Article by: Kyle Tryon
一般的なNext.jsのデプロイでは、最大で3つの異なるランタイム(Edge、Node.js、ブラウザ)でコードが実行される可能性があります。
サーバーサイドのコードからログをすでに取得しているかもしれませんが、ミドルウェアからサーバーレンダリング、そしてブラウザに至るまでのリクエスト全体を取得していない場合、問題が発生したときに多くのデバッグ情報を見逃していることになります。
要約:一般的なNext.jsのデプロイは、Node、Edge、ブラウザという最大3つの環境で実行されます。ほとんどのJavaScriptのロギングライブラリはNodeを対象としており、Edgeやブラウザに対応しているものははるかに少ないです。LogTapeとSentryはいずれも、ランタイムに依存しないJavaScriptのロギングを提供します。
なぜNext.jsでのロギングは難しいのか

課題 1:多くのロガーはNode.jsを前提としている
多くのロガーはNode.js専用に構築されており、ブラウザやEdgeランタイムでは利用できないAsyncLocalStorageやfsのようなAPIに依存しています。
Next.jsに最適なロガーとしてPino(またはNext-Loggerのようなラッパー)が推奨されることがよくありますが、実際にはどちらもNext.jsにとって良い選択ではありません。
Pino、ひいてはNext-LoggerはNode.js向けに設計されており、ブラウザで動作させるためにポリフィルを使用しています。しかしそのポリフィルにより、Nodeでのパフォーマンス上の利点は失われ、さらにEdge関数やミドルウェア(Edge上で実行される)ではログを取得することができません。
課題 2:クライアントサイドのロギングが欠落する
クライアントサイドのログを取得する必要はないと考えがちです。なぜなら「フロントエンドのコード」はすべてサーバーサイドで動作していると思われがちだからです。
デフォルトでは、Next.jsはすべてのページとコンポーネントにServer Componentsを使用します。そのため、デフォルトでは「フロントエンドのコード」から出力されるログは、実際にはサーバーサイドのログとして取得されます。
しかし、インタラクティブなコンポーネントのためにuse clientの境界を追加すると、そのコードはブラウザで実行されるようになります。
「フロントエンドのコード」は、1つのページをレンダリングするために連携して動作するServer ComponentsとClient Componentsの混在であり、それぞれ異なる場所にログを出力します。
この分断を解消し、どこで実行されるかに関わらず、すべてのフロントエンドコードのログを同じ場所に集約する必要があります。
課題 3:トレースと結びついた構造化ロギング
ロギングは可観測性の一部にすぎず、それ単体ではローカルでのデバッグ時に最も有用です。本番環境では、数十、数百、あるいは数千のリクエストからログを収集するようになると、関連するログ同士を結び付けて検索・集約する手段が必要になります。
