Dan Mindruはフロントエンド開発者兼デザイナーで、モーニング・メーカー・ショーの共同司会者でもあります。
現在、PageUI、Clobbr、CronToolなどのアプリケーションを開発しています。
開発者として、遅いAPIほどイライラさせられるものはありません。
コードが動くことは分かっていても、それがもう良いユーザー体験にならないことは分かっているはずです。
私にもそのようなことがあり、2週間ほど見て見ぬふりをしていました。
しかししばらくすると、いくつかの問題は個人的なものになります。
問題は、どこから手をつければいいのか見当もつかなかったことです。
Sentryの新しいトレース・ビューを発見するまでは。
もちろん、トレースこそ、パフォーマンス低下の根本原因を突き止めるために必要なものです。では、このトレース・ビューのトリックひとつで、APIコールのロード時間を22.3秒短縮した方法をお教えしましょう。
この投稿で詳細を説明し、トレースを使って自分のAPIコールのボトルネックを見つける方法を紹介します。うまくいけば、あなた自身のレスポンスタイムを数秒短縮できるかもしれません。さあ、始めましょう!
トレースビューとは?
ほとんどの人は、Sentryのエラー監視機能を知っています。しかし、それだけではありません。実際、Sentryはパフォーマンスのボトルネックを見つけるのにも役立ちます!
Sentryのセットアップがいかに簡単かは前にも述べました。その後、Sentryはパフォーマンス・メトリクスも収集してくれます。
トレース・ビューはその重要な一部で、トランザクションとスパンを滝のように可視化します。ご想像の通り、これはアプリケーションのパフォーマンスに影響を与える遅延、関連するエラー、ボトルネックの特定に役立ちます。
次に、私のユースケースでこれをどのようにセットアップしたかをお見せしましょう。
面白いことに、Sentryは自社のパフォーマンス測定機能を活用したことで、年間16万ドルを節約しました!
ファイルI/Oのトレースビューの設定
私がデバッグしているエンドポイントは、普通のボトルネックではありません。長いHTTPコール、ファイルI/O、サードパーティ・コール(AI生成)、そして最後にDBクエリーがいくつかあります。
問題のエンドポイントはShipixenというアプリのもので、コードベース全体、リポジトリ、コンテンツを生成し、Vercelにデプロイまでしてくれます。
見ての通り、通常のCRUDエンドポイントではありません。
このような状況は、影響を測定することなく毎月毎月機能を増やし続けるエンドポイントによく見られます。
最終的なエンドポイントのボスと呼んでもいいでしょう。
目の前の問題を理解する
ただひとつわかっていたのは、このリクエストのすべてのステップが必要だということでした。バックグラウンド処理にしたり、キューに分けたり、他のアーキテクチャを応用することも考えたが、実際のところは以下の通りです。
- ユーザーが利益を得るのは、すべてのタスクが完了してから。
- ユーザーは王様/女王様であり、私のアーキテクチャなど気にも留めない。
- 私は行動を共にし、リクエストを完了するのにかかる時間を半分にするよう努力する必要がある。
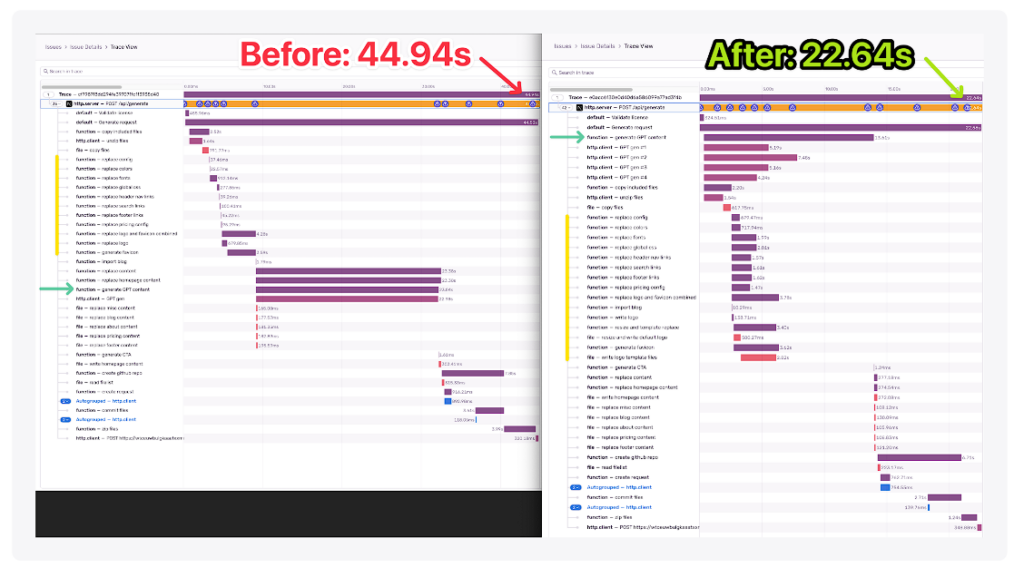
これが、44.94秒という短い処理時間の理由です。
あるいは、平均的なシナリオでこのリクエストを完了するのにかかった時間です。
さっそくデバッグシューズを履いて、トレースビューを開いてみました。驚いた!
