Article by: Will McMullen
もし100ミリ秒未満の応答時間に驚いたことがあるなら、その背後には「キャッシュ」がある可能性が高いでしょう。
キャッシュは、システムのパフォーマンスを支える縁の下の力持ちです。よく使用されるデータを保存しておくことで、データベースやAPIへのアクセスを減らし、アプリの応答速度をミリ秒単位で短縮します。
今回はキャッシュがどのように機能するのか分解し、代表的な活用事例をご紹介していきます。
キャッシュとは?
キャッシュは、データの通り道に置かれる短期的な記憶装置のようなものです。よくアクセスされる情報を、時間のかかるデータベースや外部APIから毎回取り出すのではなく、すぐ使えるように一時的に保存しておきます。
動作の流れはとてもシンプルです。
- 最初のアクセス(キャッシュミス)
まずアプリは指定されたキーに対応するデータがキャッシュにあるかをチェックします。なければ、アプリは時間やコストのかかる処理(たとえばデータベースクエリ)を実行し、その結果をキャッシュに保存してからユーザーに返します。 - 2回目以降のアクセス(キャッシュヒット)
次回、同じデータが必要になった場合は、データベースを介さずキャッシュから直接取得します。このルートは非常に高速で、ユーザー体験が一気に向上します。
キャッシュはスピード感のあるUXを実現したり、インフラの負荷を軽減したりするうえでとても頼れる存在です。理論上、どのようなデータもキャッシュできますが、特によく使われるのは以下のようなものが挙げられます。
- コストの高いクエリの結果
「ユーザーXのカート情報」や「特集商品」のように、何度も同じ結果が返されるデータ - 計算されたメトリクスや分析結果
毎回計算し直す必要がなく、元データが更新された時だけ再計算すれば良いデータ - 静的アセット
画像やフォント、CSSなど、普段は変更されないものの頻繁に使用されるデータ
それではキャッシュを設定して、実際にパフォーマンスのメリットを確認してみましょう。
PythonでシンプルなRedisキャッシュを設定する
「キャッシュと言えば Redis」と呼ばれるほど、世界中の開発者に使われている信頼性の高いオープンソースのツールです。
