大規模な言語モデルの使用が増えるにつれ、そのパフォーマンスを理解し最適化するためのツールの必要性も高まっています。観測可能なフレームワークを使用せずにLLMを使用したアプリケーションをデプロイすることは、ブレーキなしで車を運転するようなものです。
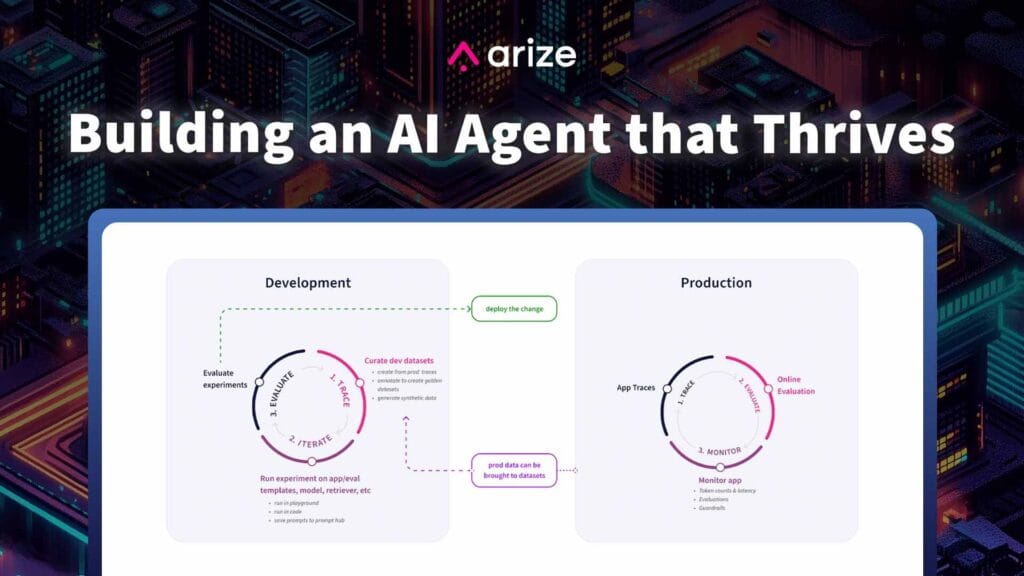
トレースは、LLMアプリケーションの内部で何が起こっているのかをよりよく見るための効果的な方法を開発者に提供する、強力な観測可能性テクニックです。
プロンプトとレスポンスのペアのもつれの中で、開発者はしばしばシステムの可視性が低いために効果的な反復を行う能力を失います。トレーシングはこの問題を解決します。
この投稿では、LLMアプリケーションの文脈におけるトレースの効果を探ります。トレーシングがどのように機能するのか、どのようなユースケースで有用なのかを明らかにし、あなたのLLMプロジェクトにトレーシングを導入するプロセスをガイドします。
さあ、トレースの世界へ飛び込みましょう!
トレースの仕組み
トレーシングは、リクエストがシステムの複数のステップやコンポーネントを通過する際の経路を記録します。例えば、ユーザーがLLMアプリケーションとやりとりするとき、トレースはリクエストの実行の詳細なタイムラインを提供するために、ドキュメント検索、埋め込み生成、言語モデル呼び出し、レスポンス生成のような操作のシーケンスをキャプチャすることができます。
トレーシングの背後にある重要なコンポーネントには、インスツルメンテーション、エクスポーター、OLTPがあります。
計装
アプリケーションから解析用のトレースを出すには、インスツルメンテーションが必要です。これは、アプリケーションにトレースコードを追加して手動で行うこともできますし、プラグインやインストルメントを使用して自動的に行うこともできます。Arize Phoenixは、アプリケーションに簡単に統合できるインスツルメンテーションツールのセットを提供し、手動でインスツルメンテーションを行うことなく、スパン(作業または操作の単位)を自動的に収集します。
エキスポーター
エクスポーターは、インスツルメンテーションによって作成されたスパンを収集し、処理と可視化のためにコレクターに送信する役割を果たします。Phoenixを使用する場合、エクスポートプロセスは、シームレスにトレースデータをPhoenixコレクタに送信する、ボンネットの下で処理されます。
OpenTelemetryプロトコル(OTLP)