トレーシングはアプリ内の各リクエストに一意のIDを付与し、そのIDを構造化データとしてすべてのログに付加します。これにより、後からそのIDに基づいてログを検索し、同一リクエストに関連するすべてのログを、Sentryのエラーなど他のテレメトリデータとあわせて確認することができます。
Next.jsへのトレーシングの導入自体は実際には簡単ですが、それでも実施すべきステップであり、いくつかの方法が存在します。
ここでは、JavaScriptのロギングライブラリとSentryを組み合わせて、トレースに紐づいたログをNext.jsに計測として組み込みます。別の記事では、OpenTelemetryを使用した別のトレーシング導入方法について解説・比較する予定です。
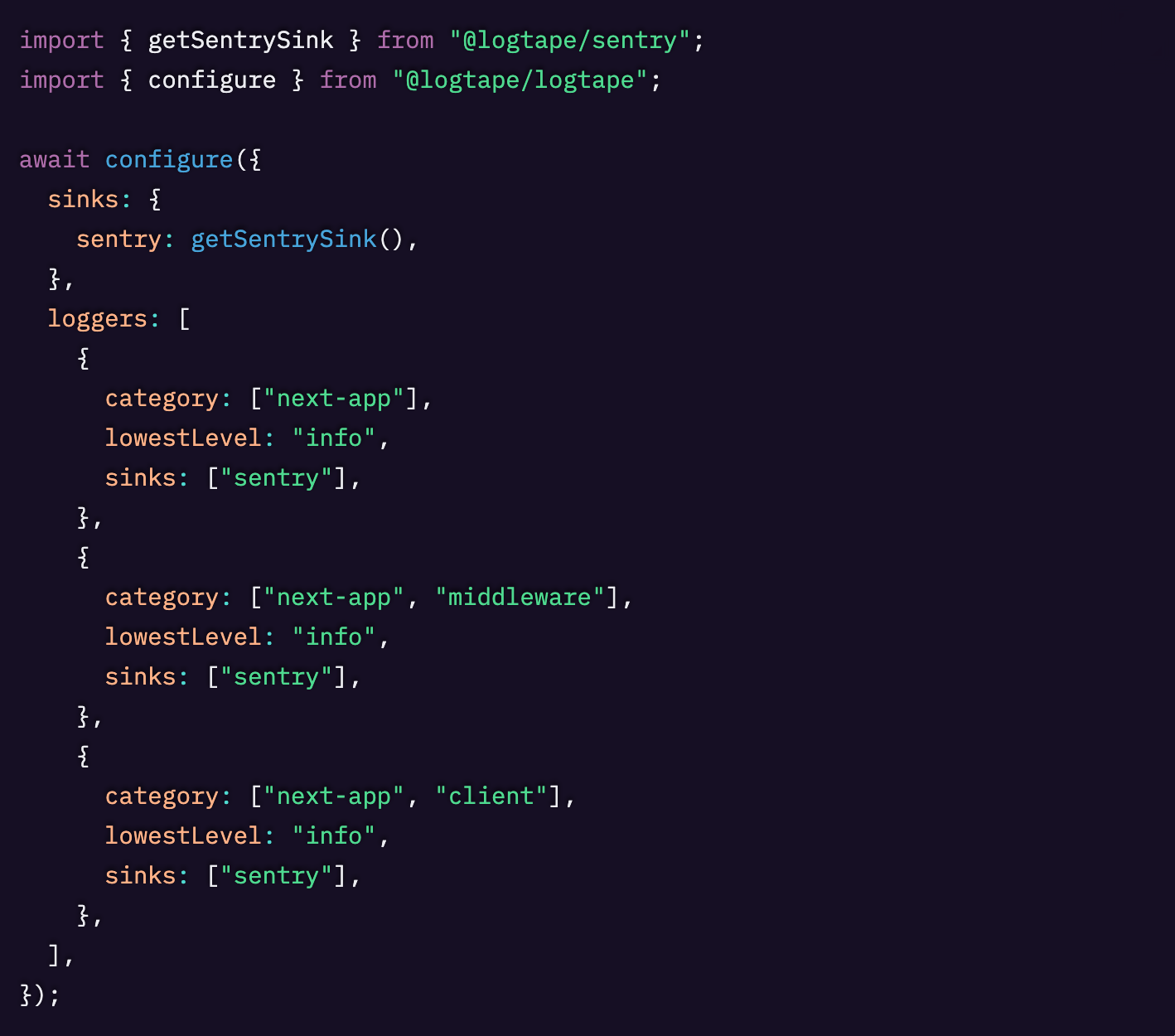
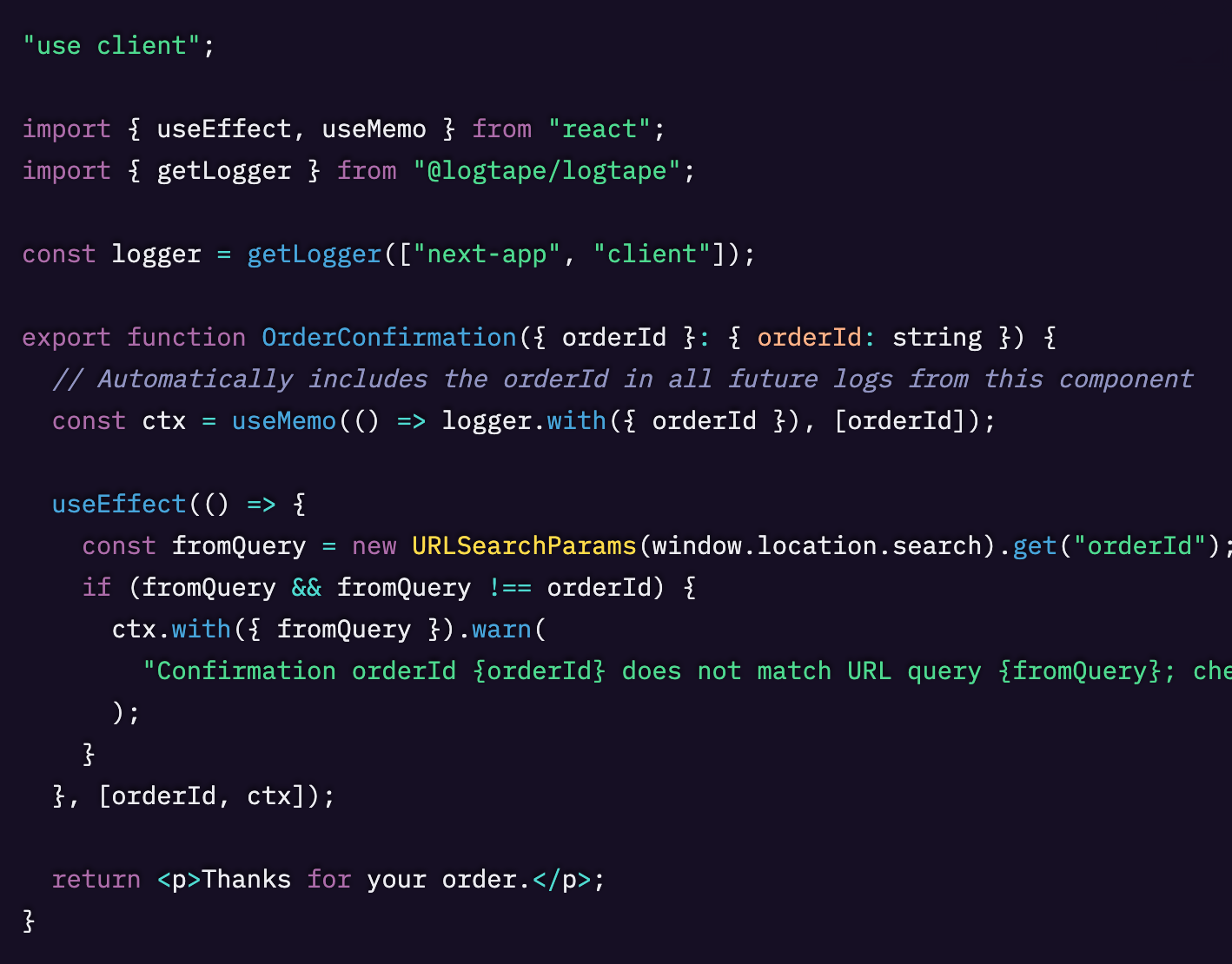
LogTapeとSentryを用いた構造化ロギングのベストプラクティスについてより深く知るには、私の記事「【LogTape & Sentry】トレースに紐づく構造化ログ」をご覧ください。
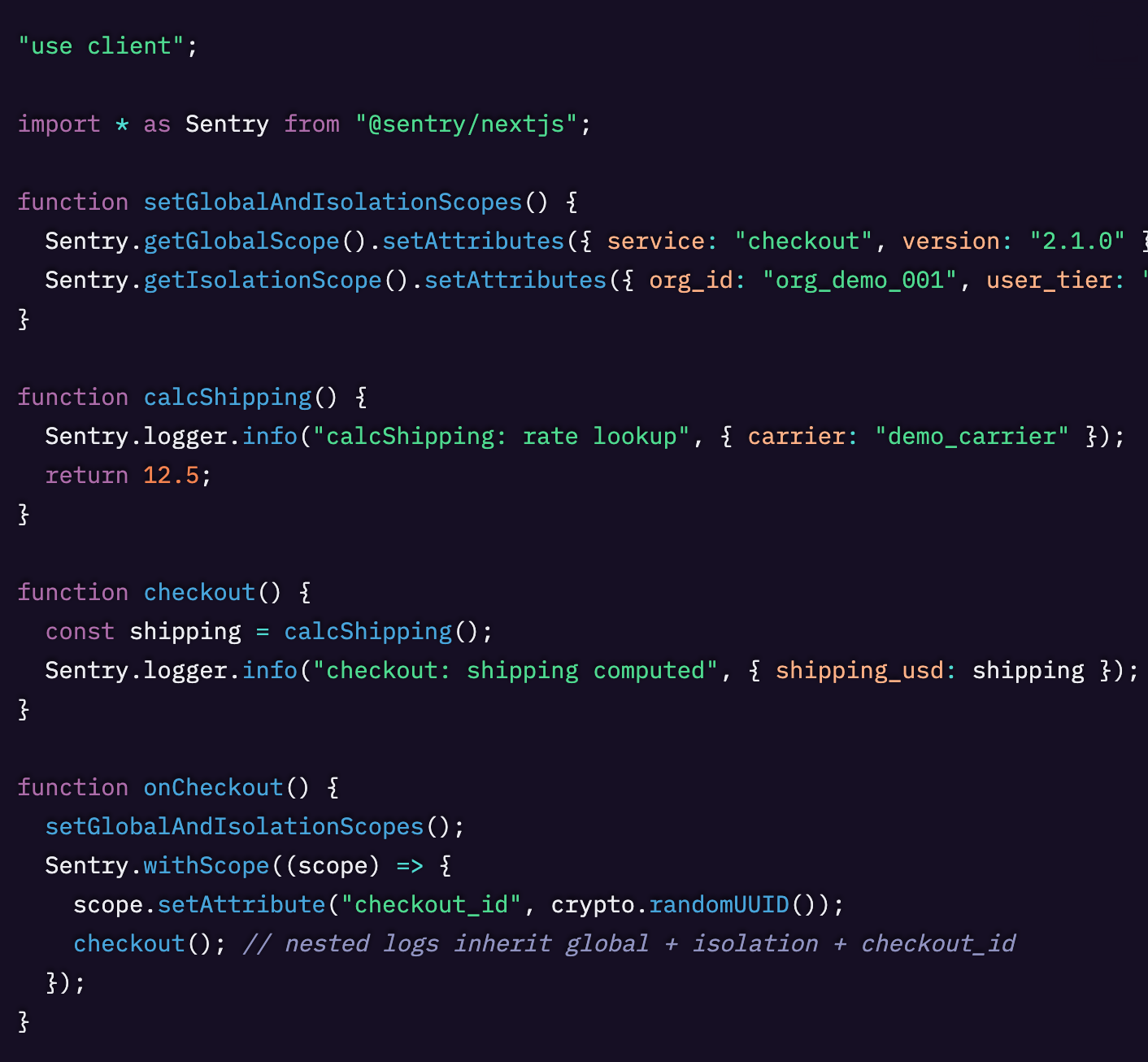

トレースに紐づいたログをエンドツーエンドで取得する
最後に、ログから単なるメッセージ以上のものを得たいと考えます。必要なのは、有用なデバッグ情報を含んだ構造化データです。ログを見たときに、それがどこから来たのか、何がきっかけで発生したのか、そのリクエストの一部として他に何が起きていたのかを把握できるようにしたいのです。
