この1年間、我々はCronを構築してきました。
小さなプロトタイプから始まったこの機能は、Sentryのエラー、パフォーマンス、信頼性モニタリングツールの本格的な機能へと生まれ変わりました。
この機能自体はまだベータ版ではありますが、すでに1日あたり700万以上のチェックインを受け付けています。
このような規模が大きくなった機能なので、信頼性を保証する方法について慎重な決断が必要でした。
早期実施
Sentryの新しいCron監視機能とは、スケジュールされたジョブ(例:古典的なcronjobs、celery beatタスク、Sidekiq、Laravel Scheduled Tasks、あるいはsystemdタイマー)が通常通り動作しているか、あるいは実行に失敗したシナリオを検証し、アラートを出す方法のことです。
これは、スケジュールされたタスクが “check-in “イベントを介して私たちに通知することで機能します。
- Missed:予定時刻にチェックインしなかった場合、「チェックイン漏れ」となる
- Timed-Out:進行中のチェックインが完了しなかった場合、「タイムアウト」となる
- Error:status=errorのチェックインを送信すると、明示的にエラーとしてマークされる
最初のプロトタイプでは、チェックインの取り込みはDjangoアプリケーションに組み込まれたいくつかのAPIエンドポイントによって処理されていました。
物事をシンプルに保つために、チェックインは単に Postgres テーブルのエントリとして記録されます。
チェックイン漏れを検出するために、1分間に1回、celery beatタスクを実行して、予定時刻にチェックインがなかったモニターを探すだけです。タイムアウトの検出も同様です。
しかし、この最初のプロトタイプをアーリーアクセスユーザーに提供できるようにしたのは、今年に入ってからでした。
アルファ版の機能であっても、私たちはすぐに勢いを取り戻し、信頼性とスケーリングについて考える時が来たということです。
インジェスト・インフラストラクチャー
私たちが最初に解決しようとした問題は、チェックインの取り込みでした。
私たちのSDKが使用するAPIエンドポイントは、可用性が高く分散されています(私たちの分散取り込みインフラであるRelayを使用しています)。
しかし、私たちのフロントエンドを駆動し、プロトタイプのエンドポイントが実装されたSentry製品のAPIは、このような保証がありません。
Relayが可用性を向上させるだけでなく、Relay経由でチェックインを実装するもう一つの大きな利点は、私たちのSDK群全体でCronチェックインを作成するためのサポートを迅速に実装できることです。
これはRelayが統一された「エンベロープシリアライゼーションスキーマ」を使用しており、SDKが任意のイベント(もちろん最も一般的なのはエラーとトランザクションです)をRelayのポイント・オブ・プレゼンスに簡単に渡すことができるためです。