OTLPは、アプリケーションからPhoenixコレクタへのトレース転送に使用されるプロトコルです。Phoenixは現在、OTLP over HTTPをサポートしており、統合を簡素化し、広く採用されているOpenTelemetryエコシステムとの互換性を確保しています。
トレースによってアプリケーションの実行状況を包括的に把握できるため、開発者はパフォーマンス、運用、デバッグに関するさまざまな課題を、他の方法では不可能な規模で特定し、対処することができます。収集されたトレース・データは、アノテーションの使用によってさらに強化することができ、LLMアプリケーションの反復的な改善を推進するために、ユーザー・フィードバックとAIが生成した評価の両方を取り込むことができます。
トレースの実装例
この例では、RAGパイプラインを構築し、Phoenix Evalsで評価していきます。
検索拡張世代(RAG)とは?
LLMは膨大な量のデータに基づいてトレーニングされますが、その中には貴社固有のデータ(企業のナレッジベースや文書など)は含まれていません。Retrieval-Augmented Generation (RAG)は、生成プロセス中にコンテキストとしてお客様のデータを動的に取り込むことで、この問題に対処します。
これは、LLMの学習データを変更することによってではなく、モデルがお客様のデータにリアルタイムでアクセスし、利用することによって行われ、よりカスタマイズされた、コンテキストに関連した応答を提供します。
RAGでは、データがロードされ、クエリ用に準備されます。このプロセスは『インデックス作成』と呼ばれます。ユーザーのクエリはこのインデックスに作用し、データを最も関連性の高いコンテキストにフィルタリングします。このコンテキストとクエリは、プロンプトとともにLLMに送られ、LLMが応答を返します。
RAGは、チャットボットやエージェントのようなアプリケーションを構築するために重要なコンポーネントです。
RAGパイプラインの構築
RAGとは何かを理解したところで、パイプラインを構築してみましょう。RAGにはLlamaIndexを使い、評価にはPhoenix Evalsを使います。
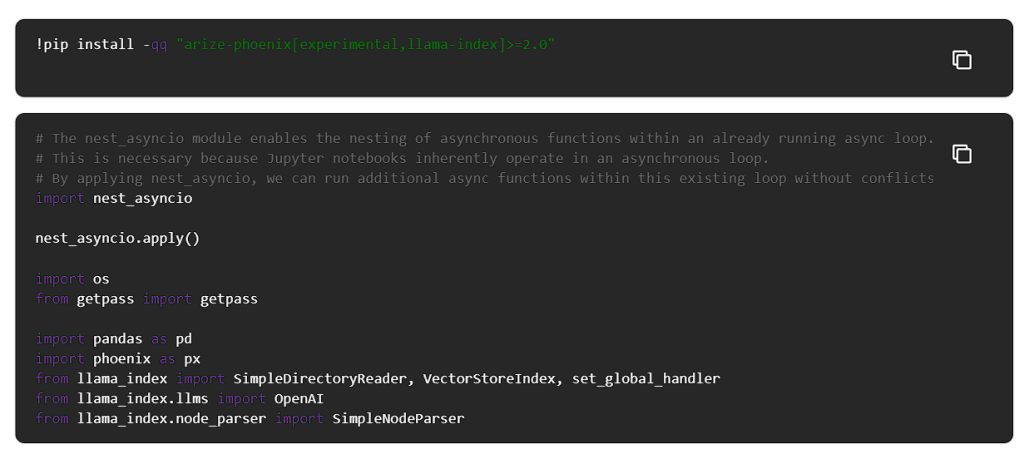
Phoenix Tracingを使用して、RAGパイプラインの評価に必要なすべてのデータを取得します。これを有効にするには、Phoenixアプリケーションを起動し、LlamaIndexを計測するだけです。
ローカルターミナルで以下のコマンドを使用してPhoenixを起動します。

