Article by: Sergiy Dybskiy
少し前、エージェントたちが「あなたは完全に正しいです!」と言っていた頃、私はwebvitals.comを作っていました。URLを入力すると、Next.jsのAPIルートへのAPIリクエストが開始され、いくつかのツールを持つエージェントが呼び出されてそれをスキャンし、あなたの……そう、想像どおり……Web Vitalsを改善するためのAI生成の提案を提供します。今もこれを気にする必要はあるのでしょうか?
開発環境ではtraceSampleRateを100%に設定していましたが、本番環境ではそれを10%まで下げていました。なぜなら……まあ、それが私たちのインストルメンテーションで推奨されているからですが。
Kyleは「【Sentry サンプリング戦略】すべてを見ようとすると結局なにも見えなくなる」と説明する優れたブログ記事を書いています。しかし、AIは非決定的です。そしてツールコールのエラーをデバッグしていたとき、そのサンプリング戦略のせいで、Vercel AI SDKから出力される非常に重要なスパンを見逃していることに気づきました。
7回のツールコールを伴うエージェントの実行は、部分的にサンプリングされることはありません。スパンツリー全体を取得するか、完全に失うかのどちらかです。これがヘッドベースサンプリングの仕組みです。
私は幻を追いかけていたわけです。
エージェントの実行はスパンツリーであり、サンプリングは全取得かゼロかのどちらか
一般的なエージェントの実行は、Sentryのトレースビューでは次のように表示されます。
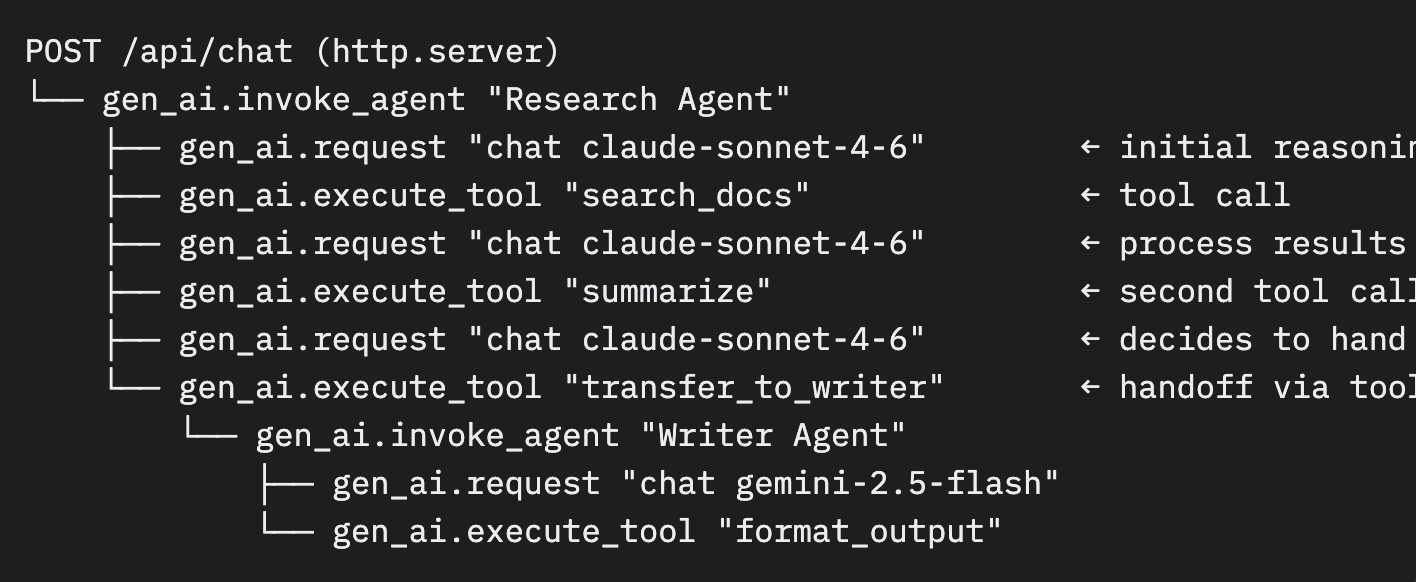
1回の実行で11個のスパンがあり、サンプリングの判断はルートで一度だけ行われます。それは POST /api/chat のHTTPトランザクションです。すべての子スパンはその判断を引き継ぎ、ルートが破棄されれば、9個すべてのスパンが消えます。
これはHTTPリクエストのサンプリングとは本質的に異なります。GET /api/users を1つ捨てたとしても、次のリクエストはほぼ同じなので大きな問題にはなりません。
エージェントの実行は同一ではありません。それぞれが異なる判断を行い、異なるツールを呼び出し、異なるデータを処理します。67回目の実行でハルシネーションを起こしたエージェントが、420回目では完全に正常に動作するかもしれません。もしサンプルレートによって67回目が捨てられていたら、何が問題だったのかを知ることはできません。