Cronのチェックイン・インジェストをRelayに移行するのは当然のことでしたが、プロトタイプのインフラを大きく変更する必要がありました。
この改良された世界では、Relay は SDK からのチェックインイベントを受け付けます。これは従来の curl スタイルでのチェックイン用の API エンドポイントも提供します。
これらのチェックインは検証され、正規化され、Kafkaトピックに入れられます。
これにより、処理できるチェックインの量をスケールアップするためのノブをすぐに回すことができます。以下のようなイメージです。
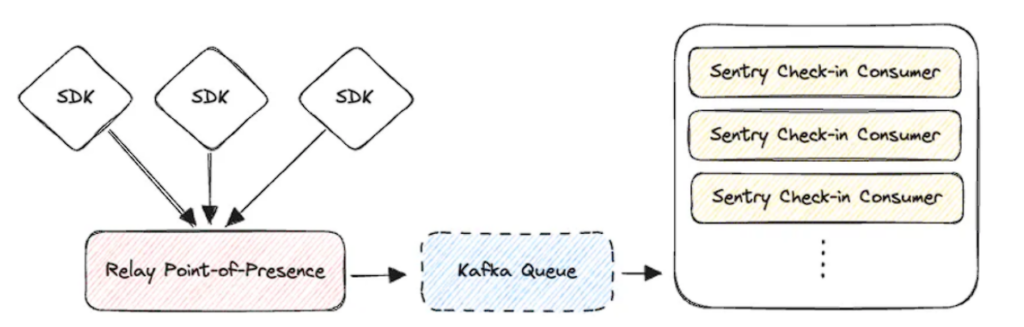
このアーキテクチャにより、ユーザーのチェックインを失うことなく、コンシューマーの問題を確実に回復することができます。Kafkaは問題のあるシナリオでもチェックインのバックログを維持することができ、負荷の要求に応じてコンシューマーの数を微調整することができます。
チェックイン漏れを確実に検知
Cronのインジェストインフラストラクチャの可用性が改善されたので、私たちはチェックイン漏れ検出の信頼性に注目しました。
Sentryは通常、プラットフォームに送られたデータを処理します。
未チェックインの検出は、我々のインフラにとって斬新な領域です。
1分間に1回のCelery beatタスクを使ってチェックインを検出するというプロトタイプのアプローチには、2つの大きな問題があることがすぐにわかりました。
Celery beatスケジューラのデプロイ中に、タスクがスキップされる短い期間があります。
これは、1分間に1回のチェックイン・プロデューサ・タスクが、特定の1分間実行されないことがあることを意味します。
このシナリオでは、すべてのユーザに自分のモニタのチェックインミスが通知されません。
Kafkaメッセージのバックログシナリオで、1分以上バックログしている場合、成功したチェックインが単にバックログにあるだけで、まだ処理されていないスケジュールされた時間のチェックインミスが発生する可能性があります。
これらはどちらも問題があるだけでなく、エンドユーザーを混乱させます。
私たちの目標は、モニターが停止したことを確実に伝えることなので、ミスしたチェックインを正しく検出することが重要です。
では、チェックイン漏れをチェックするタスクが、1)毎日毎時毎分、無期限に実行され、2)チェックインが壁掛け時計の時間より遅れても影響を受けないようにするにはどうすればいいのでしょうか?
ここでの答えは、ストリーム時間で考えることにあります。
すべてのチェックインが分単位で処理された後、これらのタスクが実行されるようにするには、コンシューマが追いつくのを待つ必要があります。
これは、消費されたチェックインのタイムスタンプを使用して、最後に1分の境界を越えた時間を追跡することで実現できます。
その境界を越えるたびに、その時点までのすべてを消費したことがわかります。このイベントがタスクのトリガーとなり、Celery beatを方程式から完全に切り離すことにります。
