
Node.jsは2種類のモジュールをサポートしています。
EcmaScriptモジュールとCommonJSモジュールです。
ESモジュールはJavaScriptにおけるモジュールの公式な標準であり、すべてのモダンブラウザでサポートされています。
CommonJSモジュールは、Node.jsがデフォルトで使用するモジュールです。これらはブラウザによってサポートされておらず、公式の標準でもありません。しかし、現在でも広く使われています。
Node.jsはどのようにエントリーポイントをロードするのか?
どのローダーを使うかを区別するために、Node.jsはいくつかの要因に依存することを理解しておきましょう。
最も重要なのはファイルの拡張子です。
ファイル拡張子が .mjs の場合、Node.js は ES モジュールローダを使用します。
ファイル拡張子が.cjsの場合、Node.jsはCommonJSモジュール・ローダーを使用します。
ファイル拡張子が .js の場合、
package.json ファイルに “type”: “commonjs” があれば(または単に “type “フィールドがない場合)、Node.js は CommonJS モジュールローダを使用します。
package.jsonファイルに “type”: “module”があれば、Node.jsはESモジュールローダを使用します。
この決定はlib/internal/modules/run_main.jsファイルで行われます。
以下にコードの簡略版を記載します。
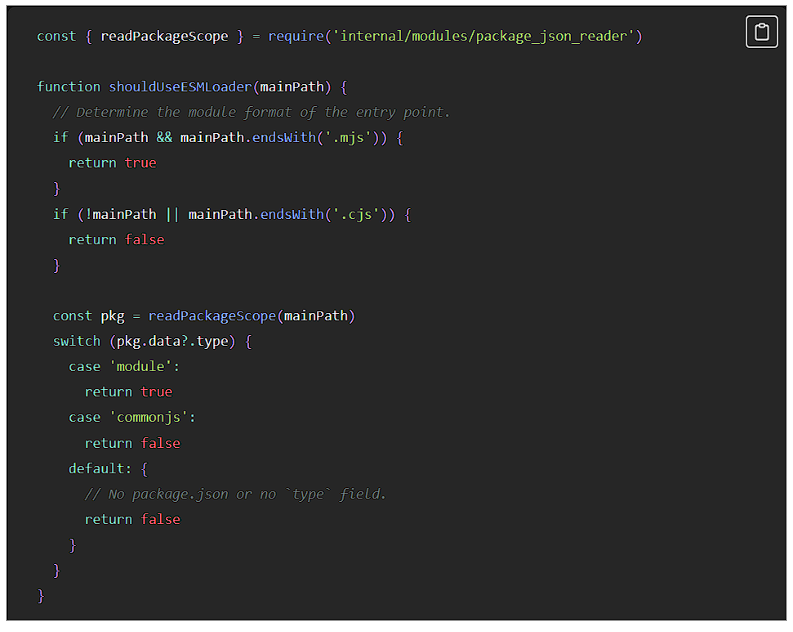
readPackageScope は、package.json ファイルを見つけるまで、ディレクトリツリーを上方向に走査します。
この投稿で最適化する前は、readPackageScopeはpackage.jsonファイルを見つけるまで内部バージョンのfs.readFileSyncを呼び出します。
この同期呼び出しはファイルシステム操作を行い、Node.js C++レイヤーと通信します。
この操作には、データのシリアライズ/デシリアライズのコストがかかるため、返す値/タイプによってパフォーマンスのボトルネックがあります。
そのため、readPackageScope内でreadPackage(別名fs.readFileSync)を呼び出すことはできるだけ避けたいです。
Node.jsはどのようにpackage.jsonを解析するの?
