
Pantherworldは2024年4月から、私のTwitchチャットインターフェースを通じて、24時間、週7日、数百人にプレイされています。ゲーム内のイベントは、私のストリームで発生するイベントに基づいています。例えば、新しいフォロワーを獲得すると、ランダムなワールドアイテムがランダムなゾーンに出現します。プレイヤーの目標は、Twitchチャットでテキストコマンドを使って世界を移動し、アイテムを収集してインベントリを埋めることです。アイテムには希少なものもあります。
プレイヤーがゲームの進行状況を追跡できるようにするため、私はフロントエンドのコンパニオンアプリを作成しました。このアプリは、NoSQLデータベースからAPIを介してゲームデータを取得します。ゲームが多くのプレイヤーを惹きつけるにつれて、明らかにスケーラビリティ(拡張性)の問題があるAPI呼び出しが一つありました。
それは、リーダーボードデータを取得するエンドポイントでした。このエンドポイントは非常に遅く、その原因が分からなかったため、フロントエンドでスケルトンローダーを追加しました(単に空白画面を表示するのではなく)。遅さを隠そうとしましたが、実際に見るのはとても辛かったです。
重要なのは、私のデータベースに対する思考モデルが常にリレーショナルなものであったことを繰り返し強調することです。
そのため、私は自分がNoSQLをうまく使えていないのだろうと思っていましたが、どこで間違えているのかは分かりませんでした。さらに、このアプリは4年にわたる開発の中で大きく進化し、そのデータモデルの要件がリレーショナルモデルを必要とするようになりました。最初の直感的な反応としては、全体をリファクタリングしてSQLデータベースを使うようにしようと思いました。しかし、4年も経ったレガシーアプリをリファクタリングし、数十万のNoSQLドキュメントをSQLに移行するのは現実的ではありませんでした。