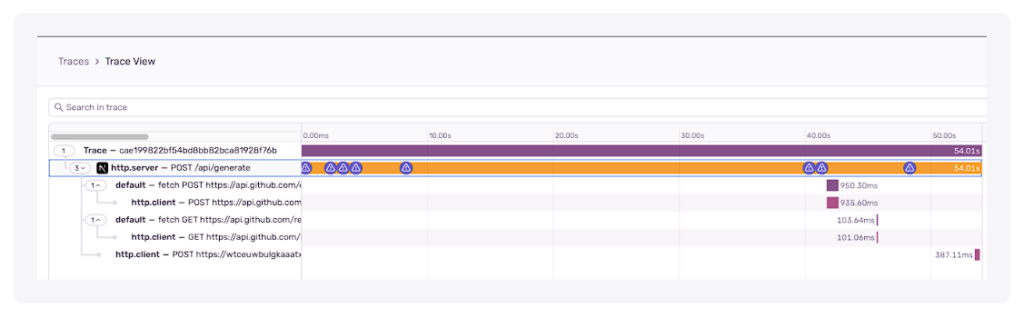
SentryはネットワークI/Oの検出はうまくやりましたが、それ以外はすべてブラックボックスでした。
そしてそれは理にかなっています。
実行中の様々なファイルI/Oをすべてトレースする必要があることを、どうやって知ることができるでしょうか?
54秒かかったという事実は無視して、目の前の問題に集中しましょう。どのタスクに一番時間がかかるのか、さらに重要なのは、どの順番でタスクが完了するのかがわからなかったのです。
カスタム計装の設定
幸運なことにSentryはカスタムインスツルメンテーションを行うメソッドを公開しているので、ファイルシステム上であれ、https上であれ、その中間であれ、あらゆる操作を追跡することができます。
スパンを作成する関数呼び出しで、問題の操作をラップする必要があります。スパンとは、基本的に時間の計測値であり、「起こること」です。”thing “と呼ぶのは少し抽象的なので、スパンと呼ぶことにしました。
お使いの言語やフレームワークにもよりますが、以下のようになります。

そして、メソッドをスパンで囲み始めると、いつの間にかトレース・ビューワーはこのようになっていました。
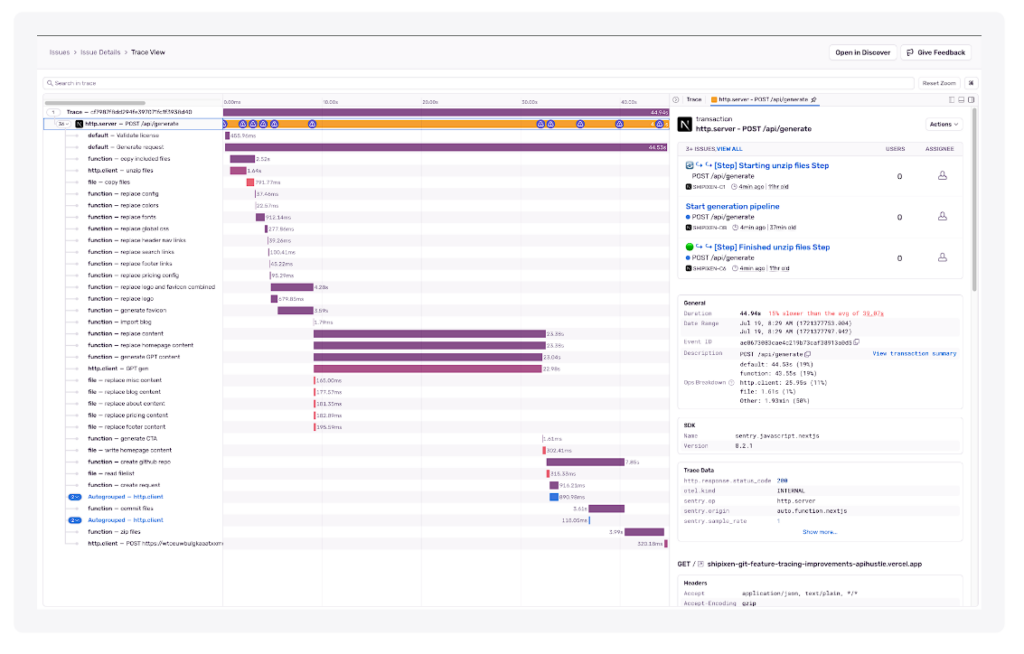
ボトルネックを特定する方法を探ってみましょう。
ボトルネックの特定
この見方をよく見てみましょう。一般的に、これらは最も注意すべき問題です。
- ロング・ラン・スパン
-
- ペイロードを減らすことができるか?