Phoenixを初めて使う場合は、ターミナルで以下のコマンドを実行する必要があるかもしれません。

クラウドホスティングのPhoenixインスタンスを使用したい場合は、以下の手順を参照してください。
ノートブックに戻って、Phoenixのローカルインスタンスに接続します。
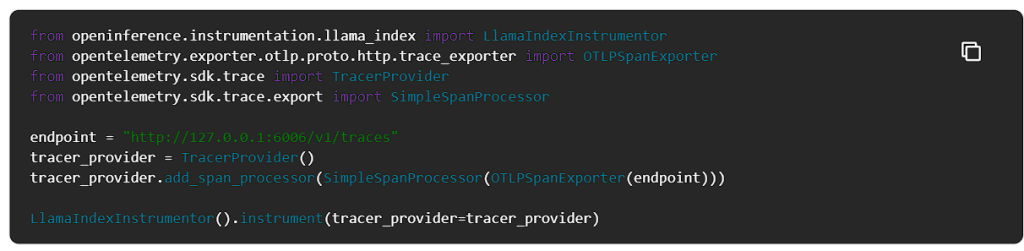
このチュートリアルでは、合成データの作成と評価にOpenAIを使用します。

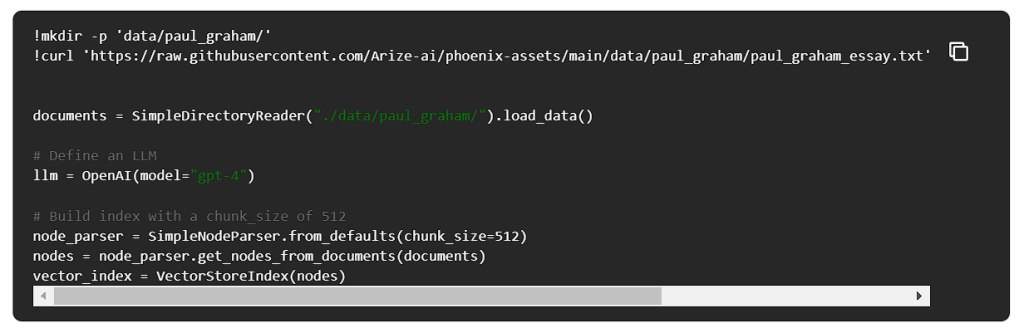
ポール・グラハムのエッセイを使ってRAGパイプラインを構築してみましょう。
これでQueryEngineを構築し、クエリーを開始することができます。

.response_vector.responseを使用すると、クエリから得られるレスポンスを確認できます。
デフォルトでは、LlamaIndexは2つの類似したノードまたはチャンクを取得します。これを変更するには以下のように行います。

最後に、検索された各ノードのテキストをチェックしてみよう。

RAGパイプラインの評価に必要なすべてのデータを取得するために、Phoenixトレースを使用していることを忘れないでください。トレースは phoenix アプリケーションで見ることができます。
Phoenixセッションからスパンを直接引き出すことで、トレースにアクセスできます。

トレースはクエリーエンジンによって取得されたドキュメントをキャプチャしていることに注意してください!
RAGパイプラインがインスツルメンテーションされ、トレースがPhoenixにエクスポートされると、収集されたデータをPhoenixのユーザーインターフェイスで表示および調査できるようになります。Phoenixアプリケーションには、トレースを可視化、クエリ、分析するための豊富なツールセットが用意されており、LLMアプリケーションのパフォーマンスと動作に関する深い洞察を得ることができます。
LLMトレーシングは何ができるのか?
トレースを実装することで、以下のことが可能になります。
- 個々の操作のレイテンシを調べることにより、パフォーマンスのボトルネックを特定する。
- LLMコールのトークン使用状況を把握し、コストと効率を最適化する。
- レート制限の問題など、実行時の例外を検出して調査します。
- Retrieverによって検索されたドキュメントを、そのスコアや順序を含めて検査する。
- アプリケーションで使用されている埋め込みテキストとモデルを調査する。
- LLMの起動時に使用されるパラメータとプロンプトテンプレートを分析する。
- LLMがアクセスできるツールや機能を理解する。
その他のリソース
もし不明点があれば、ArizeのSlackコミュニティにお気軽に質問を投稿してください。
Arizeプラットフォームでトレースがどのように見えるかについては、こちらのデモで実際にご覧いただけます。