そこで、コードの最適化方法を理解するためにトレースを利用することに決めました。
トレーシング(Tracing)とは何か?
トレーシングは、アプリ内で発生するすべてのイベント(関数呼び出し、データベースクエリ、ネットワークリクエスト、ブラウザイベントなど)をキャプチャする技術で、アプリがどのように動作しているかを理解し、パフォーマンス向上のための改善点やバグ修正ができる箇所を特定するのに役立ちます。
Sentryでは、個別のイベントはスパンとして名前付けされ、これらは各スパンと一緒に送信されるHTTPヘッダーを通じてトレースビューで接続されます。また、これらのイベントをアプリやサービスの全スタックに渡ってキャプチャすることができ、これを分散トレーシングと呼びます。
MongoDBデータベースクエリのトレーシングサポートを追加する方法
MongoDBデータベースクエリのトレーシングは、Sentryの最新のJavaScriptおよびPython SDKで標準でサポートされています。追加の設定は不要です。
私のバックエンドAPIはExpressアプリなので、最新のSentry Node SDKを使用しています。Sentry SDKの初期化コードは別のファイルにまとめることが推奨されています。私の例では、そのファイルをinstrument.tsと呼んでいます。
以下に、最も関連性のあるオプションを示した簡略化されたSDK設定を示します。