- 複数の並列タスクに分割できるか?
- バックグラウンドで実行できるか?
- より高速で効率的な新しいAPIはないか?
- 互いに待機するウォーターフォール型スパン(並列化可能)
- 互いに待機しなければならない非効率的なスパンオーダー
- スパン間の依存関係
- 最初のバイトまでの時間が遅い / ネットワーク依存のコールドスタート
もしこれがビンゴカードだったら、私がこのラウンドでほとんど勝っていたことに、さらによく見ると気づくでしょう。ほとんど全部持っています。分解してみましょう。
- ロング・ラン・スパン
幸いなことに、あなたの実装には、DBクエリー、サードパーティーの呼び出し、重いファイルI/Oなど、そういったものがたくさんあります。
重要なのは、たくさんあるからといって落ち込むことではなく、どれが簡単に勝てるかを突き止めることです。
私が特定したものを、上から順に紹介しましょう。
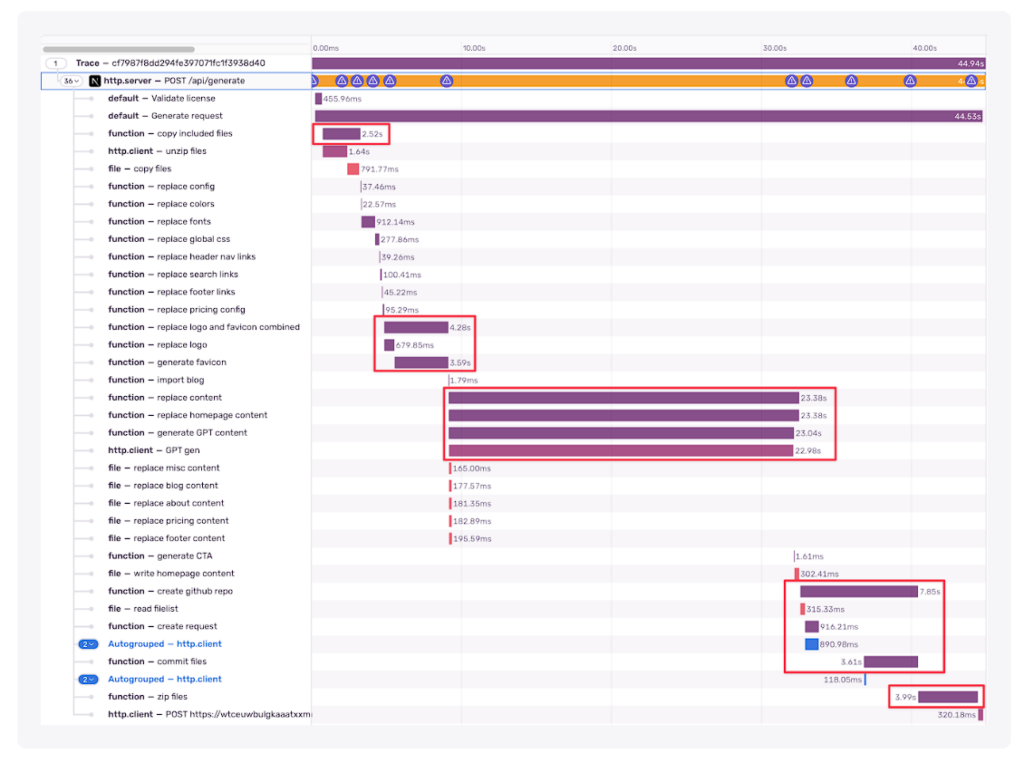
- ❌ 解凍(重いI/O)。zipのサイズ以外、ここで最適化することはあまりないです。楽勝ではありません。
- ✅ 画像処理。これらは並列に実行できますが、順番に実行します。依存関係があるのは明らかですが、おそらく簡単に紐解くことができるでしょう。
- AI生成(サードパーティのhttpコール)。これはきっと、異なるモデルや異なるシーケンスで最適化できます。これを実行するのに8秒近く待つ理由はありません。楽勝でしょう!
