プロファイリングは、最も重要なツールです。
プロファイリングを利用することで、本番環境で実行中のプログラム情報を詳しく見ることができます。
パフォーマンスのボトルネックは、ローカルで再現するのが非常に困難であったり、不可能であったりすることがよくあります。そのため、この機能はとても重要なのです。
再現が困難である理由は、外部制約や本番環境特有の負荷が理由にあります。
Pythonは、最も人気のあるプログラミング言語の一つです。
SentryもPythonをメインに開発しています。Pythonのプロファイリングは現在ベータ版です。しかし、sentry-sdk==1.11.0を利用することでWSGIアプリケーションで利用可能になります。
これにより、実運用でのアプリケーションのパフォーマンスについて、コードレベルで把握することができます。
Pythonのプロファイリングを始めるには、SDK上でprofiles_sample_rateを設定するだけです。
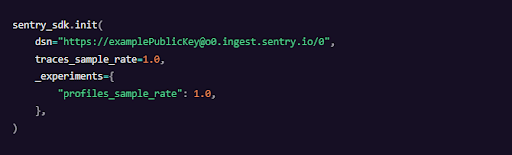
SDKは100ヘルツのサンプリング周波数でサンプルを取得する別スレッドを実行します。
プロファイルが終了すると、サンプルはSentryに送られ、プロファイルがフレームチャートとして可視化されます。
フレームチャートは、エンドポイントや遅いトレースにおいて、頻繁に実行されるコードを素早く見つけ、リソース消費(例:CPU)を最適化することができます。
SentryプロファイリングでSentryを改善する
長い間、Sentry上でPythonプロファイラの内部バージョンを実行することで、Sentryを最適化することができました。
日付時刻と連携
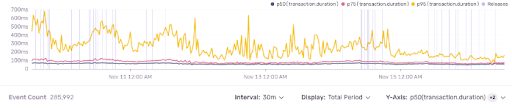
多くの人は、時系列で確認できることほど嬉しいことはありません。そのため、Sentryの様々なところで時系列グラフを用意しています。しかし、時系列グラフの生成には時間がかかります。
処理が重い箇所を調査したら、 discover.discover – timeseries.transform_results が原因である可能性があることがわかりました。
さらに調査を進めると、この関数が本当に原因であることがわかりました。
たまに数百ミリ秒の遅さになることがあり、これはデータ取得のクエリよりも遅いです!
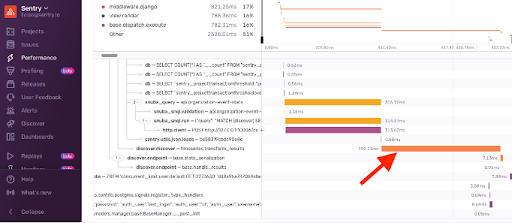
実はクエリよりも後処理の方が遅いんです!
コードを見ると、単純な変換をしているだけでした。そのため、根本的な原因はすぐには分かりませんでした。しかし、プロファイルを見ると、リクエストの大半が、ゼロフィル(データが全て0埋めになっている状態のこと)内で日付のパース処理だということがわかりました。
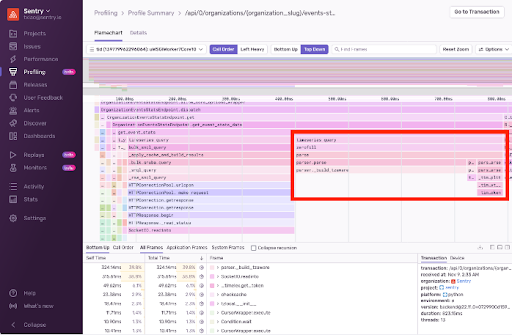
ゼロフィル内の日付時間のパース処理でした!
これを知った時は驚きました。
検証するために、いくつかの簡単なベンチマークを行ました。また、日付と時刻の文字列をパースするいくつかの方法を比較してみました。
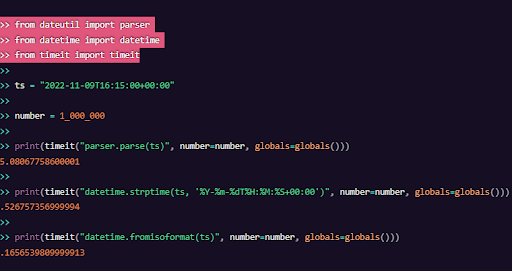
それは衝撃的事実でした。なぜなら、dateutil.parser.parseからdatetime.datetime.fromisoformatに変更することで、数百倍速くなる可能性があるからです!
