Ichizokuは日本唯一のSentry公認販売業者です。日本語のドキュメント、動画、サポート窓口で日本のお客様のSentry活用を支援します。
壊れたコード、クラッシュ、壊れたAPIコールに対処できるデベロッパーファーストで作られた唯一のアプリケーション監視プラットフォームで、手がかりではなく答えを導き出しましょう。
350万人以上の開発者と8,500以上のチーム・会社がSentryを利用し、実際に意味がある事項を確かめ、緊急の問題を迅速に解決し、コードについて継続的に学習しています。
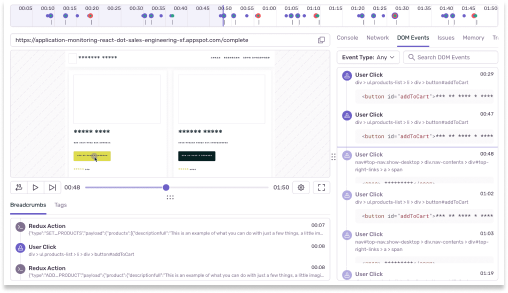
あらゆるプラットフォームを監視し バグを逃さない
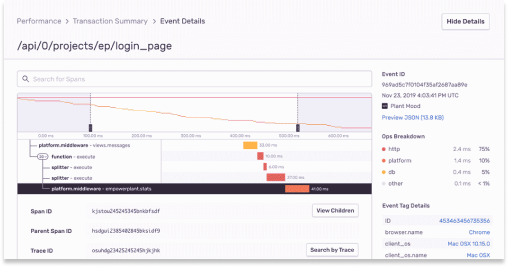
十分な背景情報により、チーム間での 修正の行き来の必要を排除
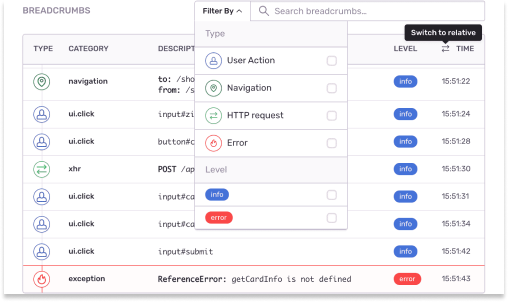
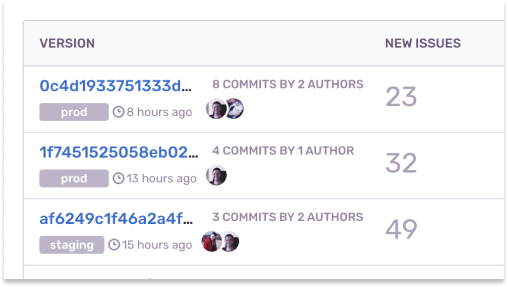
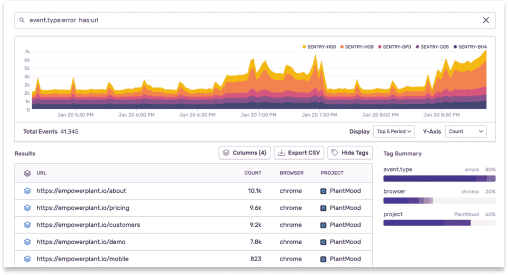
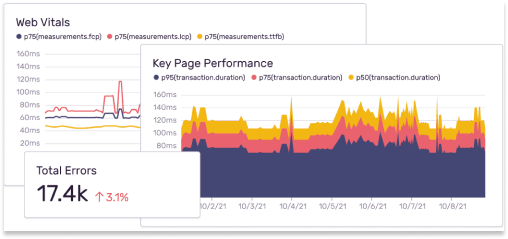
プロジェクト、チーム、組織を通じた トレンドや例外を明らかにする
その効果をご自身でお確かめください
御社の組織全体に対し、アプリケーションの健全性を可視化する必要があります。Sentryは、エンジニア、サポート、プロダクトマネジメント、そしてそれ以外の人々へも洞察を明らかにするための文脈を提供します。
トラフィックが急増しましたか?ご安心ください。私たちは準備万端です。Sentryの各サービスは、適切にプロビジョニングされ冗長化されたサーバーを使用し、常にメンテナンスされています。
Sentryがエラーを起こすことはほとんどありません。本当にないのです。status.sentry.io のダッシュボードで、リアルタイムで稼働状況をご確認ください。
Follow us:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}