- ❌ リポジトリの作成。これはおそらく最適化できますが、上記の解凍ステップとペイロードサイズに依存する可能性が高いです。これも楽勝ではありません。
- ❌ 圧縮(重いI/O)。先ほどと同じで、すべて最初のzipサイズに関連しています。
- Ɨ DBへの問い合わせ。DBは300ms以内に更新されるので、クエリを最適化しても得るものはあまりないです。
これに基づいて、私は20%の努力/80%の利得のカテゴリーにありそうなものを選びました。このテーゼが正しくないことが証明されたとしても、私には(プランBとして)最適化するためのより困難なスパンが残っています。
- 互いに待機するウォーターフォール型スパン(並列化可能)
明らかに理由もなくお互いを待っているスパンのグループを見つけるのは簡単です。それらはおそらく簡単に並列化できるでしょうが、これは少し厄介なことになります。
リソースのボトルネックのために、何かを順番にやったほうが速いこともあります(CPU、メモリ、書き込み/読み込み速度の上限を想像してみてください)。それでも、試してみる価値はあります。
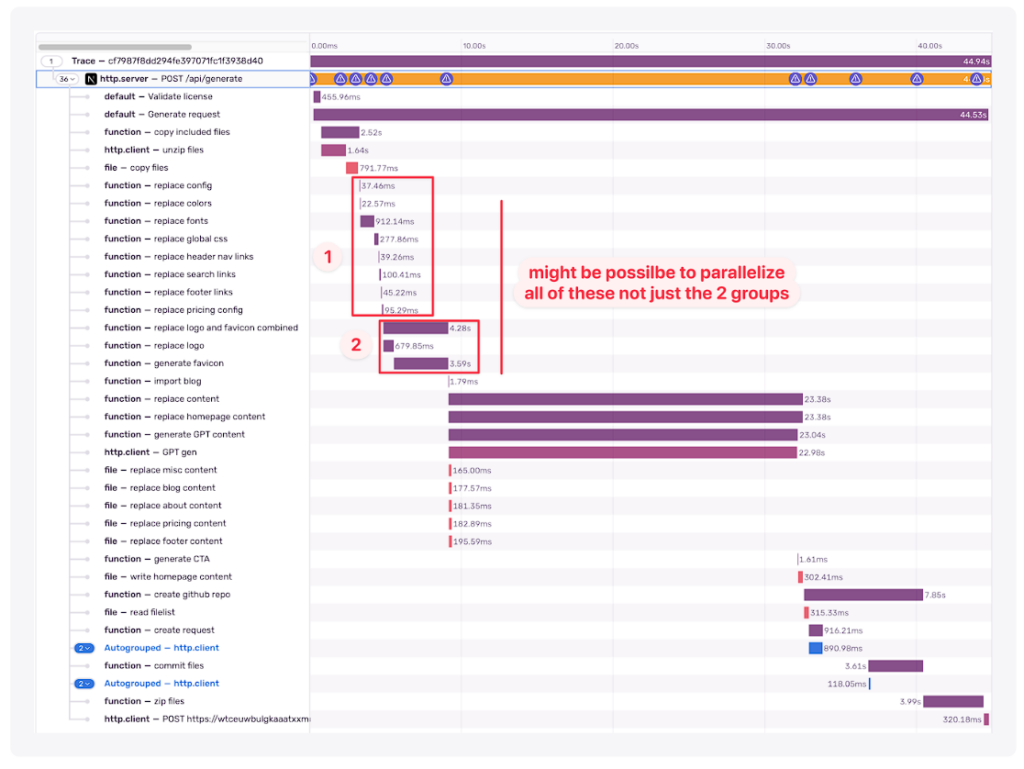
- 互いに待たされる効率の悪いスパンオーダー
これには通常、既成概念にとらわれない発想が必要です。タスク間の依存関係を見たとき、リクエスト開始時にキックオフできるものはないでしょうか?