私が気に入っている説明は Simon Willison のワークショップで耳にした『Redis は素晴らしい小さなサーバー』というひと言です。Redis はインメモリで動く Key-Value 形式でデータを保持します。
またデータベースやキャッシュ、メッセージブローカーとしても使用されています。とにかく高速で効率的なことが特徴で、リアルタイムに動作することが求められるアプリケーションにピッタリです。
今回はこの Redis を使って、データベース呼び出しをキャッシュかすることに焦点を絞ります。Redis の導入で、たとえ開発用のノートPCでも 1秒あたり数十万件の処理をミリ秒単位で処理できるようになります。
メモリ上に保存するため高速ですし、キャッシュだけでなく永続性や原子性のあるストレージとしても活用できます。主要な SQL や NoSQL の負荷を軽くし、全体のパフォーマンス改善にもつながるというわけです。
Redis を導入するためにデータベースを移行したり設定を大きく変えたりする必要はありません。Pythonを使って PostgreSQL のキャッシュ層として Redis を設定する手順を以下で紹介します。
- Redis を起動し、redis.Redis() を使ってキャッシュ層として接続する。
- cache.get() でキャッシュからデータを取得する。存在すれば、それをJSONとして読みこむ。
- データがない(キャッシュミス)場合、データベースからデータを取得し、cache.setex() でキャッシュに保存する。
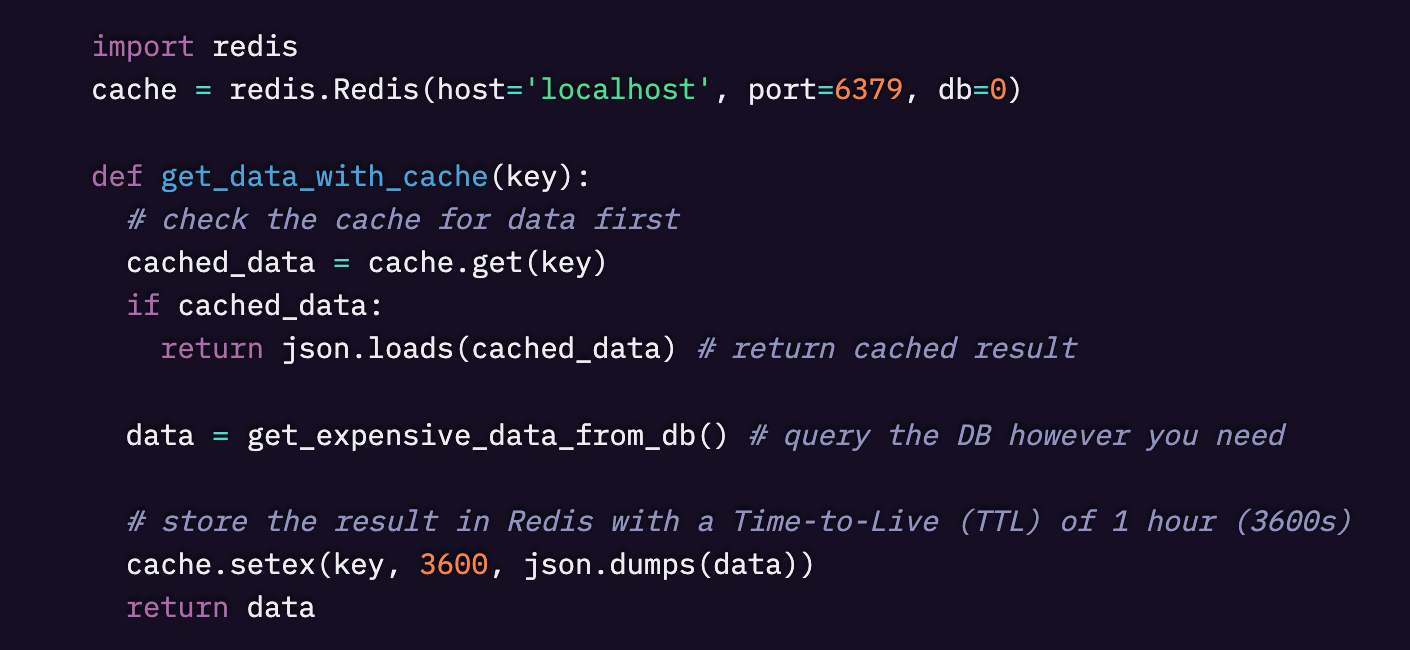
キャッシュが .get(key) で None を返すと、それは対象データがキャッシュにまだ存在していないことを意味します(これを「キャッシュミス」と呼びます)。
そのときは、アプリケーションが get_expensive_data_from_db() を呼び出してデータベースに問い合わせ、結果をキャッシュに保存してからユーザーに返します。
