Article by: Rohan Agarwal
プロファイリングと聞くと「インフラコストをスケールに応じて最適化するためのわずかな節約に役立つもの」という誤解を抱いている方が多くいらっしゃいます。いわゆる「ミリ秒単位での削減が全て」というアプローチだと思っていないでしょうか。
しかし実際はそうではありません。私たちは自社のプロファイリングツールを使用し、ユーザーインタラクションを各セッションにおいて数十秒単位の時間短縮を可能にしました。数学がお好きな方のために補足すると、それは「重要なミリ秒」どころか、4桁も大きく異なる数値でした。
この記事では、私たちがどのような課題に直面し、何を発見し、どのようにして解決に至ったのか解説します。そしてプロファイリングが単なるミリ秒の削減にとどまらず、なぜパフォーマンスや顧客体験の向上に欠かせない存在なのかについてもご紹介します。
処理速度は、開発者にとってもユーザーにとっても重要
私たち Sentry 開発チームは、デバッグワークフローの改善に一貫して取り組んできました。
その中で「生成AIを活用するなら、 Autofix というツールを作るのが最適だ」と考えました。Autofix は問題の詳細とコードベースを密接に統合させ、課題の文脈を理解した上で解決策を導き出すツールです。完全に独立して動くのではなく、開発者と一緒に作業しながら根本原因を特定し、正確なコード修正を提案するという少しユニークなアプローチを取っています。
Autofix の本来の目的は「デバッグを速くすること」でしたが、実際に使用してみるとどうにも遅いと感じていました。特にコールドスタート時は鈍く、通常よりも10〜20秒以上も余計に時間を要し、こうした遅延は私たち開発チームだけでなく、初期導入されたお客様にも影響を及ぼしていました。
このままでは Autofix を世に出しても中途半端なものになってしまうのではないかという危機感が高まっていました。何としてもローンチまでにパフォーマンス課題を解決しなければなりません。とはいえ、AI駆動のワークフローをデバッグするのは困難です。
問題はサードパーティのLLMプロバイダーからの遅延応答が原因なのだろうか。だとすると、設計そのものを変更しなければなりません。それともタスクキュー(Celery)が非力なインフラでボトルネックになっているのか… 仮説を確かめるには大掛かりな調査が必要となり、もし仮説通りだったとしても、その対応にはアーキテクチャ全体を見直すような大規模改修につながります。いずれにしても大変です。
そこでふと考えました。
「もしかすると、私たちがすでに持っている可視化データの中にヒントがあるのでは……?」
そこで登場したのが Sentry Profiling です。早期導入ユーザーの実際のデバイスから実行データを分析することで、思いがけない2つのボトルネック、「冗長なリポジトリ初期化」と「インサイト生成中の不要なスレッド待機」を明らかになりました。これらに対し、キャッシュの導入とスレッドの最適化を行ったことで、実行時間は数十秒短縮され、Autofix は大きく向上しました。しかも、アーキテクチャには一切変更を加えていません。
プロファイルとは?どのように活用すればいい?