デフォルトでは、readPackageは内部バージョンfs.readFileSyncを呼び出してpackage.jsonファイルを読み込みます。
この同期呼び出しは、Node.js C++レイヤから文字列を返し、後でV8のJSON.parse()メソッドを使用して解析されます。
このJSONの妥当性に応じて、Node.jsは残りのローダーの実行に必要なオブジェクトをチェックした後作成します。
これらのフィールドは、pkg.name、pkg.main、pkg.exports、pkg.imports、pkg.typeです。JSONの構文に誤りがある場合、Node.jsはエラーを投げて処理を終了します。
この関数の出力は、同じパスに対して readPackageScope を再度呼び出さないように、後で内部 Map にキャッシュされます。このキャッシュは、プロセスの寿命が尽きるまで保存されます。
package.jsonフィールドとリーダーの使用法
最適化の前に、Node.jsがこれらのフィールドをどのように使用しているかを見てみましょう。
Node.jsコードベースでpackage.jsonフィールドをパースして再利用する一般的なユースケースは以下の通りです。
- pkg.exportsとpkg.importsは、入力に応じて異なるモジュールを解決するために使われます
- pkg.mainは、アプリケーションのエントリーポイントを解決するために使われます。
- pkg.typeは、ファイルのモジュール形式を解決するために使われます。
- pkg.nameは、自己参照するrequire/importがある場合に使用されます。
さらに、このpackage.jsonの結果を使用してファイルの整合性を検証する実験的なバージョンの「Subresource Integrity check」をサポートしています。
最も重要な使い方は、require/importを呼び出すたびに、Node.jsはファイルのモジュール形式を知る必要があるということです。例えば、ユーザーがCommonJS (CJS) アプリケーション上でESMを使用するNPMモジュールをrequireした場合、Node.jsはそのモジュールのpackage.jsonファイルを解析し、NPMパッケージがESMであればエラーを投げる必要があります。
ESMとCJSのローダー間で、これらの呼び出しと使用があるため、package.jsonリーダーは、Node.jsローダー実装の最も重要な部分の1つです。
最適化
キャッシュ層の最適化
package.jsonリーダーのパフォーマンスを最適化するために、まずキャッシュレイヤーをC++側に移し、実装をできるだけファイルシステムの呼び出しに近づけるようにしました。
この決定により、C++でJSONファイルをパースせざるを得なくなります。
この時点で、私には2つの選択肢がありました。
- V8のv8::JSON::Parse()メソッドは、v8::Stringを入力とし、v8::Valueを出力として返却する