ヘッドベースサンプリングが実際にどのように動作するのか(そしてここでなぜ重要なのか)
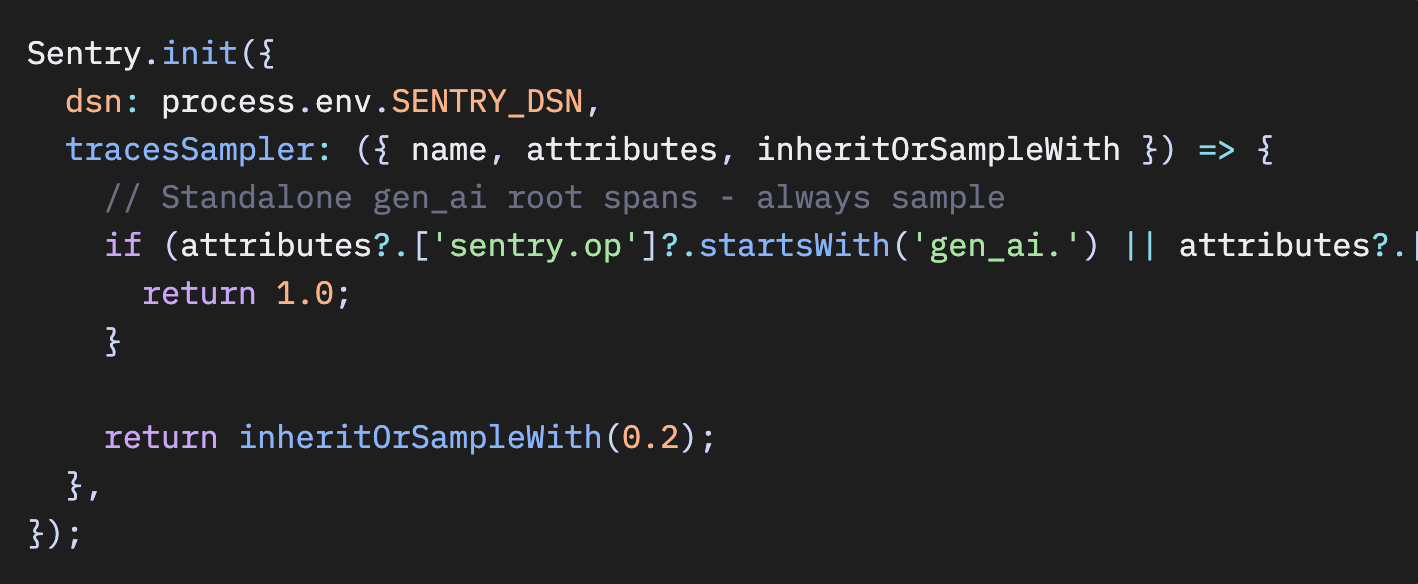
SentryのJavaScriptおよびPython SDKはいずれもヘッドベースサンプリングを使用しています。判断はトレースの開始時、まだ子スパンが存在しない段階で行われます。
JavaScript SDKでは、SentrySampler.shouldSample() がこの点を明確に示しています。

Python
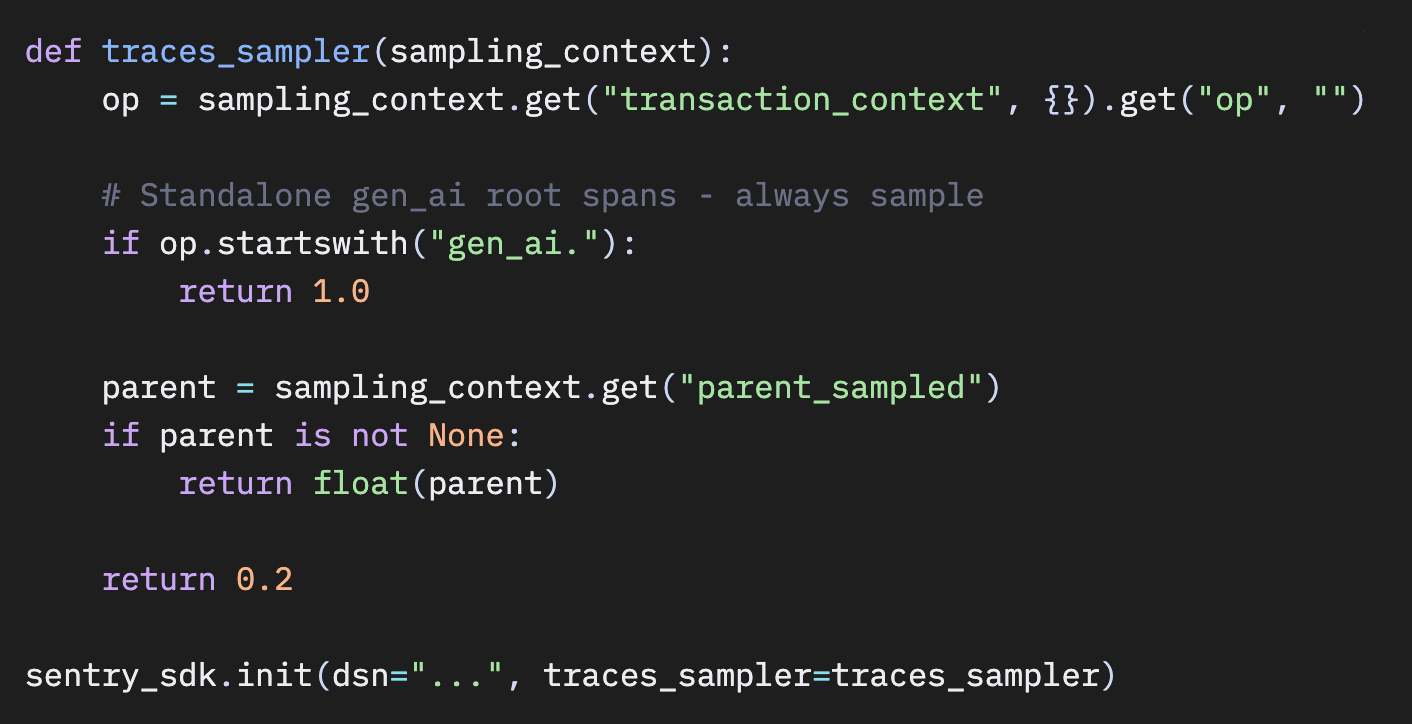
これは簡単なケースです。難しいのは次です。
シナリオ2:gen_ai スパンが HTTP トランザクションの子である場合
これはWebアプリケーションでは一般的なケースです。ユーザーが POST /api/chat にアクセスすると、フレームワークは http.server のルートスパンを作成し、そのリクエストハンドラのどこかでエージェントが実行されます。