もしすでにご存知であれば、ここは読み飛ばしていただいて構いません。念のため、初めての方に向けて簡単に説明します。
プロファイリングとは、関数の呼び出しや実行時間、リソース使用状況などの情報を本番環境でリアルタイムでキャプチャし、実際のユーザー体験に影響しているCPUやブラウザレベルのパフォーマンス課題を特定するための手法です。
CPUプロファイリングはCPUサイクルがどこで使われているか追跡し、非効率な関数や不要なループ、重たいブロック処理などを見つける際に役立ちます。またブラウザプロファイリングは、主にフロントエンドに焦点を当て、ページの読み込みやレンダリングの遅延、長時間実行されているレンダリングタスクなどの情報を取得することが可能です。最後にモバイルプロファイリングは、ネイティブおよびハイブリッドアプリの画面表示などのパフォーマンスを分析します。
これらのデータは全て「フレームグラフ」として視覚的に表示され、時間経過とともに変化するコールスタックの様子を確認できます。最初は少し慣れが必要になるかもしれませんが、以下のように読み取ることができます。
- X軸(時間):コード実行のタイムラインを示します。各ブロックの幅は、関数呼び出しの時間の長さを示します。
- Y軸(コールスタックの深さ):関数呼び出しの階層を示し、コードレベルでの関数間の親子関係を示します。
- カラーコード:Sentry ではアプリケーションコード、システムコード、シンボル名、パッケージなどに色分けがされており、それぞれを直感的に識別できます。
