ユーザーにとって素晴らしいアプリは、処理パフォーマンスが高いです。
しかし、ページロードに10秒かかるアプリは決して良いとはいえません。ユーザーは安定しかつ高速なアプリケーションを望んでます。Sentryは、コードのどこに異常があるのか通知します。
それだけでなく何が遅いのか、どう修正すればいいのかを詳細に出力します。
パフォーマンスモニタリングを最大限に活用
パフォーマンスモニタリングでは、複雑なケースが多々あります。
その理由のひとつは、開発者のエコシステムが複雑であるということです。私たち開発者は、一つのプロジェクトでアプリケーション全体を構築することはありません。
つまり、あるプロジェクトでの速度低下が、別のプロジェクトでのパフォーマンスのボトルネックになる可能性があるというわけです。
私たちのプロジェクトのエコシステムが複雑になると、スタック全体を監視する必要が生じます。
そこでSentryを使うと、速度低下を修正する方法についてのヒントを得ることができます。また、Sentryを使えば、原因となっているコードを特定することもできます。
例えば、フロントエンドのリクエストからバックエンドの遅いAPIコールまでのトレースを追うことが非常に簡単になります。
サービス間チャッター
一般的に、フロントエンド(クライアント)側はバックエンド側と通信します。
バックエンドは、DBサーバーやサードパーティサービスと連携します。
Eコマース会社を例に考えてみましょう。このストアのフロントエンドは、Webサイトとモバイルアプリを保持しています。どちらもAPI Gatewayを介して、情報をインベントリーサービスにルーティングします。そして、最終的に決済サービスに情報を転送します。
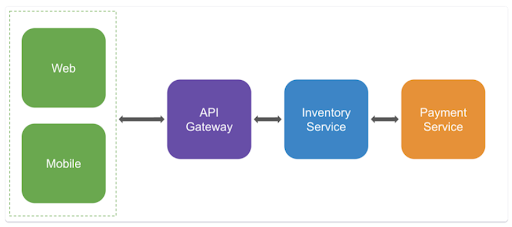
クライアント(フロントエンド)から始まり、決済サービスまでのトレース内の各トランザクションは、連鎖的に影響を与える可能性のある呼び出しの連なりと言えます。
しかし、すべてのサービスやプロジェクトにテレメトリー(処理の監視データ、計測データのこと)がなければ、開発チームはエンドツーエンドのトレースを完全に可視化することはできません。
以下のケースを考えてみましょう。
例えば、Webのメトリクスが良好であるとします。Web開発チームは満足しています。
しかし、インベントリーサービスやチェックアウトフローの処理に長い時間がかかっている可能性が出てきました。
このとき、何が問題なのか、どこに原因があるのか特定できず、チーム内で混乱が生じるリスクが発生します。
原因を特定するには、各サービスがどのように通信しているかを理解する必要があります。
あるサービスが他のサービスの応答を待っていると仮定します。
であれば、アプリケーションのパフォーマンスはもちろん低下します。
すると、ユーザーはページロードに長い時間待たされることになります。
…このように、Sentryを使用するとフロントエンドとバックエンドを横断的に分析することが可能になります。あるプロジェクトの操作が、別のプロジェクトの操作をどのように遅くしているかを見ることができます。
プロジェクト横断的な視認性
さて、それらの機能はどのように動作するのでしょうか。
SentryのSDKは、お客様のコードの変更を監視し、スループット、Apdex、User Misery、トランザクション期間などのメトリクスを測定します。
複数のシステムに渡って、エラーの影響度合いを表示することができます。
また、Sentryはトランザクションとスパンからなる分散トレーシングを取得します。
これらのトランザクションとスパンは、個々のサービスと、それらのサービス内の個々のオペレーションを測定します。
トランザクションは、ある操作をサポートするために呼び出されるサービスの単一のインスタンスを表します。
測定・追跡したい(例:ページロード、ページナビゲーション、APIコール、非同期タスク)個々のオペレーションはスパンと呼ばれます。パフォーマンスの悪いスパンは、レイテンシーに影響を与える可能性があります。
その結果、UX(ユーザーエクスペリエンス)が低下したり、スループットに問題が生じたりする可能性があります。
これはアクセスがピーク時に達した時、サイトに悪影響を及ぼすリスクがあります。