最初の gen_ai.request スパンが作成される時点では、HTTPトランザクションに対するサンプリングの判断はすでに行われています。
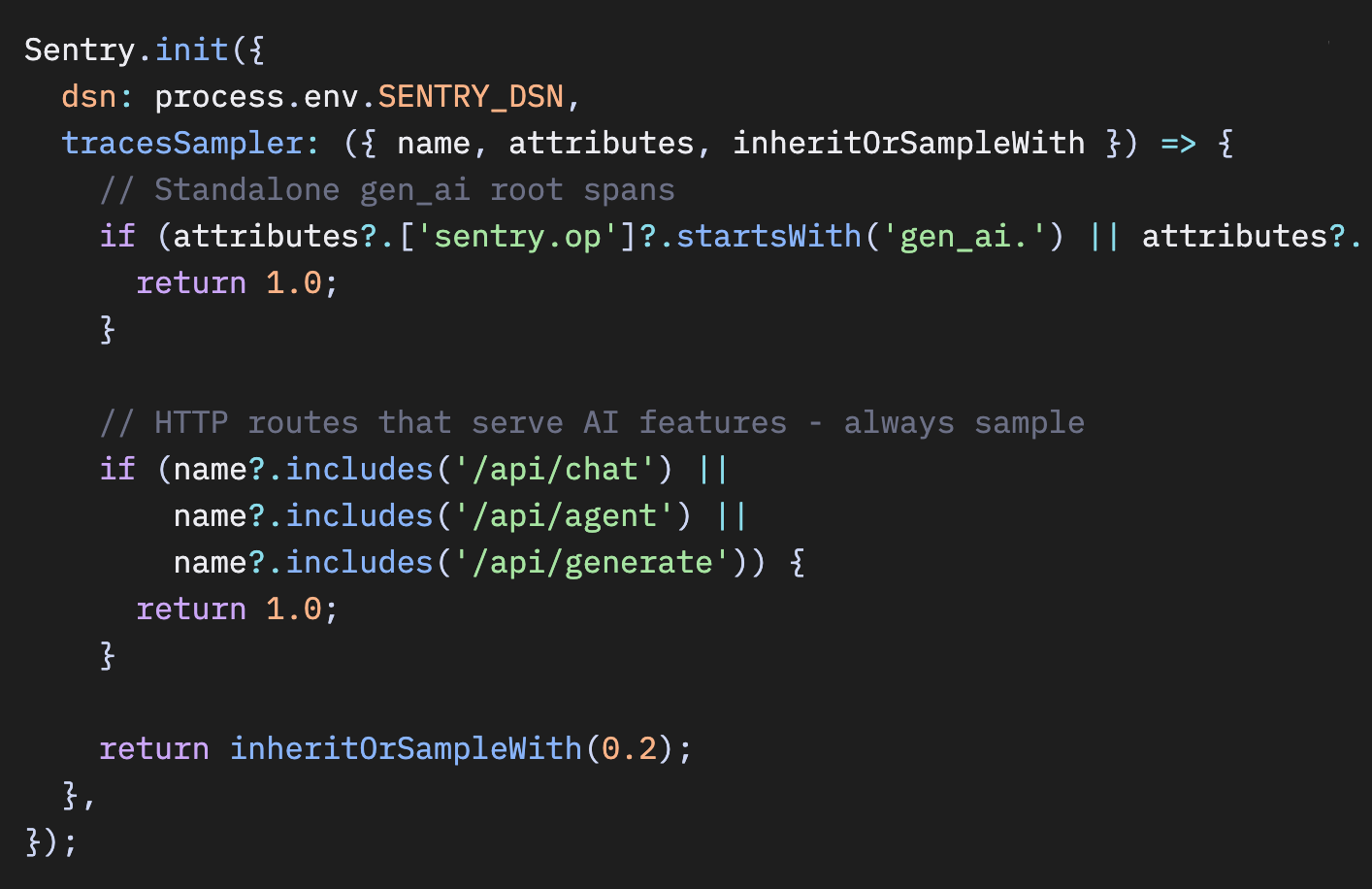
解決策は、AI呼び出しをトリガーするルートを特定し、それらのルートを100%でサンプリングすることです。
JavaScript
Python
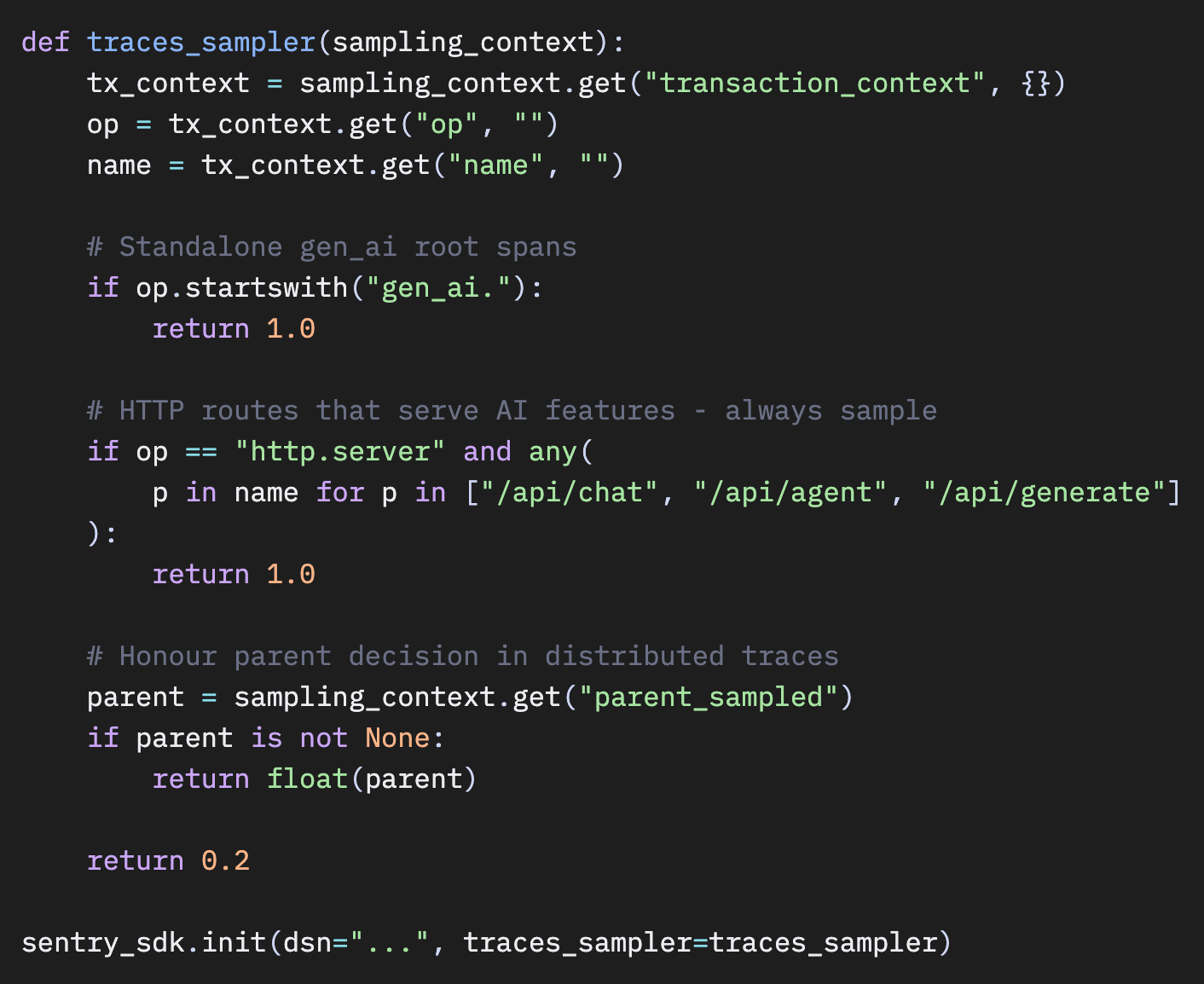
ルート文字列は、あなたのAI機能が存在するパスに置き換えてください。もしアプリ全体がAIベースであれば、tracesSampler は使わずに tracesSampleRate: 1.0 を設定してください。
コストの観点:AI APIの請求額はオブザーバビリティのコストを大きく上回る
AIトレースを低いレートでサンプリングしたくなるのは、通常コストへの懸念からです。実際の数値を見てみましょう。
|
項目 |
コスト(1イベントあたり) |
|---|---|
|
Claude Sonnet 4 入力(1Kトークン) |
約0.003ドル |