さらにプロファイルは分散トレースと組み合わせて表示することもできるため、ブラウザ、クライアントCPU、ネットワーク呼び出しの流れをひと目で把握できるようになります。Sentry では個別のプロファイル(単一トランザクションのプロファイル)、集約されたプロファイル(平均的な処理の傾向)、差分プロファイル(コードの変更前後の比較)といった形式でパフォーマンス問題を素早く特定できます。
プロファイリングを有効にするには、アプリケーションの起動時にSDKをできるだけ早く初期化し、profiles_sample_rate オプションを 1.0 に設定することでサンプリングされたトランザクションをキャプチャできます。
例えば、Pythonアプリでは次のように設定します。

問題1:コールドスタートに時間がかかる
問題
Autofix の目的は、アプリケーション内のバグについてできるだけ早く開発者にインサイトを提供することです。しかしルートコード分析を行ったり、コード修正を提案したりするたびに数秒もの明確なスタートアップの遅延が発生し、その後も長時間の処理が続いていました。
これでは最先端のAIエージェントとしては動作が重く、時代遅れに感じられてしまいます。この状況が改善されなければ、開発者はワークフローへの不満を抱き、Autofix が低く評価されてしまう恐れがありました。
これらの遅延は実際に、分散トレースではっきりと確認できました。
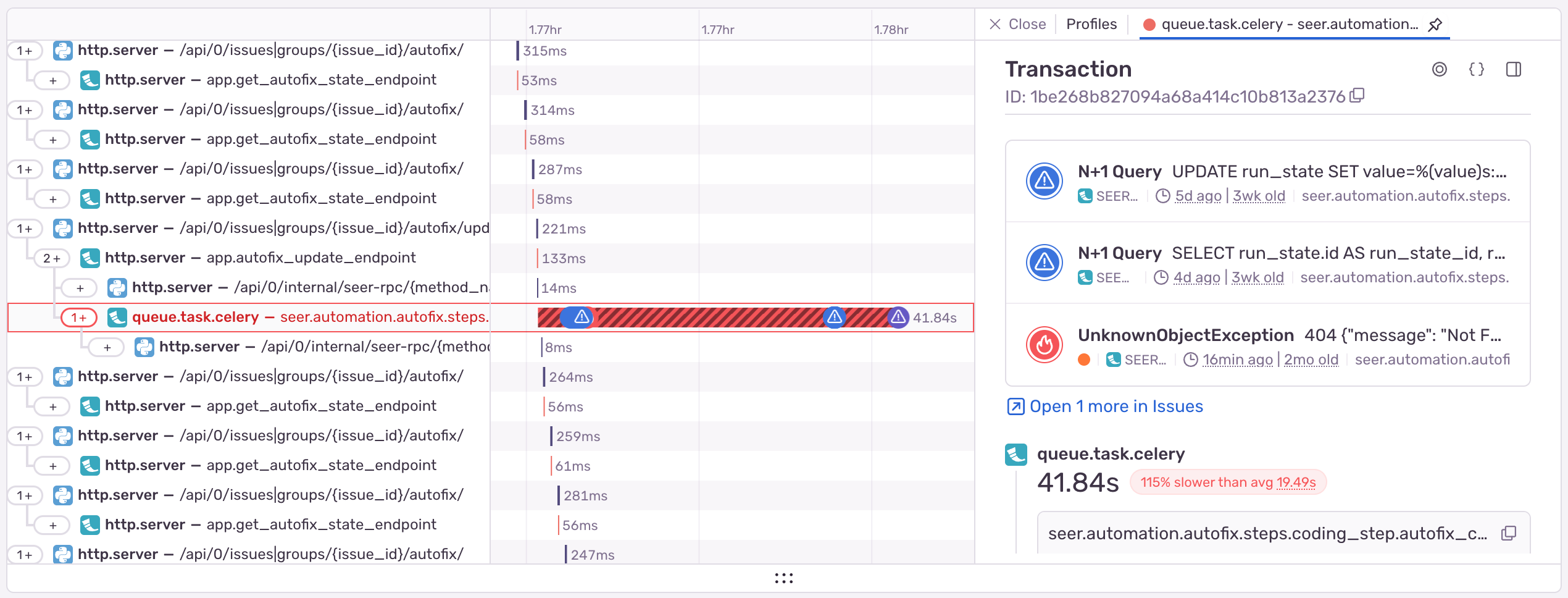
原因
通常、この調査はアーキテクチャやデザインの会議から始まり、行ごとのログを追加したりコード内にブレイクポイントを設置したり、様々な仮説を検証することになります。しかし今回は、私たちのAIサービス「Seer」が Sentry Profiling で計測されていると知っていたので、最近 Autofix で実行されたプロファイルを確認し調査を始めました。