tracesSampleRate オプションは、Sentry SDKにトレーシングを有効にするよう指示します。このオプションは0から1の間の値を取り、アプリがSentryに送信するトレースの割合を設定します。アプリのユーザー数やSentryアカウントのプランに基づいて、この値を調整することをお勧めします。
Distributed Tracing(フロントエンドアプリからバックエンドアプリへのトレース)を有効にするには、tracesSampleRateを設定するだけでなく、フロントエンドのSentry SDK設定にbrowserTracingIntegrationを追加する必要があります。ただし、Next.jsやNuxtなどのフルスタックフロントエンドフレームワークは、デフォルトでbrowserTracingIntegrationを追加するため、このルールは適用されません。
バックエンドでは、SentryがMongoDBを含むアプリケーション内のすべてのモジュールを自動的に計測できるように、他のモジュールを要求する前に instrument.js ファイルをインポートすることを確認してください。
私が実際にアプリケーションで使用しているエントリーポイントファイル app.ts の先頭部分でのインポート例をご紹介します。以下の通りです。

MongoDBのクエリをExpressアプリでトレースする設定が完了したので、次にリーダーボードのコードがなぜここまで遅かったのかを調査してみましょう。
なぜ単一のAPI呼び出しが5秒以上かかっていたのか
コードの最適化を行う前のトレースのスナップショットがこちらです。
API呼び出しの所要時間が強調表示されています。/world/leaderboard APIへのHTTP GETリクエストは、およそ4秒〜8秒かかっていました。