常に可能というわけではありませんが、私はここで、AI生成タスクは最初からキックオフできるのではないかと直感しました。
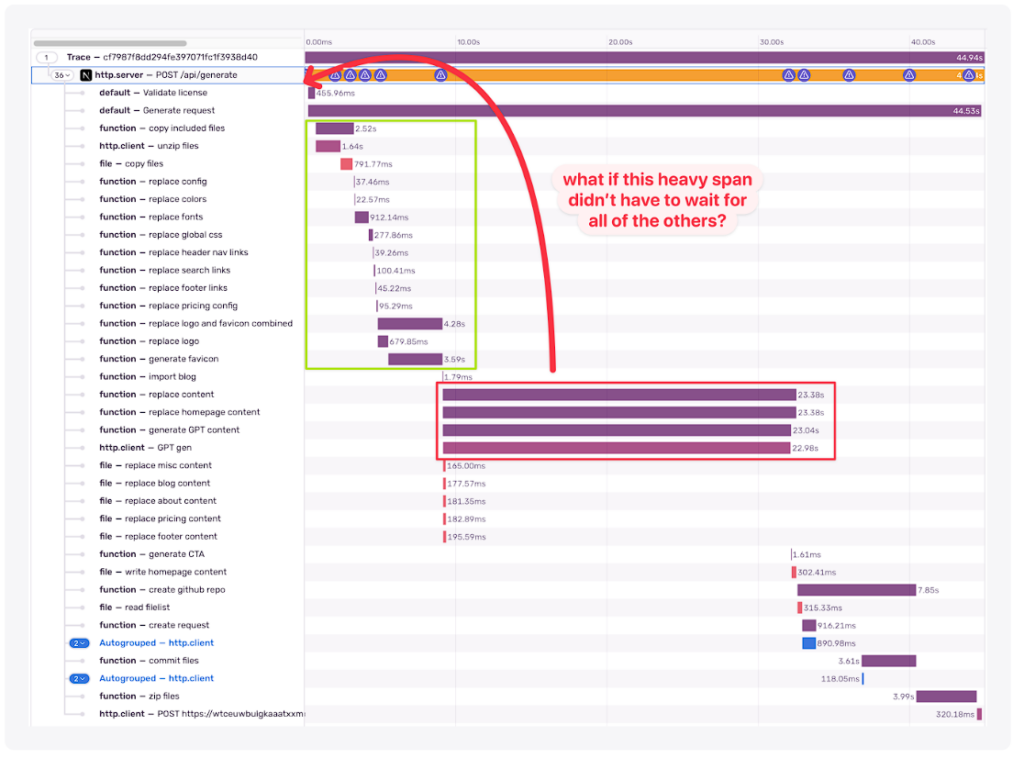
- スパン間の依存関係(通常はコードスプーム)
もちろん、私のコードにはスパゲッティや匂いはありません。しかし仮に、奇妙な依存関係を調べることで、書き直すべきずさんなコードがあることがわかるかもしれません。
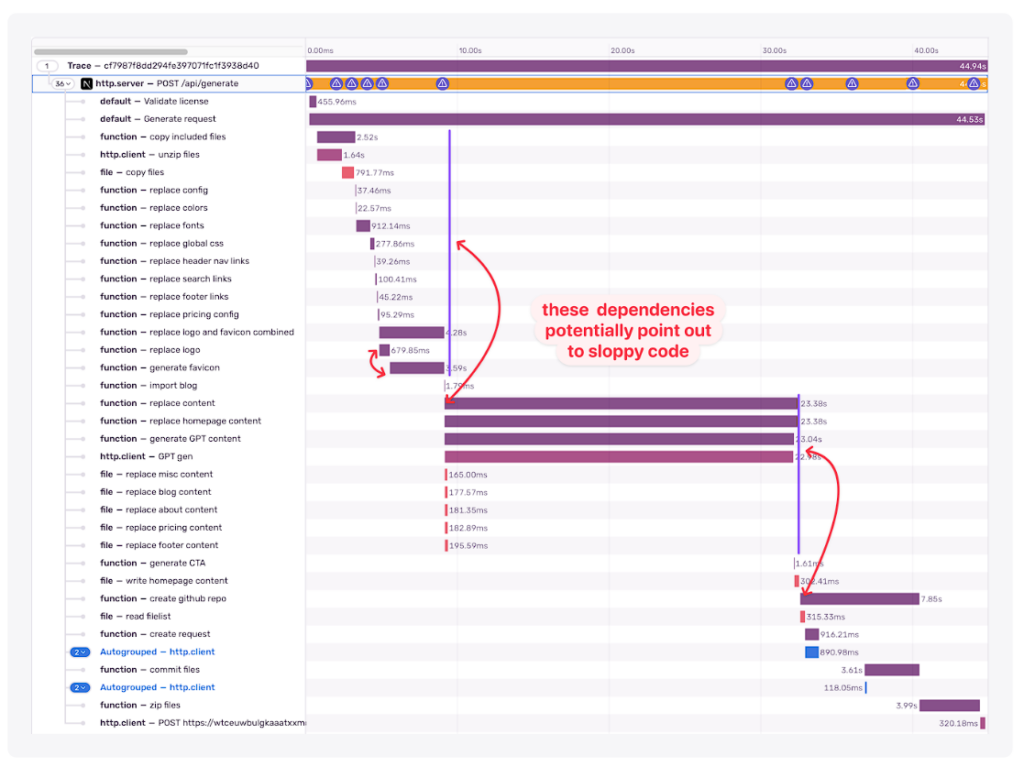
一般的に、パフォーマンスの最適化は、コードをクリーンアップし、将来のためにリファクタリングする良い方法です。
- 最初のバイトまでの時間が遅い/ネットワーク依存のコールドスタート
もしあなたがいくつかのマイクロサービスを呼び出しているのであれば、これは問題になるかもしれません。幸運なことに、私はこの問題を抱えていないようです。
パフォーマンス最適化の適用
レシピを簡単に説明しましょう。
- ベースライン測定
- 再現可能な例を設定する
- 一度に1つのことだけを適用する
小さなステップをすべて説明するつもりはありませんが、意味のあるステップをいくつか紹介しましょう。
非連結スパンの並列化 [42.48秒]
コードを見ると、順番に実行される初期スパンは、画像処理部分を除いて、お互いに依存関係がないと言うことは簡単でした。
比較的小さな変更で、スピードは-5%でした。最悪のスタートではありませんでした。
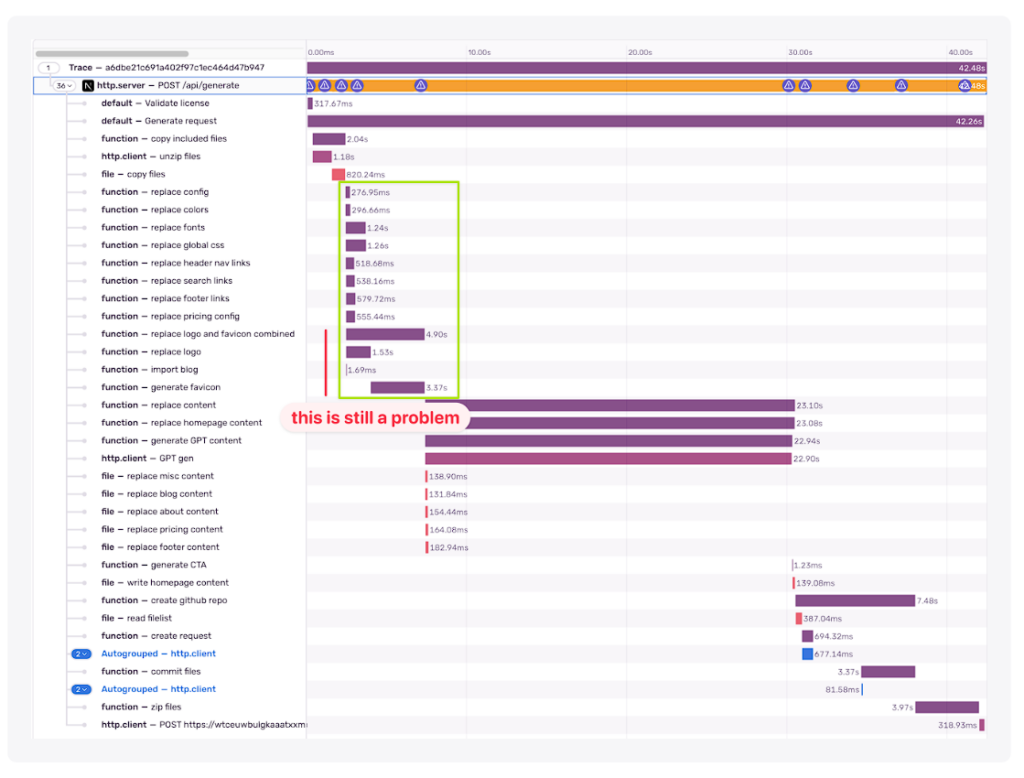
ひとつ注意しなければならないのは、画像処理ステップには2つの子スパンがあり、並列に実行されていないことです。この2つが結合しているのは奇妙に思えるので、それが気になりました。
画像処理の並列化 [41.98秒]