その結果、フレームグラフは全く予想していない事実を示していました。from_repo_definition というメソッドが、開発者の GitHub リポジトリと統合するために何度も呼び出されていたのです。
スタックトレースの処理中や修正ステップの開始時、さらにはコードファイルを確認するたびに毎回このメソッドが使われていました。そしてさらに、1回ごとに1秒以上の遅延が加わっていたのです。
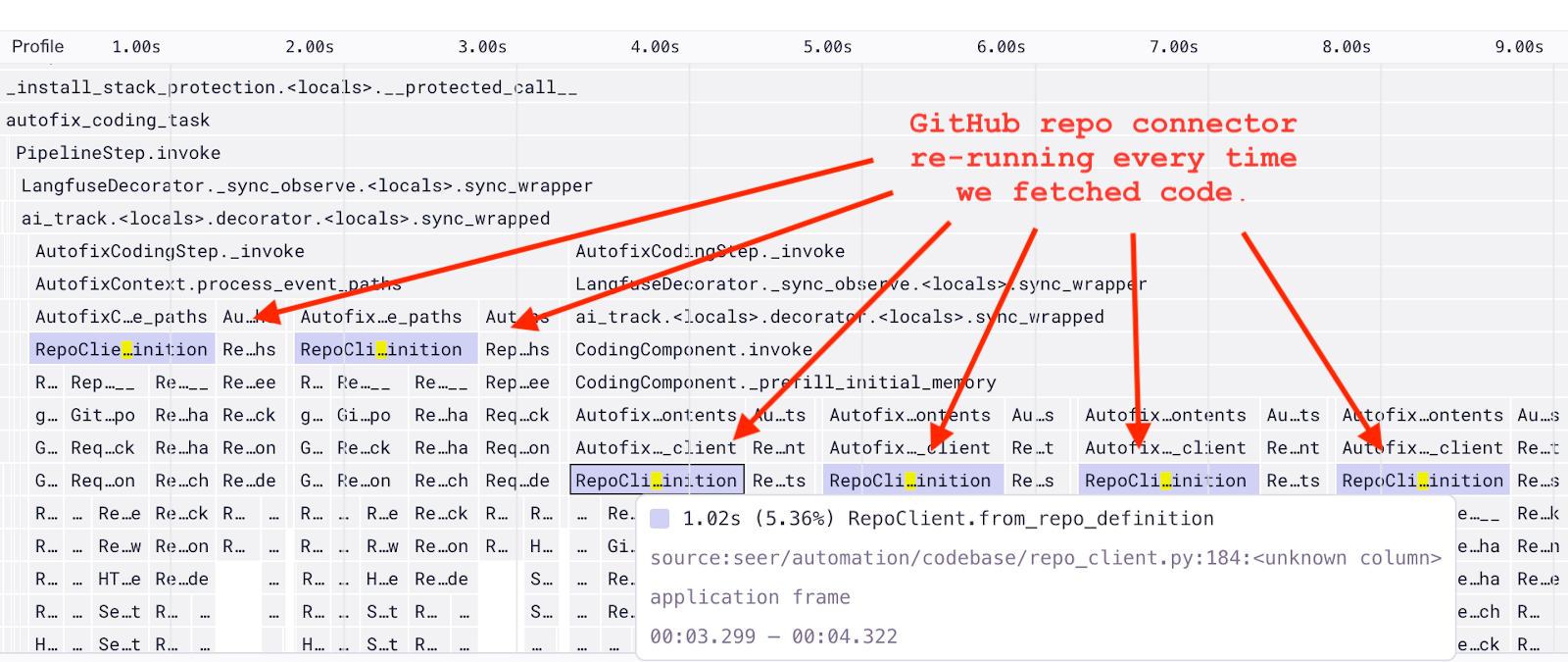
このシンプルな可視化によって、コードが実際にどのように動作しているのかをすぐに理解することができました。まさかこれがボトルネックになっているとは思っていませんでしたが、コールドスタートや実行時間を短縮できる大きな変更すべき箇所をすぐに特定できました。
修正
フレームグラフで強調表示された関数を開くと、同じリポジトリに対して統合クライアントが何度も初期化されていることがわかりました。各クライアントの初期化時に GitHub に HTTP リクエストを送っており、これが遅延を引き起こしていました。
対応自体は非常にシンプルでした。リポジトリへのアクセスが必要なすべての箇所で、同じ from_repo_definition メソッドを呼び出すよう統一し、そのメソッドに @functools.cache デコレーターを1行追加しただけです。これにより、同じリポジトリとのやり取りが複数回発生しても、毎回初期化を待つ必要がなくなりました。

その修正後、from_repo_definition メソッドが開始時に一度だけ呼び出されることを確認しました。これで問題なく動作します。
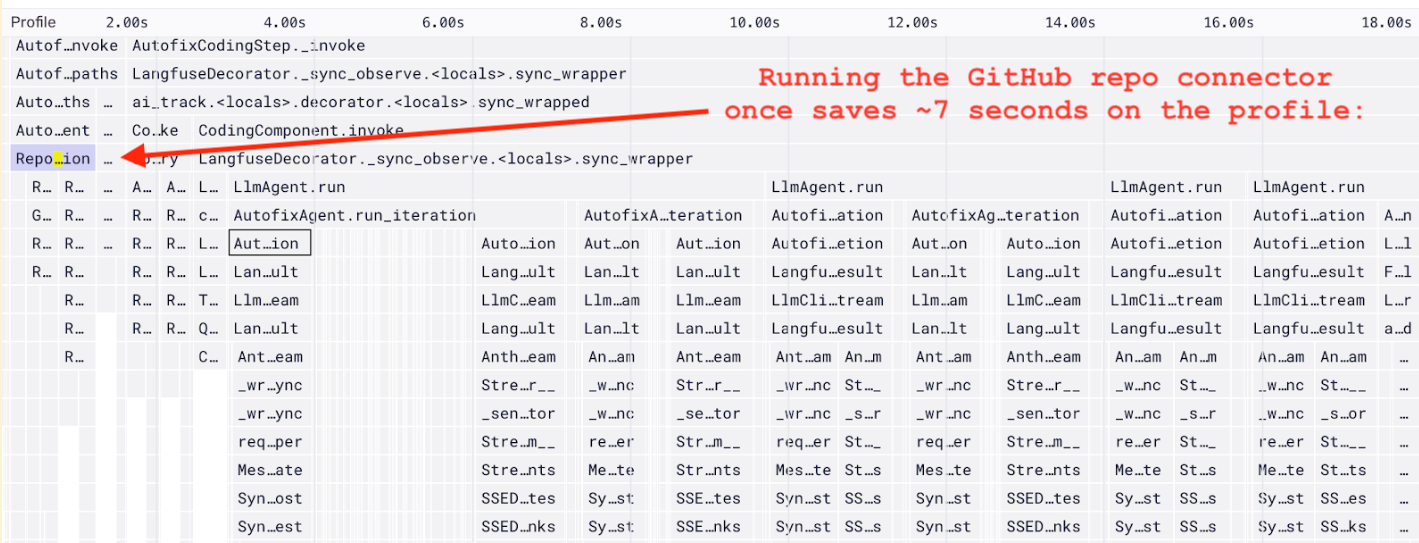
結果