- JSONファイルのパースにはsimdjsonライブラリを使用する
ファイルシステムは文字列を返すので、その文字列をv8::Stringに変換してstd::stringとしてキーと値を取り出すだけでは意味がありません。
そこで、Node.jsの依存関係としてsimdjsonを追加し、それを使ってJSONファイルをパースするようにしました。
この変更により、C++でJSONファイルをパースし、必要なフィールドだけを抽出してJavaScript側に返すことができるようになり、シリアライズ/デシリアライズが必要な入力のサイズが小さくなりました。
シリアライズ・コストの回避
不必要に大きなオブジェクトを返さないようにするため、readPackage関数のシグネチャを必要なフィールドだけを返すように変更しました。この変更により、shouldUseESMLoaderは以下のように単純化することができます。
C
キャッシュ・レイヤーをC++に移行することで、package.jsonファイルの型を取得するために、文字列の代わりにenum(整数)を返すマイクロ関数を公開できるようになりました。
C++の呼び出しを1対1に減らす
CommonJS では、readPackageConfig は、ESM ローダーの getPackageScopeConfig 関数の下に実装されています。
この関数は、該当するpackage.jsonファイルを解決して取得するために、多くのC++コールを行いました。実装は以下の通りです。
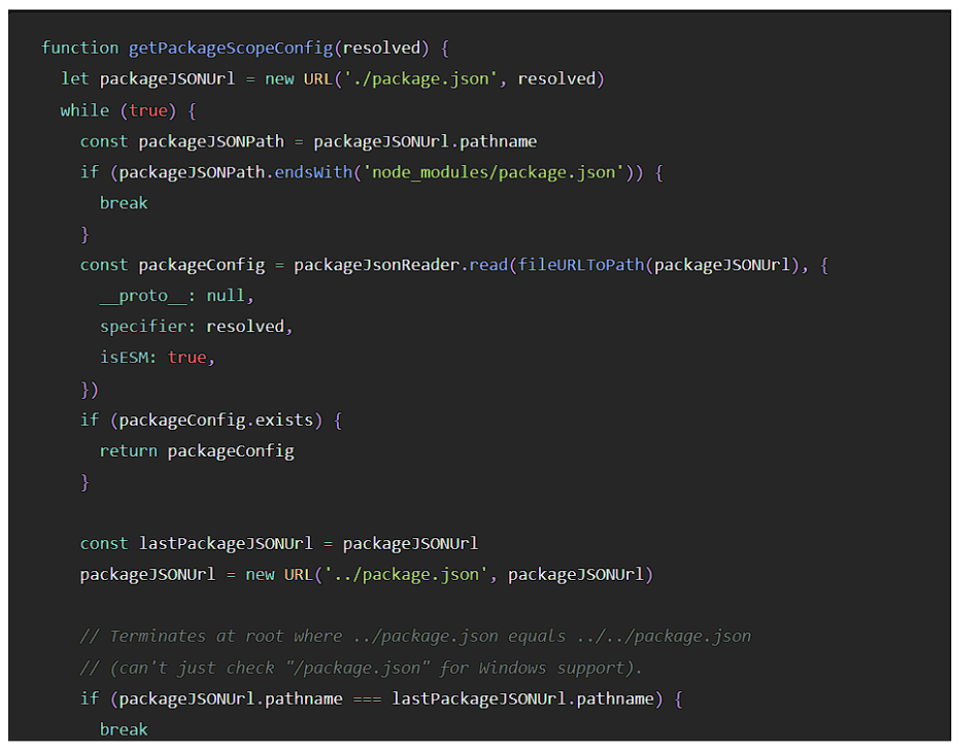
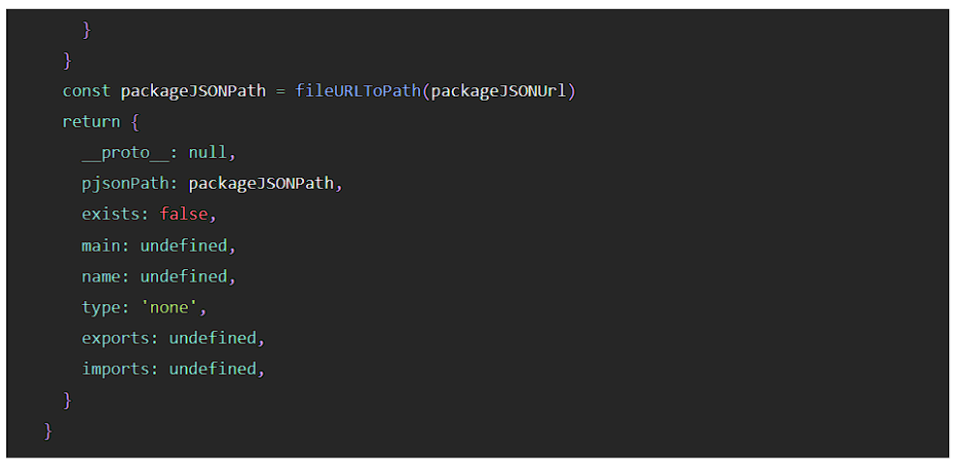
上記の内容をまとめると『getPackageScopeConfig関数は以下の関数から3回C++を呼び出している』ということになります。
new URL(…) は、internalBinding(‘url’).parse() C++ メソッドを呼び出します。
入力が文字列の場合、path.fileURLToPath() は new URL() を呼び出します。
packageJsonReader.read()は、fs.readFileSync() C++メソッドを呼び出します。
この関数全体をC++に移行することで、C++の呼び出し回数を1対1に減らすことができました。
この変換により、url.fileURLToPath()をC++で実装することも余儀なくされました。
最終的な結果
これらの変更を含むPRは、Githubでご覧いただけます。
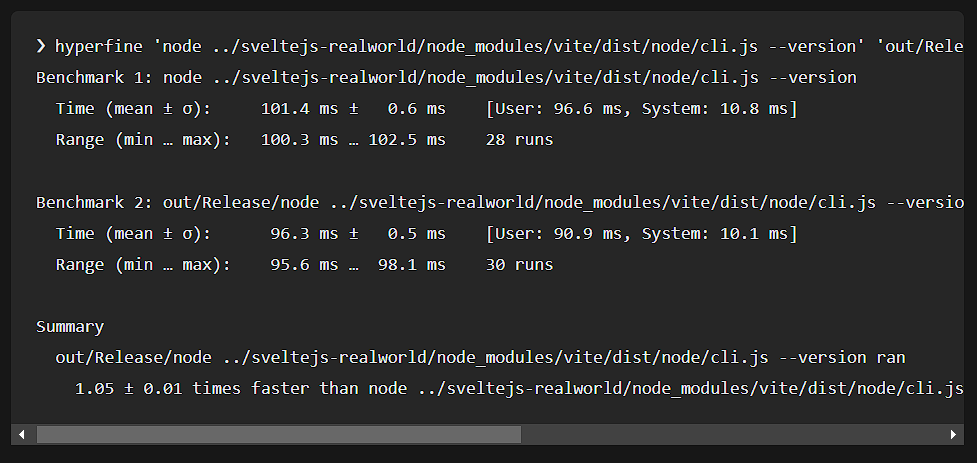
実際のSvelteアプリケーションでは、ESMの実行が5%高速化しました。
また、不要なフィールドを避けることで、ローダーが保存するキャッシュのサイズも小さくなりました。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