この時点で、依存関係が当初考えていたよりも深かったことに気づきました。つまり、見事に失敗したわけですが、同時にコードの悪さも明らかになりました。

このため、私は小さなリファクタリングを行い、タスクを複数の独立したステップに分割しました。
パフォーマンスの向上は微々たるもの(3.8秒 vs 4.28秒)でしたが、コードの大雑把な部分をきれいにできたことに感激しました。

AI世代のモデルチェンジ[35.87秒]
前述したように、サードパーティの https コールを再評価することは良いことです。時には、API の新しいバージョンや新しいモデル、あるいは全く新しい API が登場することもあります。今年の初めに、私はGithubのREST APIからGraphQLに変更し、ファイルをコミットする際の呼び出し回数を大幅に減らしました。
いくつかのOpenAIのモデルで実験してみましたが、最新の(その週に発表されたばかりの!)gpt-4o-miniは、このタスクのパフォーマンスがかなり速いようでした(約6秒速い!)。

しかし、安定性に欠けることに気づきました。
3世代に1世代は失敗していました。
gpt-3.5-turboのように確実に、タスクに必要な完全なJSON構造をすぐに生成することができなかったのだと思います。
しかし、私はこの改善が必要だと思ったので、ある計画を思いつきました。
同じ入力に対して、この1つのOpenAIの呼び出しを4つに分けることができます。
そうすることで、JSONを生成する際の信頼性が高まるはずです(他にもいくつかテクニックはありますが、これは問題を素早く解決するためにお金を使ったのです!)。
正確にはうまくいかなかったが、プロセスはさらにスピードアップしました。