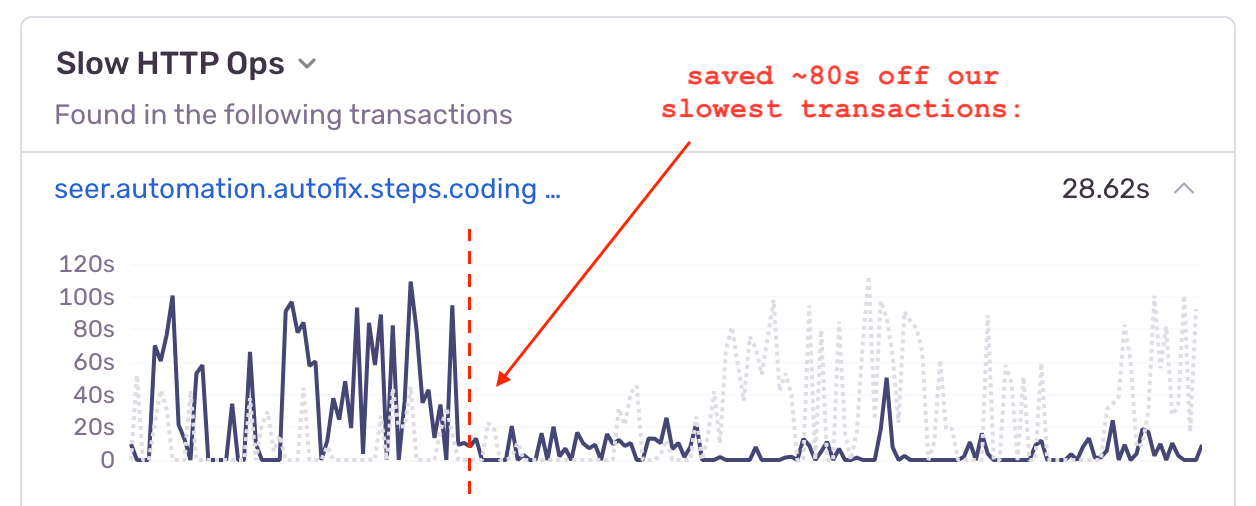
Sentry Profilingのおかげで、何ヶ月も悩まされていた Autofix のコールドスタートと遅延を、わずか20分足らずで劇的に改善できました。
具体的に節約された時間をご紹介します。
- Autofixがコードファイルを確認するたびに約1秒(実行中に何度も発生)
- Autofixのステップが開始される前に約1.5秒
- コーディングステップを開始前にさらに約5秒
以上の時間を削減することができました。
これにより、Autofix は非常にスムーズに動作し、開発者もこれまで以上に短時間でデバッグできるようになりました。この効果は Backend Insights にも明確に示されています。
問題2:冗長なスレッド
問題
前回の改善に手応えを感じたことで、他の潜在的な問題も容易に見つけられるのではと思い、Autofix のコーディングステップに関する別のプロファイルを開いてみました。
さらに Autofix のパフォーマンスを改善できるかもしれないと考えたのです。予想通りすぐに新たな問題点を発見することができました。
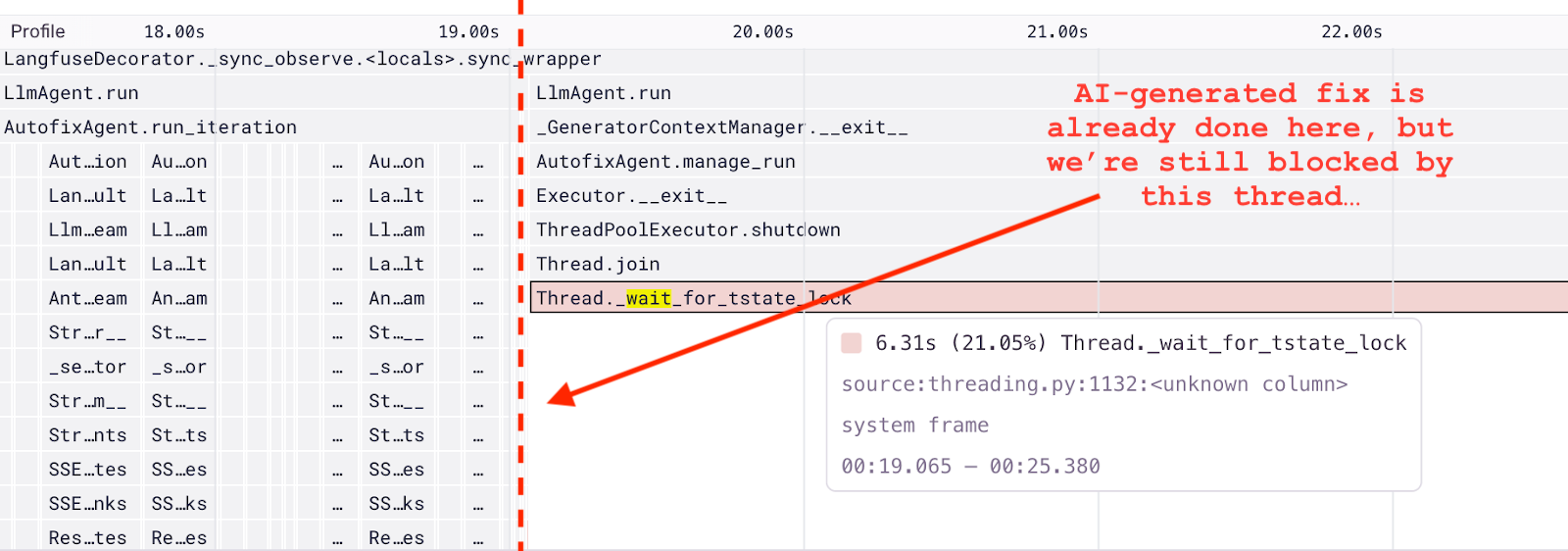
フレームグラフには、スレッドが完了するのを待っている大きなブロックがありました。6秒以上もかかっており、Autofix が何もしていない状態で開発者が最終的な出力結果をただ待っている状態であることがわかりました。
原因
Autofix は最終的な結論に至る前に、実行中に途中の推論内容をインサイトとしてユーザーへ共有します。このインサイトの生成には毎回数秒かかるため、メインエージェントとは別のスレッドで並行して生成しています。安全のため、スレッドが完全に終了するのを待ってから処理を終了する設計にしていましたが、実際のインサイト生成コードを確認した際、「なぜエージェントの処理終了後も完了を待っているのだろう?」という考えに至りました。