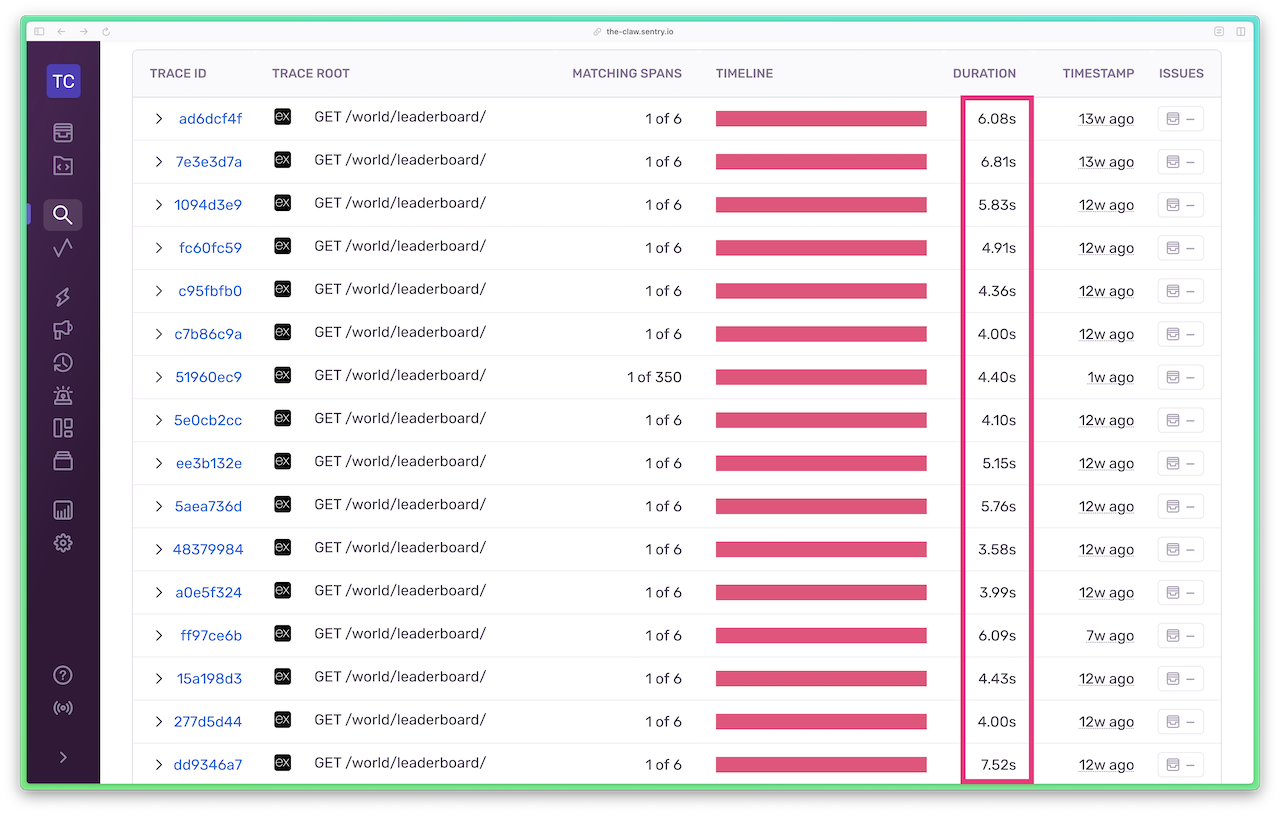
単一のAPI呼び出しに対する(ズームアウトされた)トレースビューでは、一連のリクエストウォーターフォールと重複したデータベースクエリが表示されています。これは改善が必要です。
API呼び出しを短縮する方法を探る前に、フロントエンドアプリから/ world / leaderboard に対する呼び出しが行われるときに何が起こるのかを見てみましょう。
リーダーボードAPI呼び出しは、プレイヤーの配列を返します。
各Player(プレイヤー)オブジェクトには、username(ユーザー名)、items count(アイテム数)、wealth_index番号(wealth_indexは、すべてのインベントリアイテムの合計で、そのアイテムのレアリティで掛け算された値)が含まれます。
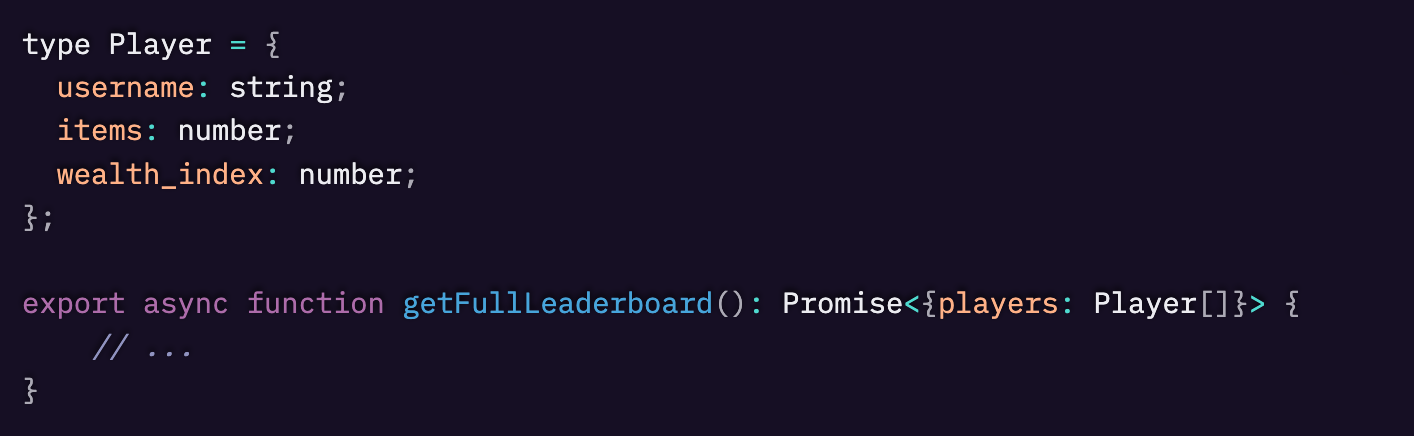
こちらが元のコードで、少し簡略化されています。コードは以下のことを行います。
- Itemsコレクションをクエリして、ユーザーに割り当てられたすべてのアイテムを取得し、アイテムをuserIdでグループ化し、そのアイテムのカウントを返します。
- 各プレイヤーについて、getAllItemsForPlayer()を呼び出します(これによりItems コレクションが再度クエリされます)。
- 各プレイヤーについて、Playerコレクションをクエリします(このクエリの目的は、アイテムデータと一緒に保存したくなかったuserDisplayNameを取得するためだけです。SQLのジョインがあれば便利でした)。