トレーシングは、アプリ全体にわたるリクエストの実行とタイミングを監視します。もしアプリのユーザーに対して遅延やエラーを引き起こす関数やサービスが存在する場合、トレーシングデータを使って情報を収集し、最終的に問題を特定します。
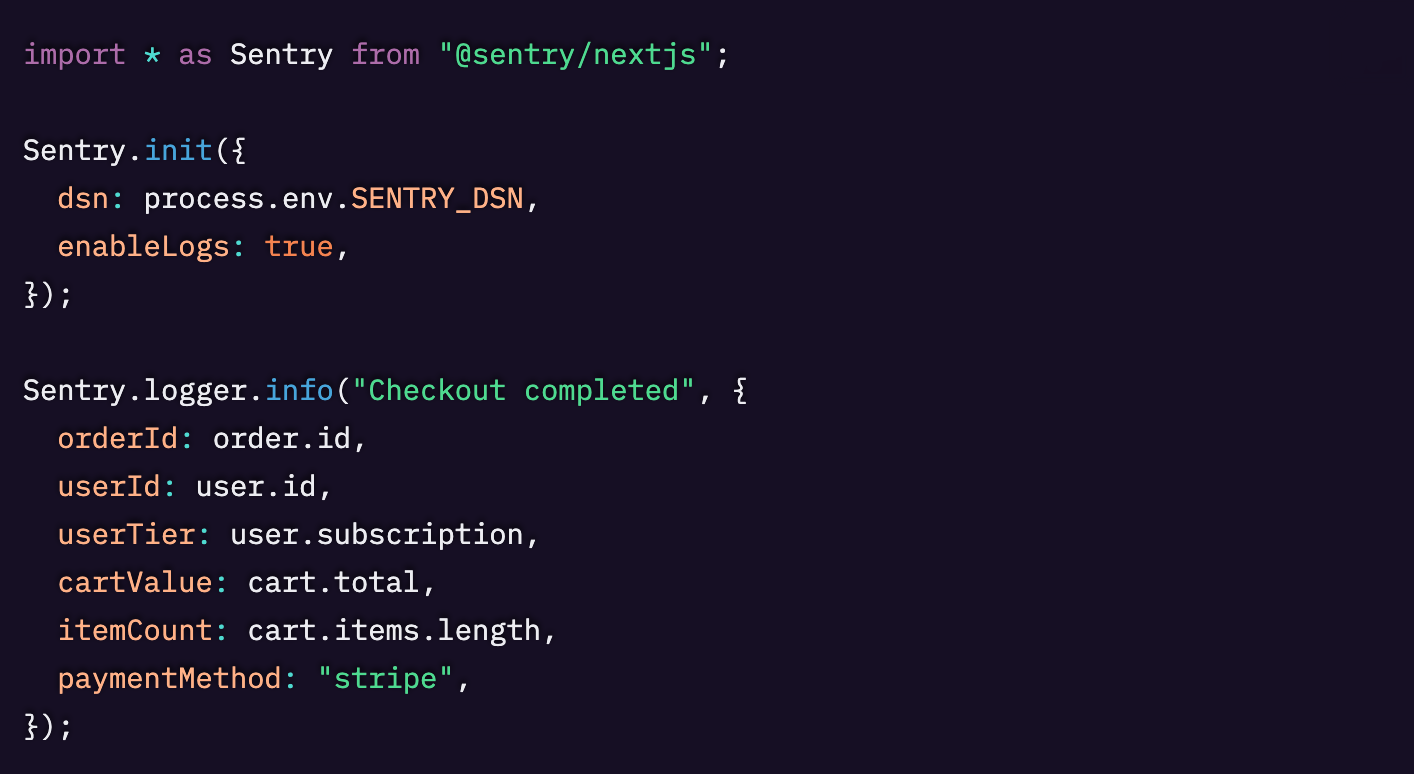
Sentryを設定すると、すべてのリクエストに一意の「Trace ID」が割り当てられ、そのリクエストに関連するすべてのデータが紐づけられます。
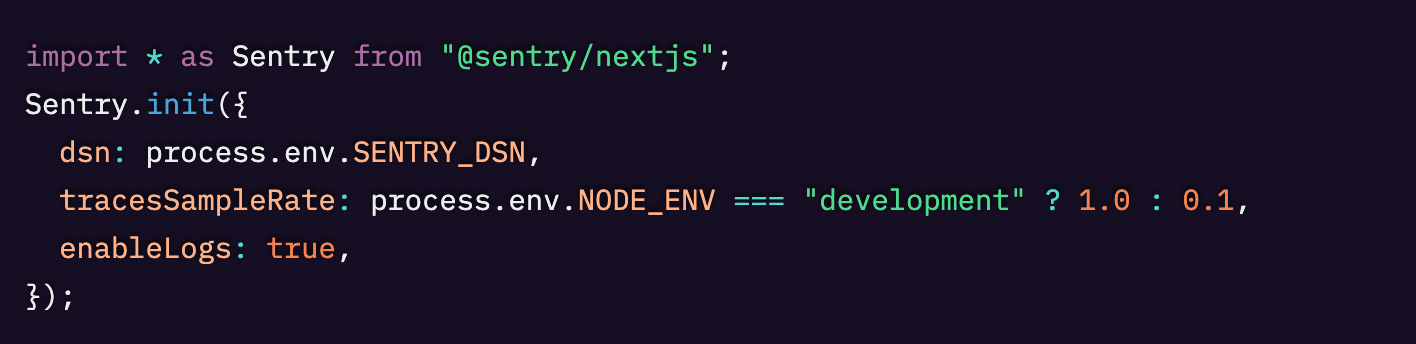
Sentryのセットアップウィザードを使用すると、Next.jsアプリにトレーシングとロギングを自動的に組み込むことができます。
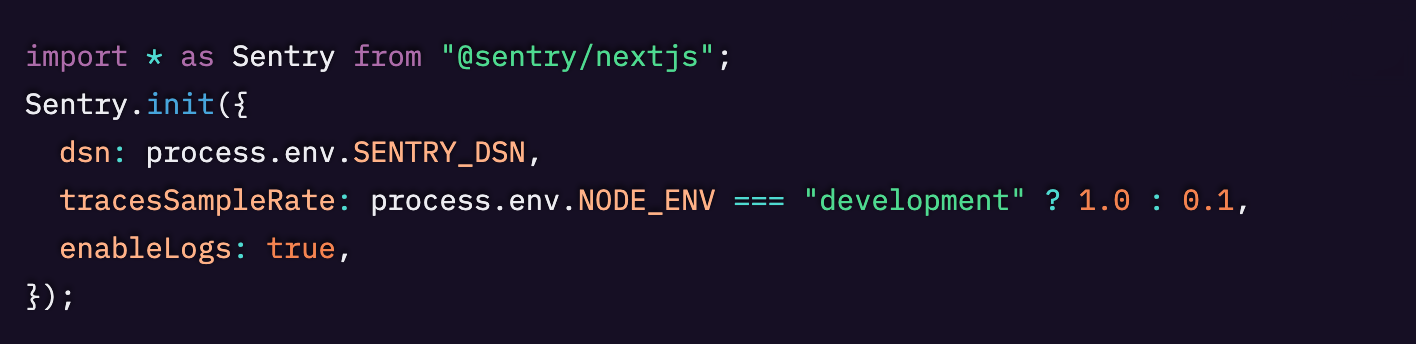
最終的に、以下のような3つのファイルが用意されているはずです。

Explore > Logsでは、構造化データの任意のプロパティに基づいてログを検索できます。
Sentryは、environmentのような有用な属性をいくつか自動的に付与します。これにより、このログが開発サーバーからのものであることが分かります。このログにはbrowser属性も自動的に付与されており、このリクエストがChromeから送られたことが分かります。右側にChromeのアイコンが表示されているのにも気づくでしょう。サーバーサイドのログには、これらはいずれも含まれません。