調査をしていくうちに Autofix が最終的な答えを出した後も、それまでの反復処理と同じように新しいインサイト生成タスクを開始していたことに気付きました。しかしこれは無意味な処理で、すぐに最終結果を表示するため生成されたインサイトは結局同じことを表示させているのです。
またインサイト生成タスクが1つのスレッドワーカーしか使用していなかったため、それが実行の最後でさらに待機時間を増やしている要因にもなっていました。
修正
プロファイルを通じてコードの挙動を把握した上で、関連するコードを調べた結果、修正は簡単でした。
実行終了直前に新しいインサイト生成タスクを開始しないように条件を追加し、スレッドワーカーの数を2つに増やします。


結果
この修正により、各 Autofix ステップの最後に発生していた6秒の遅延を完全に排除でき、開発者はより早く結果を受け取れるようになりました。さらに副次的な効果として重複したインサイトを減らし、共有される情報の価値を高めることができました。
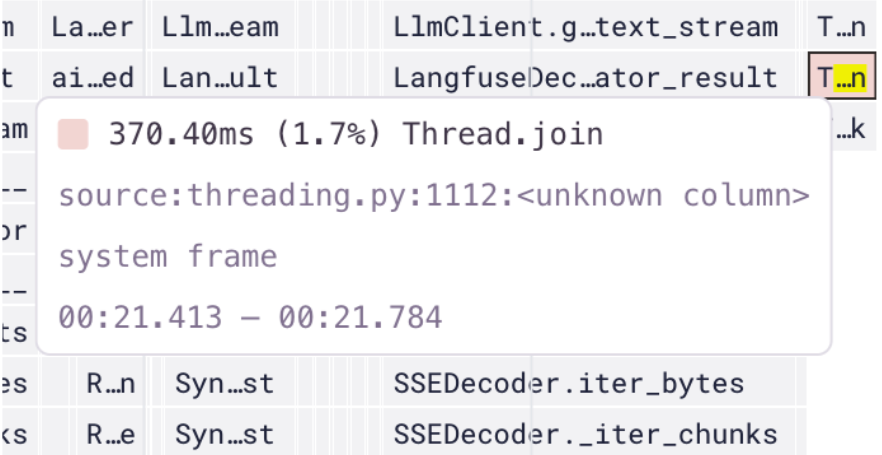
Sentry Profiling によって明らかになったこれら2つの改善点によって、Autofix の総実行時間をおよそ20秒近くも短縮することができました。
プロファイリングは難しくない
コールドスタートや処理遅延の原因は、ちょっとした不注意で簡単に見落とされてしまいます。もし気づくことができなければ、Autofix のパフォーマンスが低下しサービスに対する第一印象は台無しになっていたことでしょう。