このサンプルコードの良いところは、Redisをあくまでキャッシュ層としてだけ使っている点です。どんなデータベースを使っていても、バックエンドの負荷を減らし、アプリの応答速度をしっかり底上げすることを示しています。
それでは、キャッシュの基本を押さえたところで次に進みましょう。よくあるパフォーマンス課題を、キャッシュで解決できる事例について見ていきます。
Sentryを使ってキャッシュに値する操作を見つける方法
いくつかのデータベース操作は非常にコストがかかってしまい、一般的に遅いものです。そうした処理こそが、キャッシュに最適なターゲットになります。
それでは、Sentryのパフォーマンスモニタリングやトレース機能を活用して、キャッシュで最適化できる箇所を素早く見つけ、効果を確認する方法をご紹介します!
1:実行時間の長いのトランザクション
遅い操作は手動で見つけるのが難しいケースがほとんどです。というのも、ローカルのブラウザでセッションを再現し、インタラクションを追跡する必要があるからです。
しかし、ローカルのブラウザではトレースされないミドルウェアが存在することも多く、それによってキャッシュのヒット/ミスが完全に見えなくなってしまうことがあります。
つまり処理速度の遅い操作はキャッシュに適しており、Sentryのパフォーマンスモニタリングを有効にすれば、スタック全体でボトルネックになっているクエリが一目でわかります。
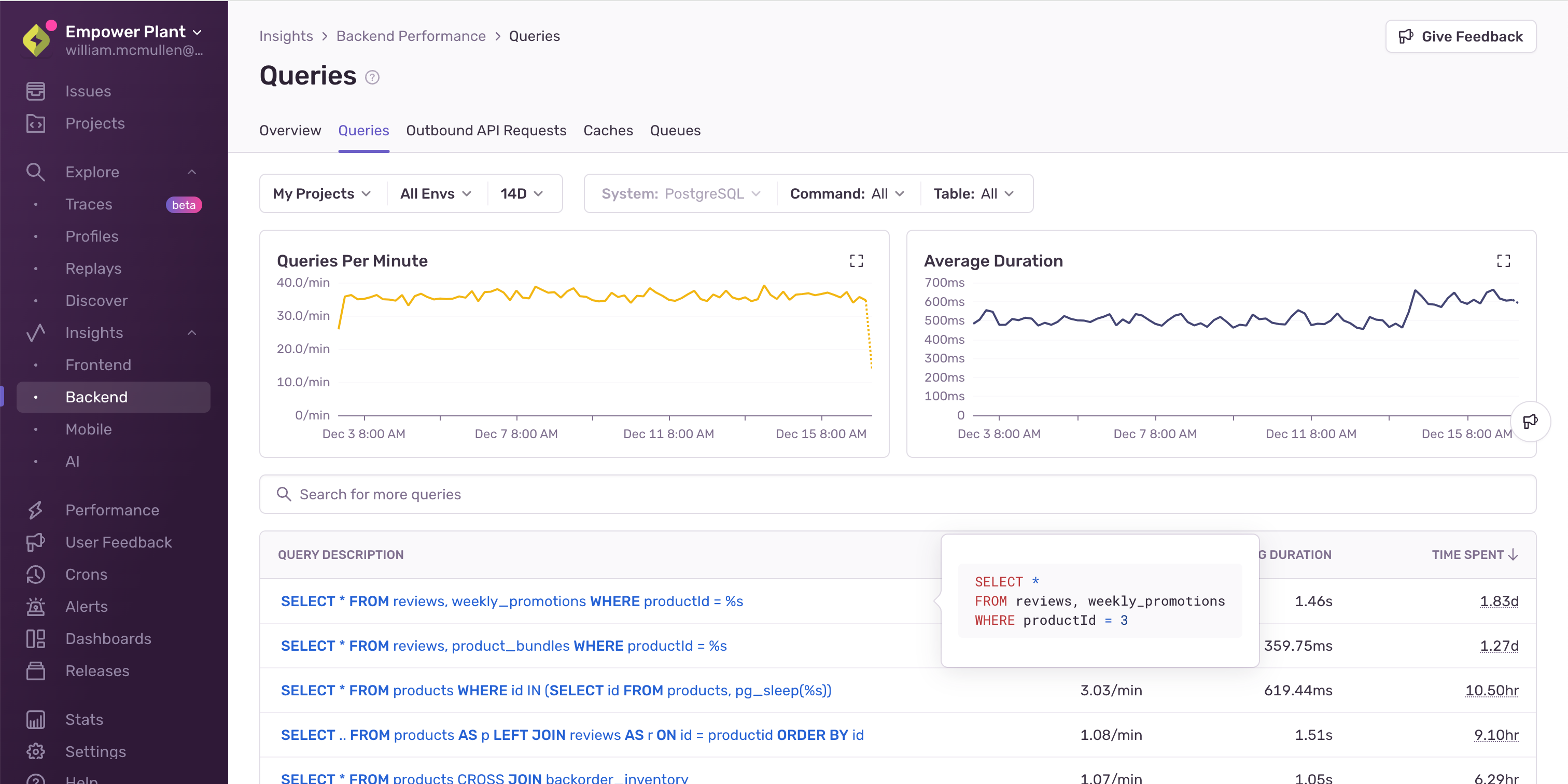
特に「バックエンドインサイト」は便利で、トレースが有効な場所で最も時間のかかっているクエリをピックアップしてくれます。そこからキャッシュの優先順位をつけていきましょう。
ちなみにキャッシュを設定するだけでなく、そのクエリにインデックスが張られているかも確認しておくと良いでしょう。キャッシュミス時のフォールバック処理もスムーズになります。
2:何度も繰り返されるスパン
本番環境の SQL や Redis に常時 MONITOR をかけるのは現実的ではありません。なぜならパフォーマンス低下を招く恐れがあるためです。とは言っても、それなしでは頻繁に実行されているクエリが何なのか確認できません。
しかしSentryの分散トレース機能を使えば、繰り返し呼び出されているクエリやAPIがひと目でわかるようになります。