- 各Playerオブジェクトを構築し、計算し、配列に追加し、その配列をソートして返します。
改善できる点について、すでにいくつか予測がついているかもしれません。では、間違いについて説明していきましょう。
間違いその1: 本番環境に近いデータでテストしなかった
リーダーボードAPIのコードを書いて開発環境でテストしたときは、遅さを感じませんでした。実際に本番環境に機能をリリースして初めて、その遅さに気づきました。
開発用データベースには、本番環境のゲームデータの20%以下しか含まれていなく、データ量が変わりません。しかし本番環境のデータベースは常に膨張しており、毎時間約30個のアイテムと10人のプレイヤーが追加されていました。
間違いその2:ヘルパー関数は必ずしも役立つわけではない
勤勉でDRY(Don’t Repeat Yourself)な開発者になろうとした結果、既存のヘルパー関数 getAllItemsForPlayer() を再利用しました。
この関数はプレイヤーの財産指数を計算します。問題は、getAllItemsForPlayer()が、すべてのプレイヤーに対してインベントリアイテムを取得するためにItemsコレクションに対して呼び出しを行っていたことです。このコードがインラインで書かれていたなら(別の関数に抽象化されていなければ)、データベースにn 回呼び出しを行うのが適切でないことが自明であったはずです(ここでnはアクティブプレイヤーの数です)。
なぜなら、関数の冒頭で既にItems テーブルをクエリしていたからです。最初のデータベースクエリでそのデータにはすでにアクセスできていたのです。