Sentryの分散トレース機能により、あるプロジェクトの遅いスパンが、他のプロジェクトのトランザクションをどのように妨げているかを確認することができます。
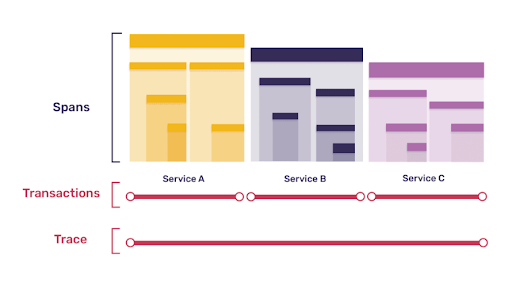
分散トレースでは、コードのどこで、何が遅いかを教えてくれます。
また確認に手間のかかるサードパーティの依存関係も特定することができます。
分散トレースは、Trace ViewとTrace Navigatorのバックボーンとなっています。
トレースビューとトレースナビゲータは、プロジェクト間でスパンがどのように相互作用しているかを示すミニマップを出力します。
遅いものを見つける
さて、先ほどのEコマースの例に話を戻します。
フロントエンドはReactで構築され、バックエンドはPythonのFlaskフレームワークを使うことがわかりました。
ある日、商品ページの読み込みが遅いことに気づきます。
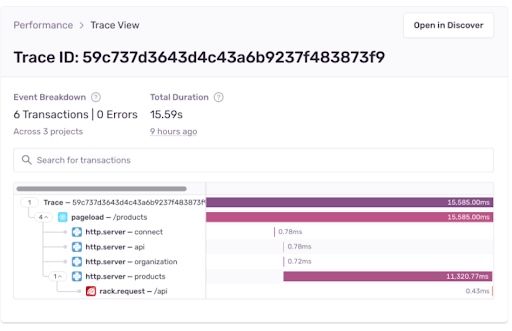
SentryのPerformanceタブに行くと、/productsページのp50が7秒以上になっていることがわかります(一目でわかります!)。
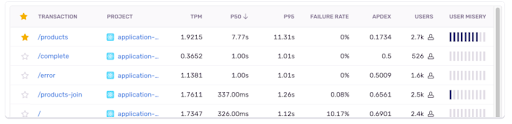
ページの読み込み時間が遅いのは、実際に開発中のReactプロジェクトにあります。
しかし、その原因は一体どこにあるのでしょうか?
それでは、実際に探してみましょう。
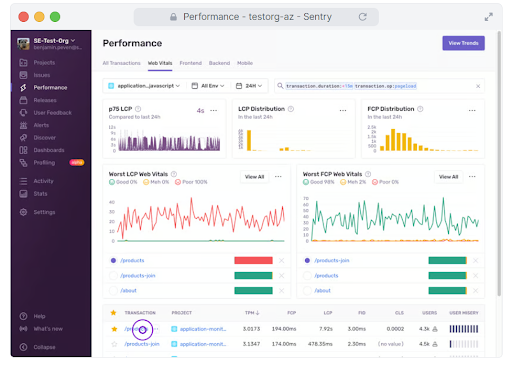
1. Transaction Summary ページに移動するために、/productsトランザクションを選択しました。このページでは、トランザクションの期間を時系列で見ることができます。また、遅いトランザクションに関連するイベント、Suspect Spans、Tags…も見ることができます。
2. 次に、このトランザクションに関連するイベントIDを選択します。この例では、ページのロードに11秒以上かかっていることがわかります。イベントIDは11秒以上かかっています。これは、私のReactとFlaskのプロジェクトに関連するスパンをいくつも持っています。
3. ここから、各スパンの持続時間と、トランザクションに遅れが生じているスパンを確認することができます。あるスパンが10秒以上かかっていることがわかりますね。驚くことに、予想していたReactプロジェクトではなく、Flaskのプロジェクトにありました!
遅いスパンを特定した後、スパン内の操作を確認するためにTransaction Summaryを選択します。
これが、分散トレースが非常に重要である理由です。
トランザクション・サマリーのページでは、遅いn+1個のデータベース・クエリーが停止を引き起こしていることがわかります。
フルスタック監視が重要な理由
トランザクション・サマリーの一覧の中から遅いスパンを選び出すことができれば、パフォーマンス問題の根本原因を知る最短の方法となります。そうすれば、その問題を解決する方法がわかります。
Suspect Spansは、トランザクションを示しています。
アプリケーションの処理速度を低下させる原因となっている可能性が高いスパンを確認することができますね。
しかし、フロントエンドだけを監視している場合、間違ったスパンを修正しようとすることに集中してしまう可能性があります。根本的な原因は、バックエンドプロジェクトにおける依存関係である可能性があります。
スタック全体を監視することで、スタック全体のサービスが互いにどのように通信しているかを可視化することができます。実際に見てお分かりかと思いますが、これによって速度低下の原因となっている相互依存関係を簡単に見つけることができました。
フロントエンドとバックエンドにSentryをインストールすることで、これまで手間暇かけていた解析を大幅に減らし、時短に繋がります。根本的な原因を解決しないまま、一つのプロジェクトで何かを修正することに時間を費やすことはありません。
ご質問やフィードバックは、GitHub、Twitter、または私たちのDiscordへお気軽にご連絡ください!
また、Sentryを初めて使う方は今日から無料で試すことができます!デモをリクエストして、ぜひお試しください。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。