ここでは異なるproductIdを持つ同じクエリが4回連続して呼び出され、1.3秒のレイテンシーを追加しているのが確認できます。
同じようなスパンが複数のトランザクションで発生するなら、それはキャッシュ対象の第一候補です。
Redis にデータが溜まりすぎて、逆にデータ探索コストが嵩んでしまうということも起きるため、キャッシュを設ける際は、TTL(有効期限)の設計にもお気をつけください。
3:遅い外部API呼び出し
上記の例と同様に、ローカルでデバッグすることは可能ですが完璧とは呼べません。API 呼び出しのパフォーマンスには、ローカルだけでは見えない要因が数多く存在します。
地域差、時間帯、APIの混雑状況…… ローカルテストだけでは把握しきれません。
こんな時こそ Sentry の出番です。本番環境での実データの行動データをもとに、API のレスポンスタイムや外れ値を分析することで、キャッシュの導入がより効果的に行えます。
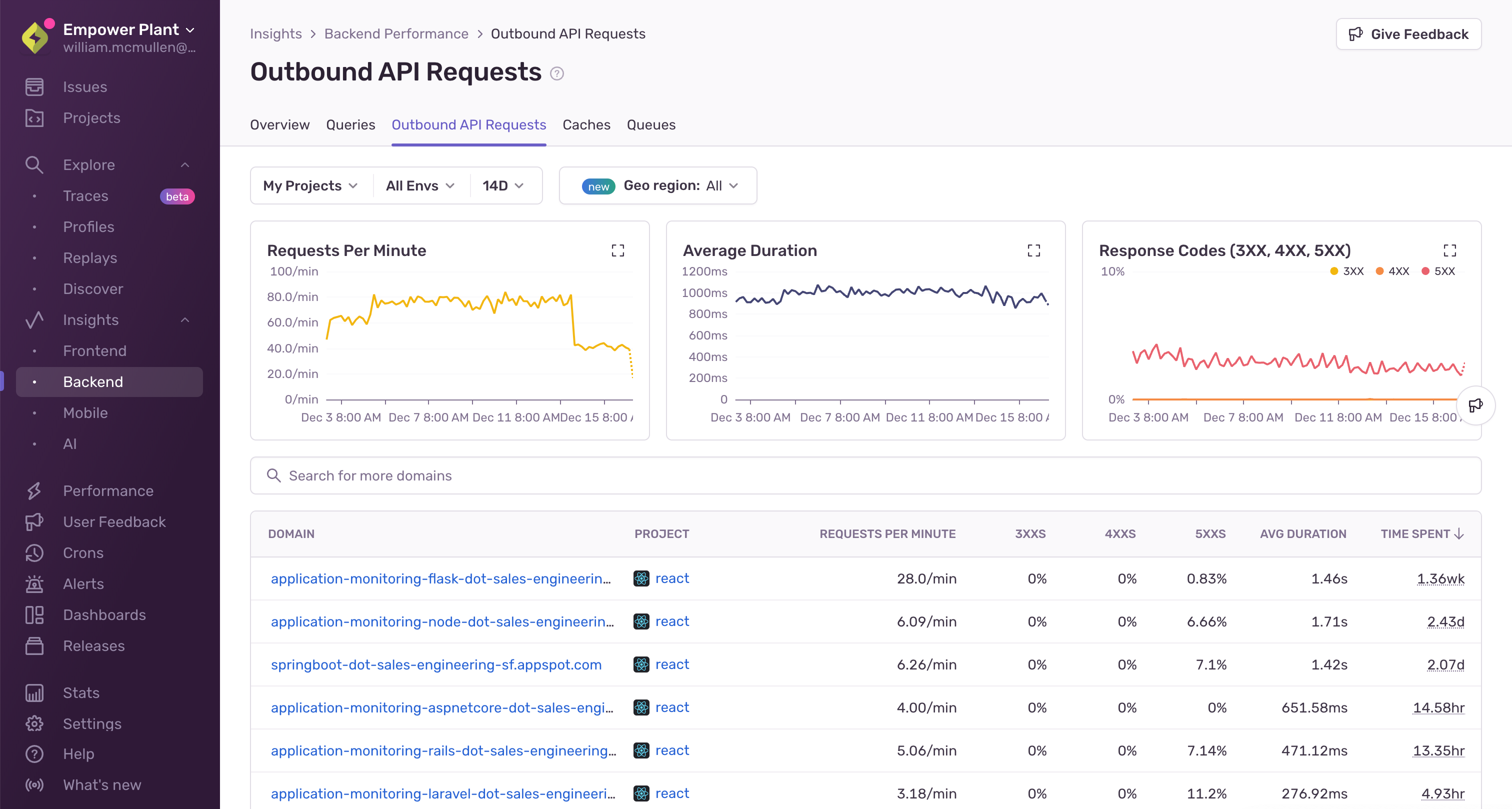
たとえば、特定のエンドポイントへの呼び出しが、ユーザー全体の中で最も時間を消費しているとわかったら、そこにRedisなどのキャッシュレイヤーを追加してみましょう。
これによりパフォーマンスが向上するだけでなく、サードパーティAPIの使用量や費用、レートリミットの面でもメリットが生まれます。
Sentryでキャッシュの問題を早く見つけて修正する
キャッシュによって短縮されるミリ秒単位の積み重ねは、ユーザー体験とインフラの両方において重要です。
Sentry は、スタックのどこにキャッシュが最適か的確に見つけ、導入後の効果も簡単に監視することができます。より賢く最適化し、迅速にデバッグし、ユーザーとインフラのコストを満足させましょう。
今すぐ Sentry for Performance を無料トライアルでお試しください。気になることや相談したいことがあれば、こちらのDiscordにお気軽にご参加ください。
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。