|
Claude Sonnet 4 出力(1Kトークン) |
約0.015ドル |
|
Gemini 2.5 Flash 入力(1Kトークン) |
約0.00015ドル |
|
Gemini 2.5 Flash 出力(1Kトークン) |
約0.0006ドル |
|
典型的なエージェント実行(LLM呼び出し3回、ツール呼び出し2回) |
0.02ドル~0.15ドル |
|
そのエージェント実行に対するSentryのスパンイベント(約9スパン) |
1セント未満のごく一部 |
LLMコールそのものは、監視コストよりも10〜100倍高価です。すでにAIコールに対して費用を支払っている以上、1回あたり数分の1セントを節約するためにオブザーバビリティのスパンを削るのは、ガソリン代を節約するためにドライブレコーダーを外すようなものです。
100%トレーシングが難しい場合:メトリクスとログをセーフティネットとして使う
もし本当に、大規模環境や厳しい予算制約などの理由でAIルートを100%サンプリングできない場合でも、SentryのMetricsとLogsを使えば、すべてのAIコールから重要なシグナルを取得できます。これらはトレースのサンプリングとは独立しています。
JavaScript – すべてのLLMコールでメトリクスを送信
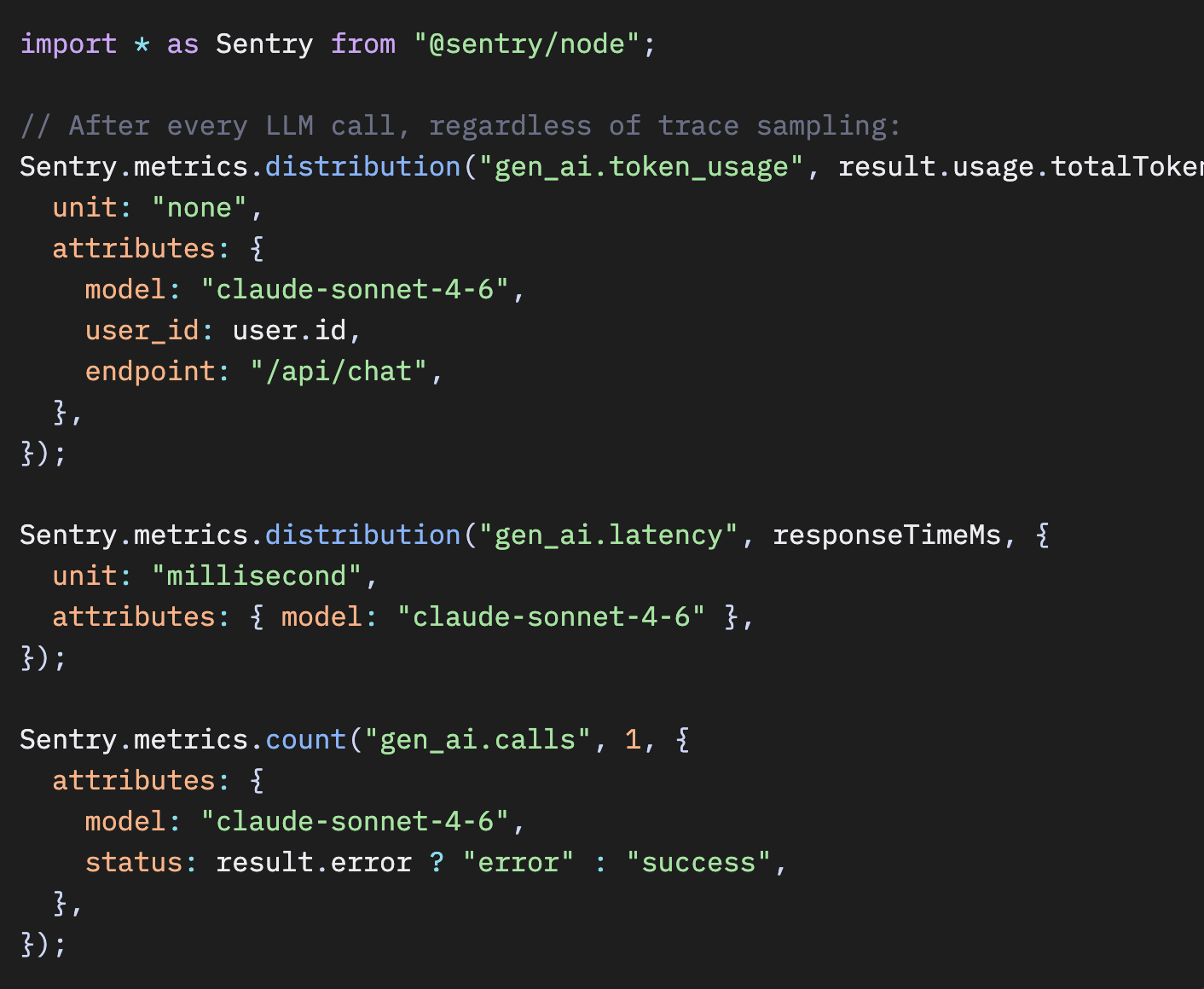
Python – LLM呼び出しごとにメトリクスを出力
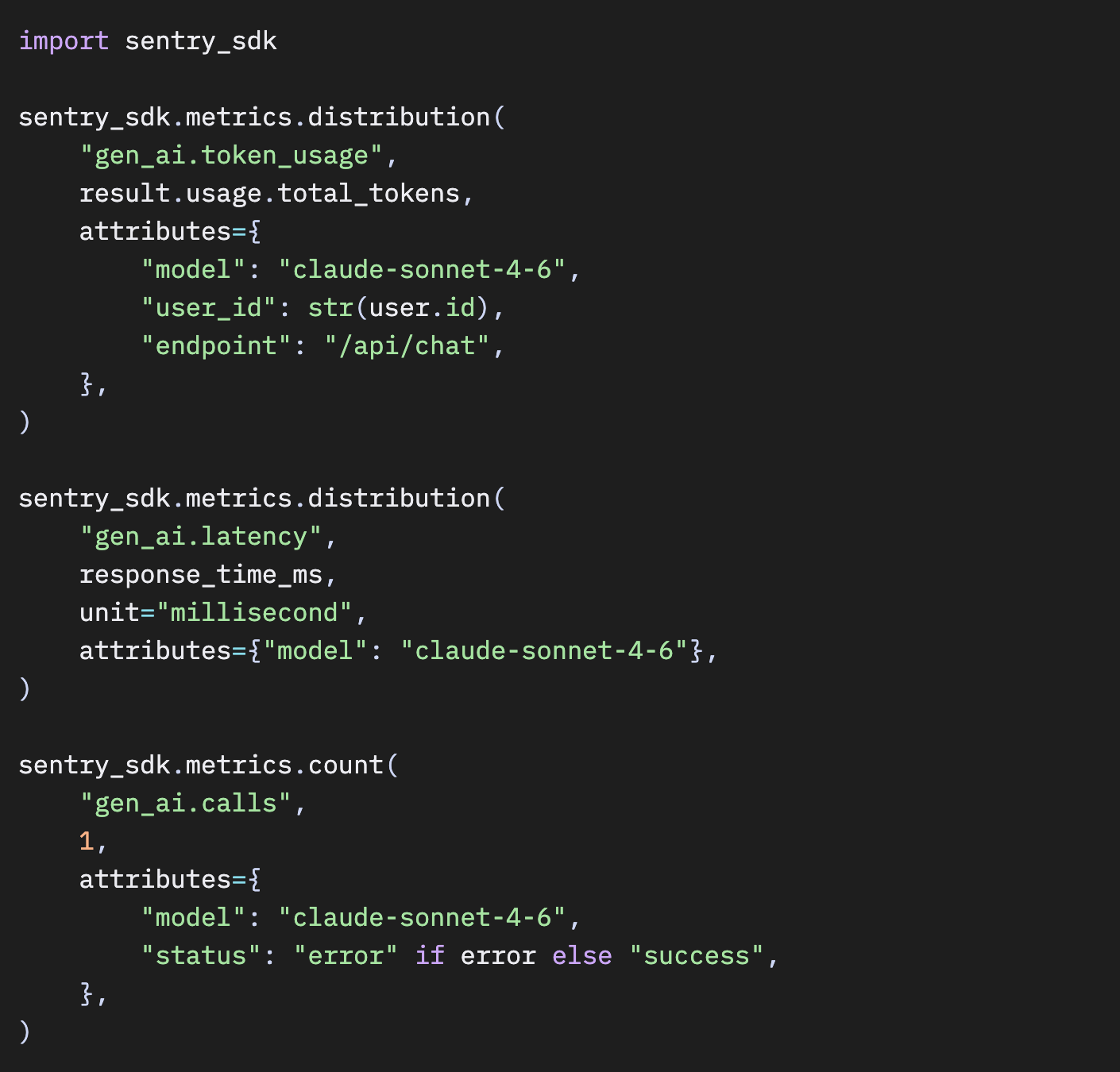
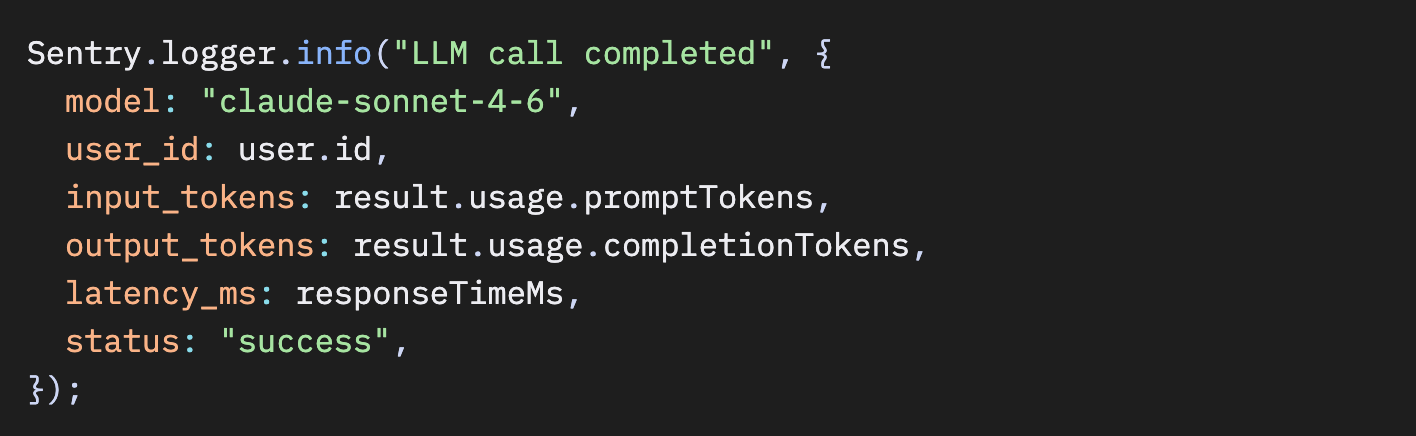
Python

各テレメトリレイヤーで得られるものは次のとおりです。
|
シグナル |
トレース(サンプリングあり) |
メトリクス(100%) |
ログ(100%) |
|---|---|---|---|
|
プロンプト/レスポンスを含む完全なスパンツリー |
はい |
いいえ |
いいえ |
|
トークン使用量の分布(p50、p99) |
部分的 |
はい |
いいえ |
|
モデル/ユーザーごとのコスト内訳 |
部分的 |
はい |
はい |
|
モデル/エンドポイントごとのエラー率 |
部分的 |
はい |
はい |
|
レイテンシの分布 |
部分的 |
はい |
いいえ |
|
検索可能なコール単位の記録 |