JSONを解析し、万が一失敗したら、フレンドリーなAIが修正できるように、またAPIコールを実行します。
しかし、このようなことをするのはお勧めしません。
おそらく正しいアプローチはJSONモードを使うことでしょうが、そのためにはコンテンツ処理パイプラインの別の部分を変更する必要があります。リスクを冒す価値はないという判断でしたが、近いうちに必ず修正する予定です。
最終的にはこんな感じになりました。

(9.96秒と6.25秒の差は、必要に応じてJSONを修正するのにかかる時間です)
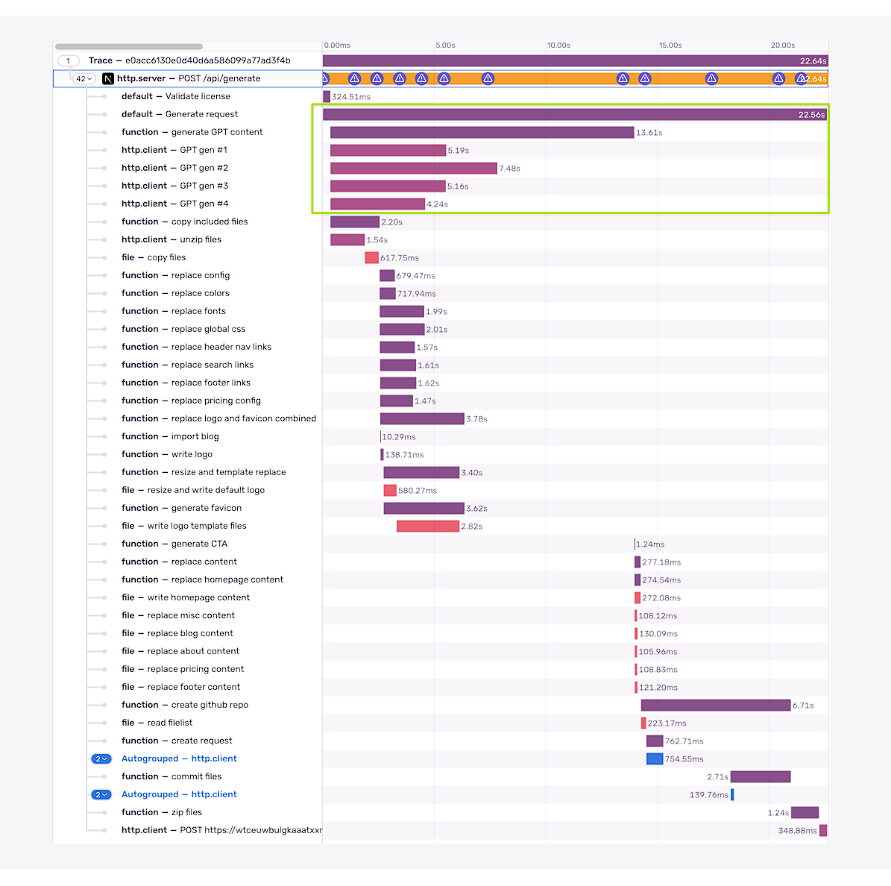
独立スパンの順序を変える [22.64s]
私が適用できる最後の簡単な勝利は、依存関係を持たないスパンの順序を変更することです。
理論的には、AI世代のスパンは最初から実行することができ、コンテンツの置き換え(ファイルI/O)が必要なスパンだけがそれを待つ必要があります。他のすべてのスパンは並行して実行できます。
画像と同様、このタスクにも不要な依存関係があることがわかりました。
手早くリファクタリングして、なんとか一番上に移動させました。そして知っての通り、これは大きな収穫となりました(前のステップに比べて約23%高速化!)。
反省と概要
最後に、さらに最適化するためのアイディアがいくつか残りました。
- 3-5秒 Open AIのJSONモードの使用
- 1-2秒 圧縮/解凍(I/O)
- 0.5-1秒 クライアントでの画像の最適化
全体として、さらに最適化すれば、レスポンスタイムを最大69%速くすることができるということです🤯。
しかし、先を急ぐのはやめましょう。
とりあえず、私が達成したことは以下の通りです。
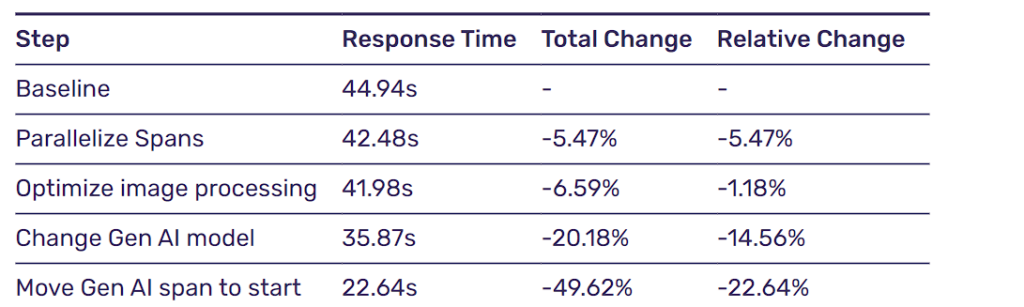