間違いその3: 目的に合わないコードをコピーして貼り付けた
フルリーダーボードAPIの前に、ゲーム内でアイテム数によってトップ3のプレイヤーを見つける小さな関数を作成していました。
この関数は元々、ホームページに表示されていました。その関数は、Items コレクションに対して以下のクエリを実行していました。

このコードを、上記の元の getFullLeaderboard() 関数の最初のクエリと比較すると、$sortと$limitを除いて、同じコードです。
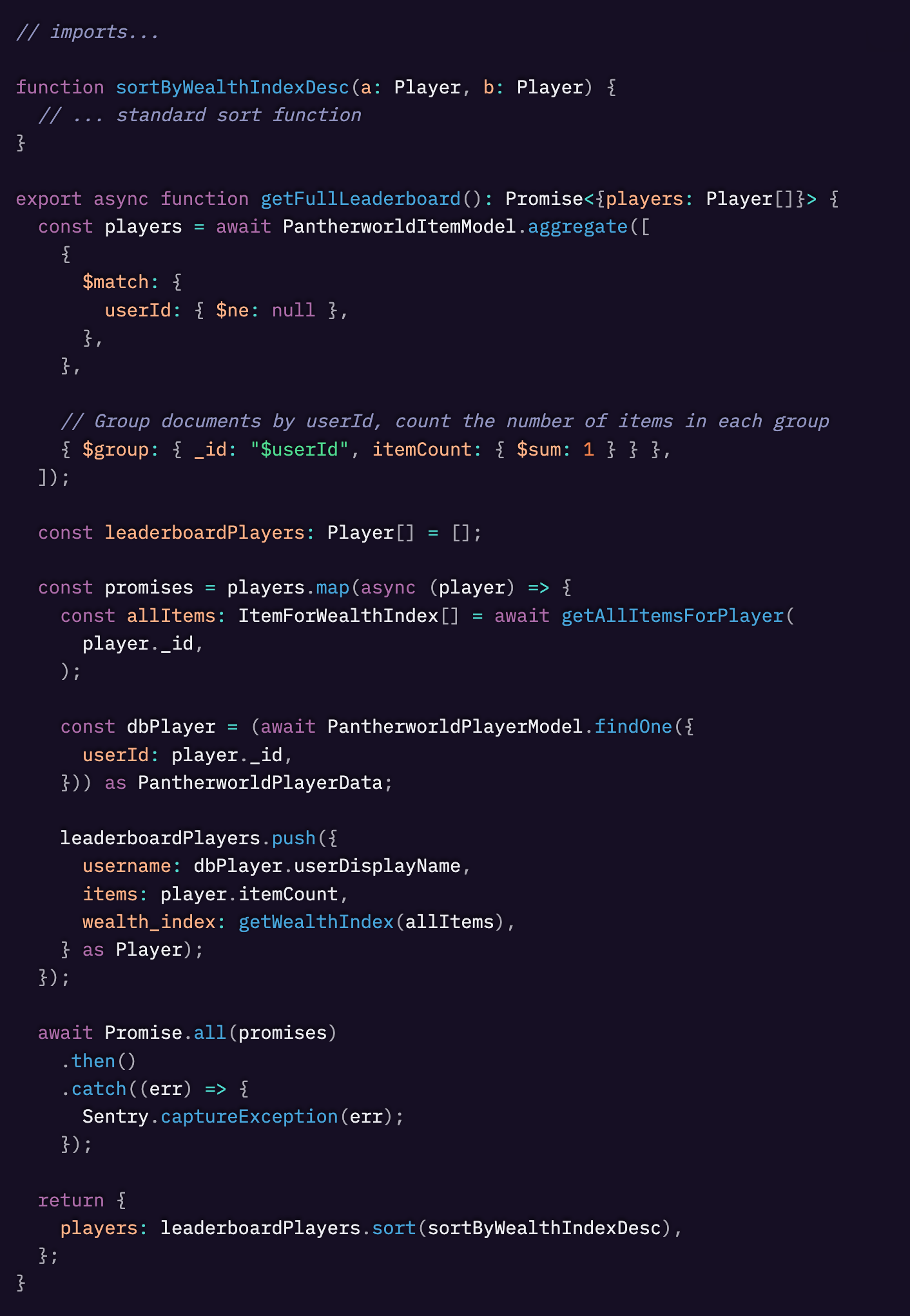
これは大きな間違いでした。フルリーダーボードAPIでItemsコレクションをクエリした際、すでにすべてのアイテムデータにアクセスできていたため、グループ化された配列をループしてヘルパー関数 getAllItemsForPlayer() を使用する必要はありませんでした。
Itemsコレクションのクエリで$push演算子を使用することで、ユーザーIDをそのユーザーが所有するアイテムの配列にマッピングするオブジェクトの配列を作成できたはずです。
APIの呼び出し時間を5秒以上から100ms未満に短縮した方法
それでは、ここからが本題です!
この遅いAPI呼び出しの主な原因は、データベースをn回(nはプレイヤー数)呼び出すヘルパー関数でした。
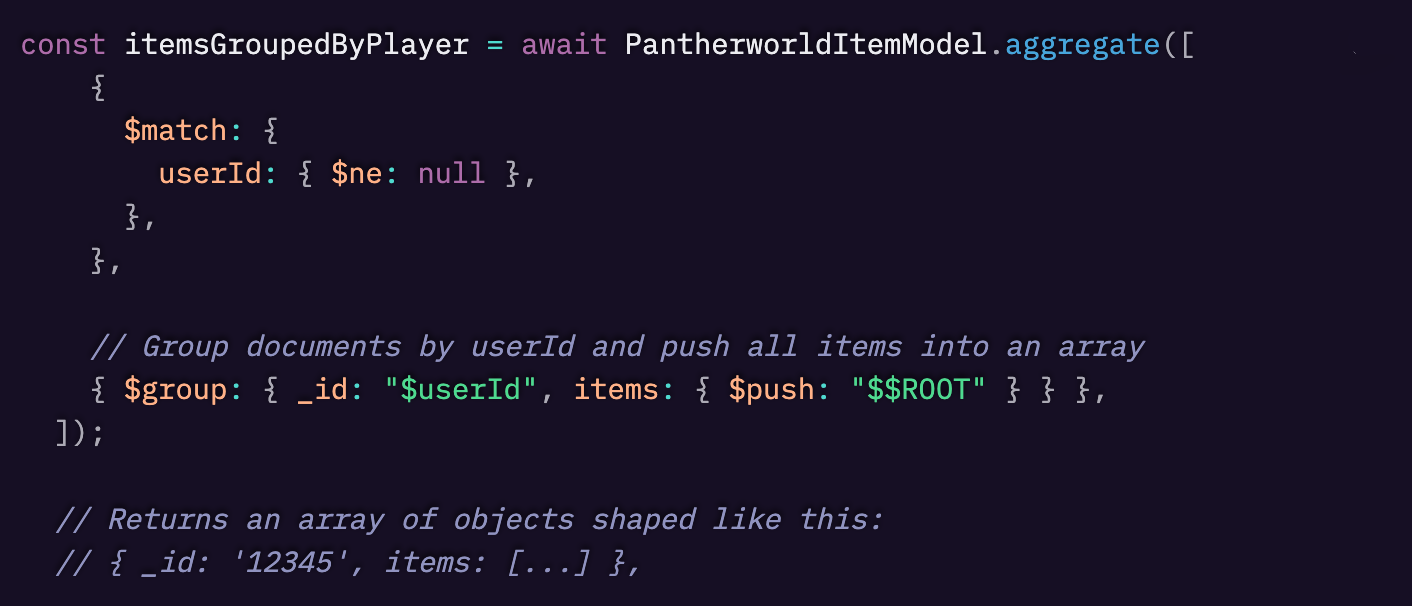
これらの余分なn回のデータベースクエリを削除し、Itemsコレクションから一度にすべてのデータを取得し、$pushを使用して必要なデータをグループ化しました。(データを捨てているわけではありません)