言い換えれば、コンシューマーから直接ストリームタイムでタスクを生成するようになったので、細かいタスクの生成を省略することはなくなった、ということです。
前述の2つの問題を一挙に解決することができます。
悪魔は… Kafkaのパーティション?
コンシューマー主導のクロックを追加するというこの改良は、比較的わかりやすいですが、それを正しく行うには全ての可動ピースが連動するような繊細さが必要です。
前述したように、コンシューマーは1つではないです。
複数のコンシューマーを持つということは、Kafkaトピックが複数のパーティションを持つことを意味する(その他の理由もある)わけです。
各コンシューマーはパーティションのセットから読み込むため、コンシューマーを水平方向にスケールさせることができます。
しかし、これらのパーティション間でクロックを同期させる必要があり、コンシューマーが異なる速度で実行される可能性があることを理解すると、これは素晴らしいことです。
同期を取らないと、パーティショニングによってメッセージが順番通りに読み込まれないというようなシナリオが起こってしまいます。
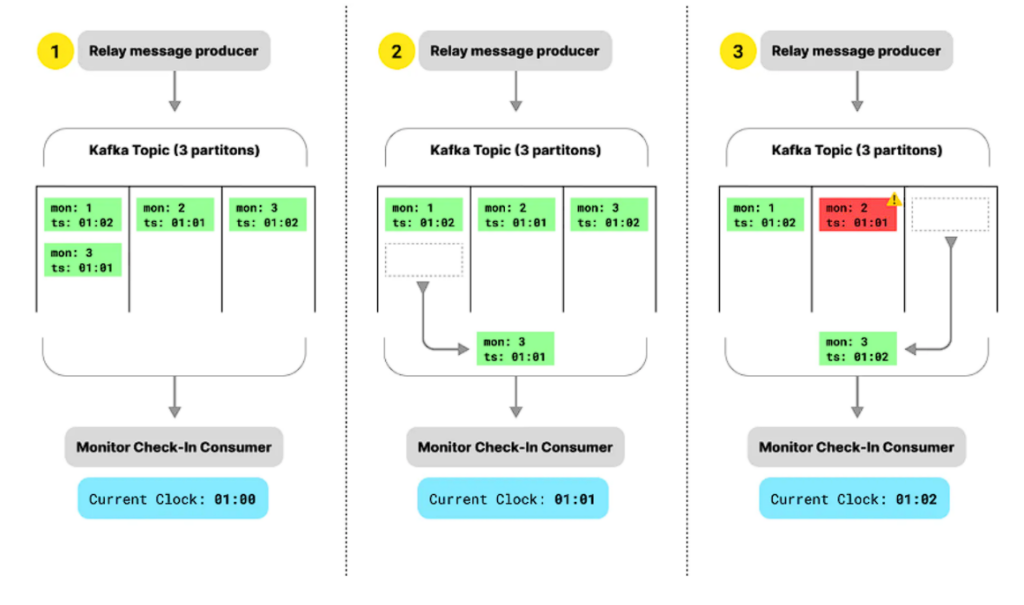
必要なのは、すべてのパーティションでクロックを同期させること。
各パーティションのクロックを記録しておき、すべてのパーティションが同じ時刻まで読み込まれたら、グローバルクロックを前進させるだけです。
この特別な問題に関する詳細は、sentry/sentry#55821をチェックしてください。
どういった効果があるのか
この変更を行う前、メトリクスに反映される最大の問題の1つは、バックログが少ない期間にチェックイン漏れが急増することでした。前述したように、これは、チェックインが単にバックログに滞留しているだけなのに、チェックイン予定時刻をミスとしてマークしていたためです。これはここで見ることができます。
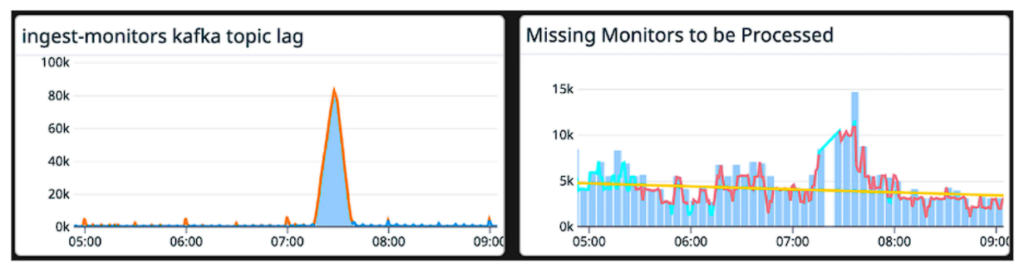
モニター・チェックインの見逃しタスクが、コンシューマー自身によって駆動されるクロックからディスパッチされるように変更したことで、チェックインの見逃しを誤認させるようなバックログの波及効果がなくなったことがわかります。タスクはストリーム時間でディスパッチされるようになりました。
次の記事
SentryのCron機能が成長し続け、より多くのユーザーがCronジョブを監視し、警告されるようになるにつれ、我々は信頼性を向上させ続けることができます。我々はまだ混乱を引き起こす可能性のある微妙なエッジケースを追跡しています。
微妙なタイムゾーンのバグから、文書化されていないSDKのサイズ制限まで、常に追跡し、修正する必要があります
Cronのアーキテクチャーに関する技術的な概要を読んでいただけましたか?
私たちのチームに加わる人も募集中です!
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。