ブラウザからのログのみに絞り込みたい場合は、has: browser や browser.name: Chrome といった検索を使用できます。
ログがどこから出力されたのかを明確にするために、serviceやcomponentといった属性をログに追加するのは一般的です。Sentryのロガーではスコープを、LogTapeではカテゴリを使うことで、このようなクエリ可能な属性をスタック全体のログに付与できます。
どのようなデータをログに付加すべきかについては、構造化ロギングに関する私の記事を参照してください。
ここに表示されているすべての属性、およびログに追加した任意のデータは、すべて検索可能です。同じリクエストに属する他のログを確認するには、Trace IDをクリックするだけです。

次のステップ
Next.jsアプリ全体をカバーするロガーの設定は最初の大きなステップですが、どのようにログを計測し、そのデータをどう活用するかが本当に重要です。
- 高カーディナリティなデータを多く含む構造化ログを実装する。
- ログを発生させたサービスやコンポーネント名などのコンテキストデータを追加する。
- 既存のログを見直し、古いconsole.logを置き換えていく。
- ログのクエリ方法について理解を深める。
有用な高カーディナリティデータを豊富に含んだ構造化ログを用いることで、新たな問題が発生した際に、迅速にデバッグできるようになります。自分でクエリを書くことも、ダッシュボードを設定して集計データを可視化することも可能です。