ただし、別のヘルパー関数を再利用してプレイヤーの財産指数を計算できるように、特定の形式でアイテムの配列を構築するために、さらに作業が必要でした。
しかし、それだけの価値はありました。リーダーボード関数は現在、データベースに対して2回の呼び出しだけを行います。
1回はItemsコレクションへの呼び出し、もう1回はPlayersコレクションへの呼び出しです。以下は、簡略化したリファクタリング後のコードです。
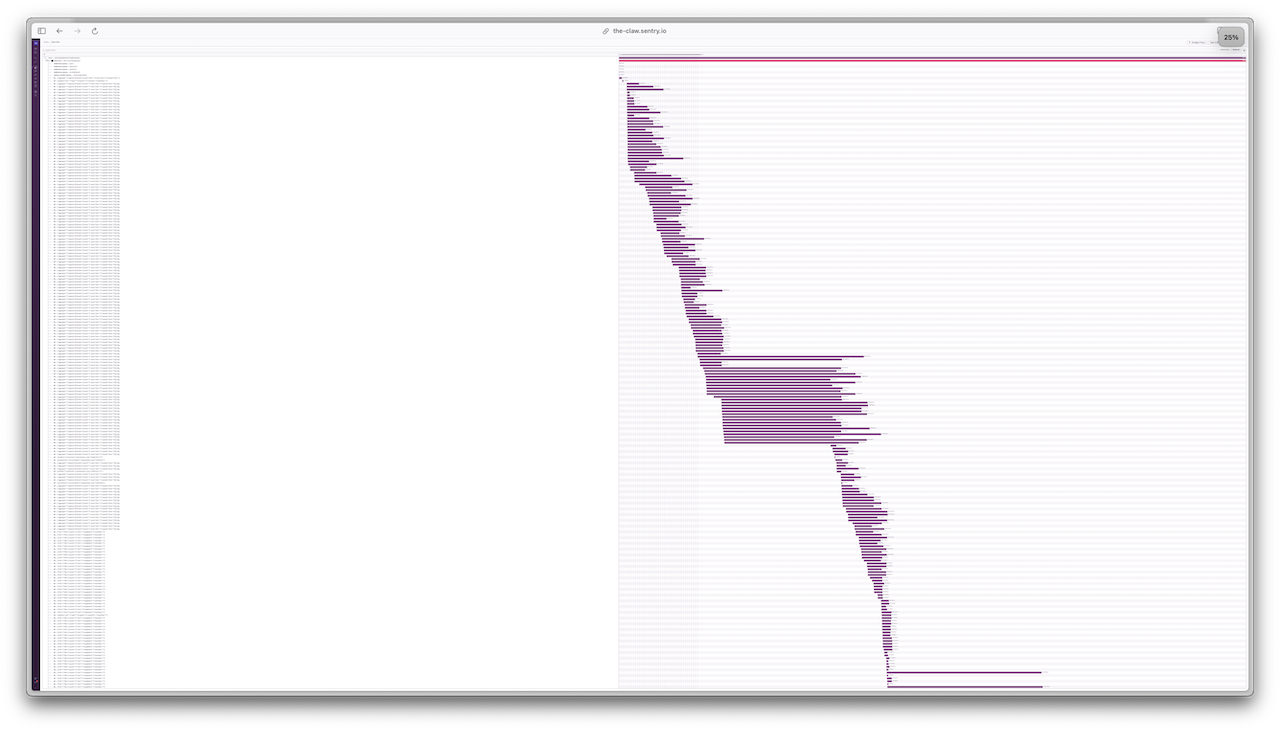
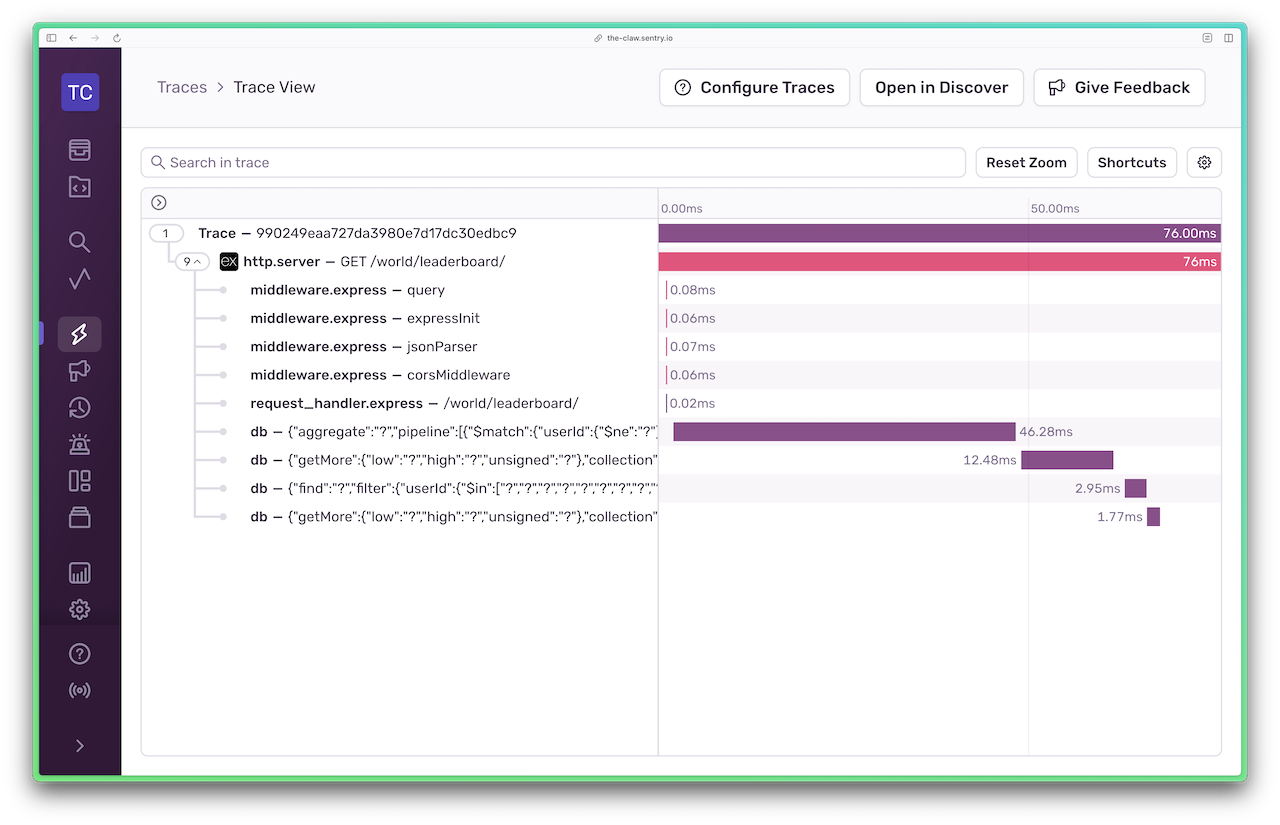
こちらが最適化後のトレースビューです。
現在はなんと、100ms未満です!
これは誰がなんと言おうと「成功」です。
結論: トレーシングはパフォーマンス問題のデバッグ時に推測を排除する
トレーシングがなければ、パフォーマンスのボトルネックの根本原因を見つけるためにコードをいじり回していたかもしれません。
しかし、トレーシングを使うことで、遅延の原因が明確になりました。Sentryは、何が問題だったのかを視覚的にわかりやすく示してくれました。
開発者として、私たちは皆、やらなければならない仕事があり、(おそらく)締め切りもあります。トレーシングは、私たちが仕事を効率よくこなす手助けをしてくれるものの一つです。推測を排除することで、私たちは仕事をうまく効率的に進められ、その分、もっとリラックスする時間を確保できます。
皆さんもSentryを活用して、リラックスする時間を獲得してください。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。