注意深く見ている人は、コミットファイルのスパンのどこかで3秒が失われていることに気づくはずです。なぜでしょう?
Sentryのトレースビューの利点
トレース・ビューが各変更を、このように消化しやすいウォーターフォール・ビューで表示してくれることは、私にとって大きな時間節約になりました。
各反復が全体的なパフォーマンスにどのような影響を与えるか、ロールバックやダブルダウンが簡単にわかりました。
その間に、私が言及しなかったいくつかのステップがありました。
ウォーターフォール・ビューのおかげで、最適化の道を追求するのもしないのもとても簡単になったのです。
ボトルネックに注意
ひとつ気になるのは、比較的速かったスパンがかなり遅くなっていることです。前述したように、並列化しすぎるとシステム(RAM、CPU、FSなど)が限界に達する可能性があるため、収穫が少なくなります。サーバーレス/ラムダ環境では、これは難しい制限かもしれません。
ウォーターフォール・ビューを使えば、これを一目で確認することもできます。
結論
パフォーマンスの最適化だけでなく、コードベースの大幅な改善にもつながりました。おかげで、コードのメンテナンス性とスケーラビリティが向上しました。
最終的には、レスポンスタイムが22.64秒短縮された!
その上、さらに最適化するアイデアがたくさん残りました。トレース・ビューを見れば一目瞭然ですが、あと15~20%は短縮できるでしょう。
時間を確保して、この練習をすることを絶対にお勧めします。
時間が経つにつれて、私たちはゆっくりと、しかし確実にエンドポイントのパフォーマンスを低下させる機能を追加していきます。今できる最も重要なことの1つは、トラッキングをセットアップして、ベースラインを知ることです。
遅いエンドポイントはありますか?私が最適化したのと同じように、きっとあなたも楽しめるはずです!