自然言語でログをクエリするために、SentryのSeer AIを試してみてください。Sentry MCPサーバーを利用するか、ログエクスプローラーページの「Ask Seer」ボタンをクリックします。現在順次提供が進んでおり、ログデータやログと関連付けられる他のデータから、カスタムダッシュボードウィジェットの作成をSeerに依頼することも可能です。
今すぐログを追加し、すべての領域をカバーしておけば、明日のバグ対応ははるかに取り組みやすくなります。
Next.js ロギングに関するFAQ
■ なぜクライアントコンポーネントから同じログが2回表示されるのですか?
App Routerでは、use clientコンポーネントも初期HTMLを生成するためにサーバー上でレンダリングされ、その後ハイドレーション時にブラウザでも再度実行されます。そのため、コンポーネント本体内のログは2回表示されることがあります(上記課題 2参照)。ブラウザでのみ実行したい処理はuseEffect内に記述するか、レンダリング時にログを出す必要がある場合はtypeof window !== ‘undefined’でガードしてください。開発環境では、ReactのStrict Modeによって一部のeffectが二重に実行されることがあり、SSRが原因でなくてもuseEffect内のログが重複する場合があります。
■ ミドルウェア、サーバー、クライアントのログを1つのリクエストに紐づけるにはどうすればよいですか?
リクエストごとに1つの相関ID(通常はTrace ID)を生成し、Edge、Node、ブラウザのすべてのログに付与する必要があります。これは上記課題 3で説明されている内容であり、上記のSentry設定(sentry.edge.config.ts、sentry.server.config.ts、instrumentation-client.tsの初期化)によって実現されます。これにより、ランタイムをまたいで1リクエストにつき1つのトレースが作成されます。可観測性基盤にこのIDを伝播させることで、各ファイルごとにヘッダーやロガーフィールドを手動で扱うよりも効率的に管理できます。
■ PinoやNext-Loggerはどうですか?
上記課題1と同様の制約があります。これらはNode向けに構築されており、そのままではEdgeのミドルウェアや関数には対応していません。Edgeでログを扱わない場合(専用API、ワーカー、スクリプトなどNode限定の用途)には適していますが、ミドルウェア、Edgeルート、ブラウザで一貫したトレーシングとロギングを行いたい場合は、前述のようにユニバーサルランタイム対応のロガー、またはSentryのロガーを使用してください。
Original Page: Logging in Next.js is hard (But it doesn’t have to be)
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。