datetime.datetime.fromisoformatは完全なISO 8601通りのパース関数ではありません(とりあえずはPython 3.11までは)。しかし、我々はdatetime.datetime.isoformatに満足していました。なぜなら、この一行を変更するだけで、最悪な状況が大幅に改善されるからです。
Django:プリフェッチするかしないか
プリフェッチはDjangoでよく採用されるテクニックです。
これは、関連するオブジェクトにアクセスする時に、大量にデータベースクエリが発生するのを防いでくれます。
オブジェクトごとに1つのクエリを作る代わりに、プリフェッチすることによって、関連するすべてのオブジェクトを一度に取得する一つのクエリを作ることができます。
Sentryの様々な場所でこの技術を採用しています。しかし、ユーザーのエンドポイントが非常に遅いことに気づきました。大きな影響を与えずに、関連するオブジェクトにプリフェッチを使用するようにしました。
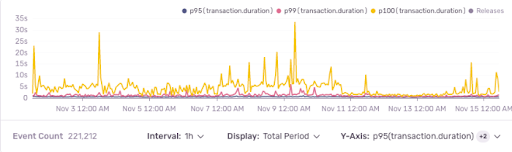
いくつかのトランザクションを見ると、興味深いことがわかりました。
それは監視できていない期間があったのです。さらに最も興味深いのは、それがいくつかのデータベーススパンに散らばっていたことです。
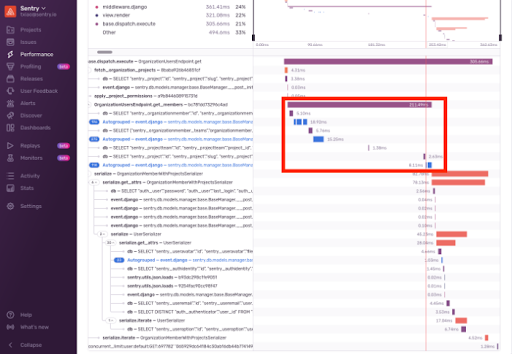
また、コードを調べてみると、これらのデータベーススパンは以下のクエリに対応していることがわかりました。
最初のクエリはOrganizationMemberに対するもので、それに続く3つのクエリはprefetch_related内で指定された3つのルックアップに対するものです。
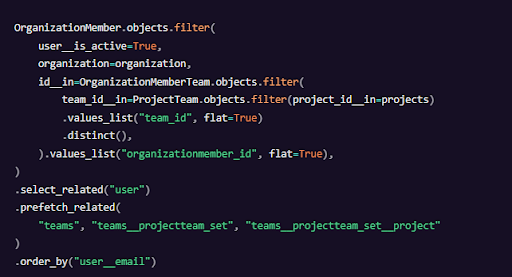
プロファイルを調べると、prefetch_related_objectsがありました。これはDjangoの内部呼び出しで、リクエストの大部分を占めています。
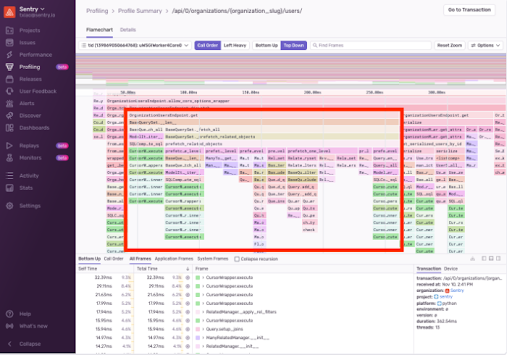
OrganizationMemberとTeamの間の多対多の関係、そしてTeamとProjectの間の多対多のリレーションクエリをしていたことがわかりました。
prefetch_relatedを使ったクエリは高速でしたが、Djangoは結合処理を実行していました。つまり、一部のチームとプロジェクトを取得しただけですが、 DjangoはすべてのOrganizationMember、Team、Projectを繰り返し、関連するオブジェクトを属性として設定していました。
この知識をもとに、クエリの書き換えに取り掛かりました。
Pythonでこの結合処理を実行したくはなかったのです。prefetch_relatedを削除し、関連するオブジェクトを手動でフェッチし、レスポンスを丁寧に構築することで、これを達成することができました。これにより、p95は50%近く減少しました!
プロファイリングはパフォーマンスを補完する
プロファイリングは、Sentryパフォーマンスを完璧に補完します。
パフォーマンスが問題を大まかに把握することができますが、プロファイリングは正確なプログラムのコード行番号まで把握することができるので、簡単に問題を解決することができます。
コードのプロファイリングをできるようにするために、まずすべてのサービスをSentryのパフォーマンス製品で接続するようにしました。
Sentryは、サービス全体のレイテンシー問題を把握することができます。 これにより、プロファイルとトランザクションを簡単に関連づけることができ、遅いリクエストの根本原因を特定することができます。
パフォーマンスのダッシュボードは、アプリケーションがどのように動作しているかのを把握するのにも役立ちました。プロファイリングを導入する前と導入した後を比較すると、P75の時間やスループットなどを簡単に把握することができました。
早速いまからプロファイリングを始めてみましょう。
最初に「パフォーマンスを計測する」を確認してください(わずか5行のコードで可能です)。
また、より多くのSDKコミュニティやユーザーの皆さんにプロファイリングをご活用いただくため、ぜひご意見をお聞かせください。
Sentryは、アプリケーションコードの健全性を監視するために不可欠です。エラートラッキングからパフォーマンスモニタリングまで、開発者は、フロントエンドからバックエンドまで、アプリケーションをより明確に把握し、より迅速に解決し、継続的に学習することができます。
Sentryは、世界中の350万人以上の開発者と85,000以上の組織に愛され、Disney、Peloton、Cloudflare、Eventbrite、Slack、Supercell、Rockstar Gamesといった世界的有名企業の多くにコードレベルの監視機能を提供しています。
毎月、世界中で人気のサービスやアプリケーションから、数十億件の例外を処理し続けています。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。