はい |
いいえ |
はい |
推奨アプローチ:tracesSampler を使用して、AI関連のルートを100%取得します。それが難しい場合は、トレースのサンプルレートを下げつつ、すべてのコールでメトリクスとログを送信する構成にします。トレースはデバッグの深さを提供し、メトリクスとログは全体像を提供します。
これらのメトリクスを送信するようにすれば、あらかじめ用意されたAI Agentsダッシュボード以上のカスタムダッシュボードを構築できます。Sentry CLIを使えば、これをスクリプト化することも可能です。

あらかじめ用意されたダッシュボードでは、モデルごと・ツールごとの集計を確認できます。一方でカスタムダッシュボードは、どのユーザーがコストを押し上げているのか、どの機能がAIコストに見合う価値を生んでいるのか、どの会話が制御不能に膨らんでいるのかといった、ビジネス上の問いに答えることができます。
本番環境向けの完全な設定
AI関連のルートを100%サンプリングし、それ以外はベースラインのレートでサンプリングしつつ、セーフティネットとしてメトリクスも送信する、完全な設定は次のとおりです。
JavaScript
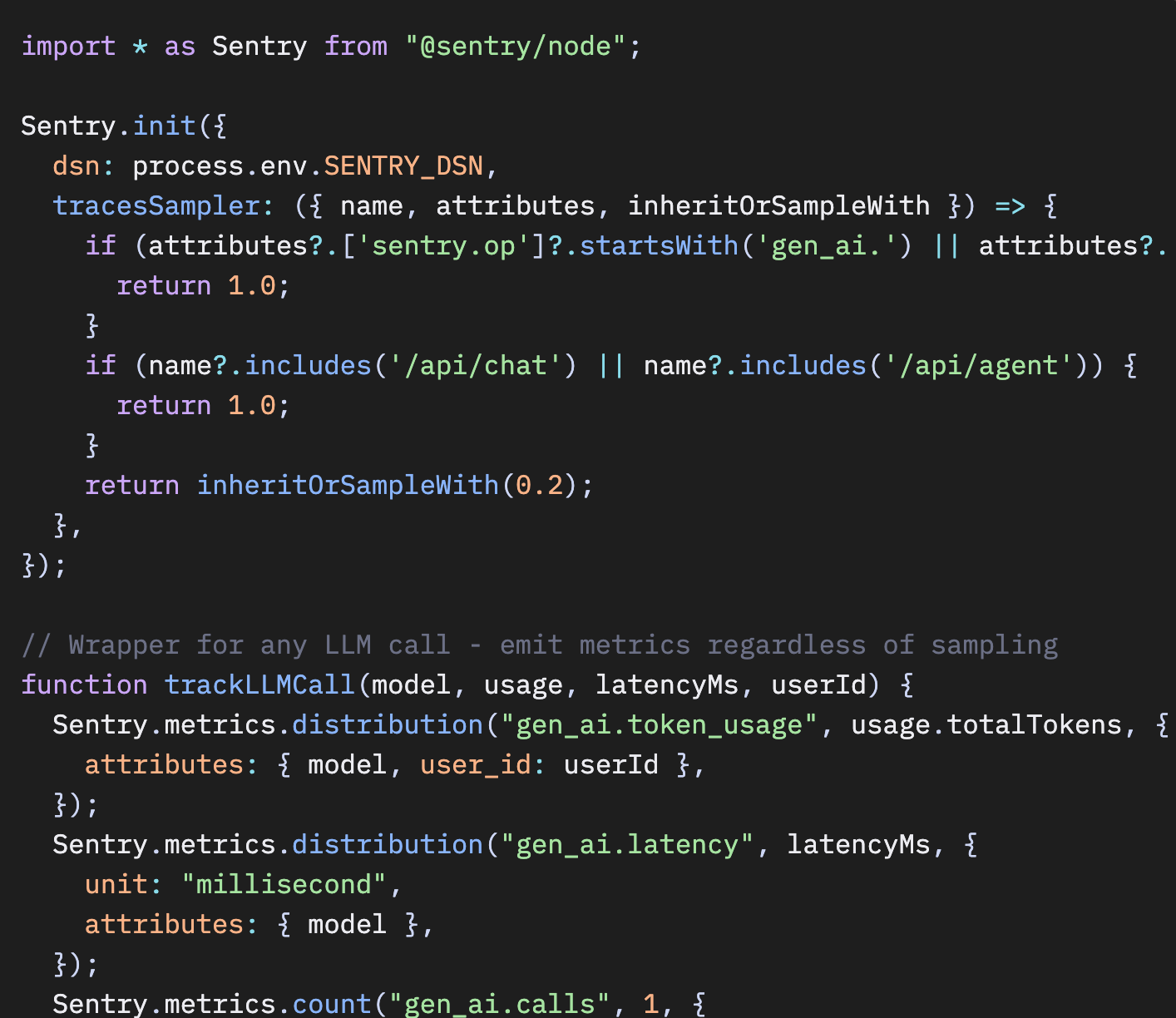
Python
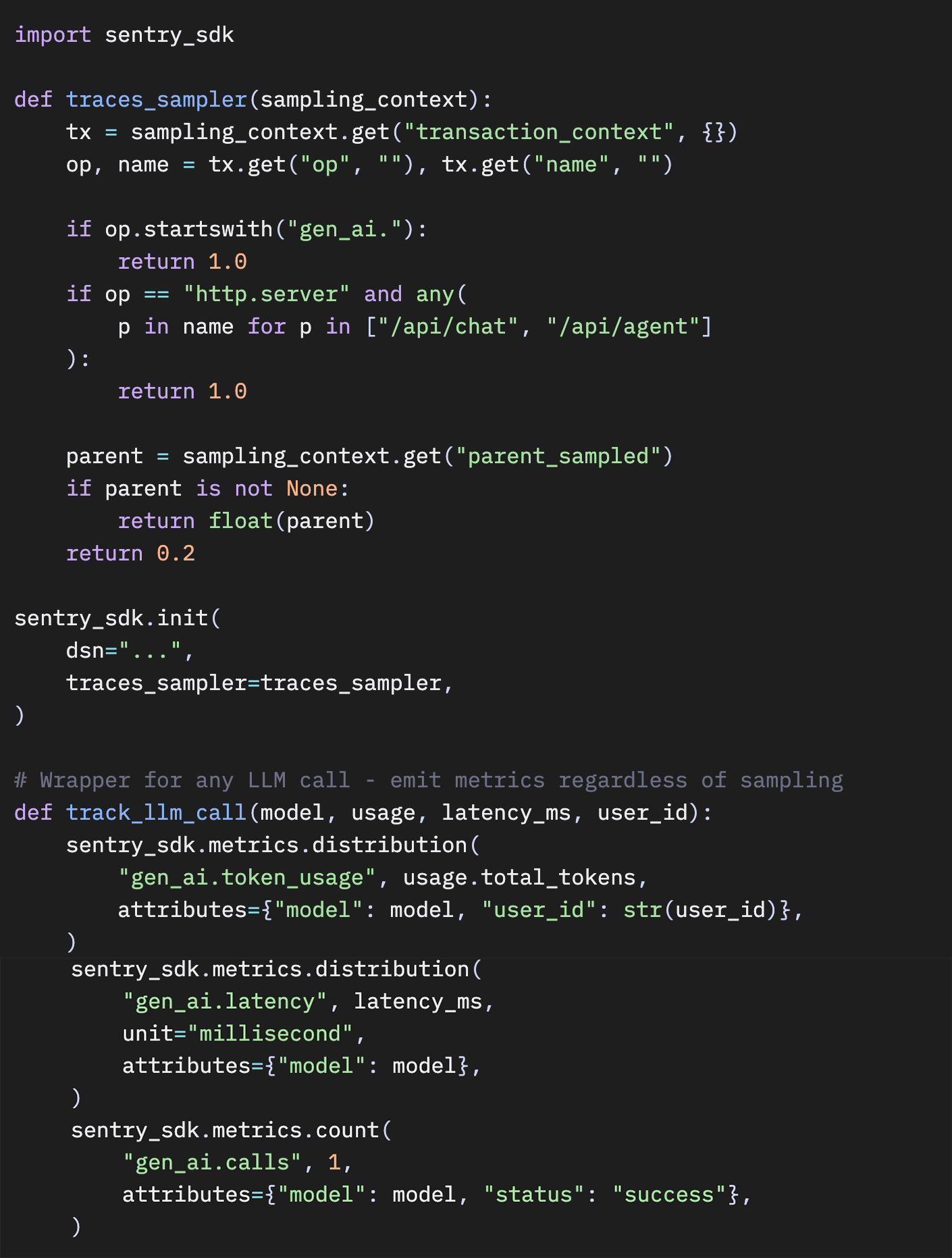
クイックリファレンス
|
状況 |
対応方法 |
|---|---|
|
AIがコアプロダクトである |
tracesSampleRate: 1.0 を設定し、すべてをサンプリングする |
|
AIが大きなアプリの一機能である |
tracesSampler を使い、AI関連ルートは1.0、それ以外はベースラインで設定する |
|
AI関連ルートを100%にできない |
トレースレートを下げつつ、すべてのコールでメトリクス/ログを送信する |
|
すでに tracesSampler を使用している |
既存ロジックにAIルートのマッチングを追加する |
|
サンプルレートがすでに1.0である |
変更は不要 |
Original Page: Sample AI traces at 100% without sampling everything
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。