プロファイリングがなければ、問題を完全に見逃していた…あるいは発見が遅くなっていたと思います。手動でデバッグすることも不可能ではなかったでしょうが、成功していたかというと疑問が残ります。おそらく無理だったでしょう。
ログを1行ずつ確認し、コードに計測処理を追加し、タイミングを見計らって操作し、スレッドを追跡することになります。そんな苦労をせずに済んだのは Sentry のおかげです。専用のトレース、スタックトレース、プロファイルを使えば、ほんの数分で問題と原因を特定できます。
今回の場合、冗長な from_repo_definition の呼び出しと不要なスレッド待機の時間でした。キャッシュの導入とスレッド処理の最適化によって AutoFix の実行時間は20秒以上短縮され、ユーザー体験は格段によくなりました。
プロファイリングは、CPUの無駄を削ってミリ秒単位の改善を目指すものではありません。コードが実際にどのように動作しているかを理解し、起きている問題に向き合うための強力なツールです。非効率な処理を正確に特定し、実行可能なインサイトへと変換してくれる存在です。
たったの10分で10秒の遅延を取り除いた「ユーザー体験が向上している未来」を想像してみてください。それこそが Sentry Profiling が私たちにもたらしてくれた成果です。次はあなたの番です。
数行のコードで簡単にプロファイリングの設定が行えます。詳細な手順については製品のウォークスルーをご覧ください。まだ Sentry アカウントをお持ちでない場合は、無料で作成できますので、こちらからお試しください。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。