Article by:
私は最近、マルチエージェント型のリサーチシステムを構築していました。アイデア自体はシンプルです。「PythonバックエンドをRustへ書き換えるべきか?」のような議論の分かれる技術トピックを与えると、3つのエージェントがそれぞれ役割を担います。Advocate は賛成側を主張し、Skeptic は反対側を主張し、Synthesizer は両者のブリーフを先入観なしに読み込んで、バランスの取れた分析を生成します。各エージェントはそれぞれ異なるモデル、異なるツール、異なるシステムプロンプトを持っています。
テストではうまく動いていました。しかし、そのうち Synthesizer が片側に強く寄った分析を繰り返し生成していることに気づきました。間違っているわけではないのですが、明らかに偏っていたのです。たしかに Sentry のモノレポをRustへ書き換えるのは悪いアイデアかもしれませんが、本来なら賛成になるべきだと明確に分かっているケースでも反対寄りの結論になっていました。
最終的に原因をたどると、Skeptic 側の web_search ツールに行き着きました。Advocate はクエリごとに3〜4件のしっかりしたデータポイントを返していました。一方 Skeptic は、データとうまく一致しない別の検索語を使っており、結果として汎用的な検索結果を1件返しているだけでした。そのため、Advocate のブリーフには引用付きの十分な根拠がありましたが、Skeptic のブリーフは……雰囲気だけになっていました。
Synthesizer は、合理的な読み手なら当然するであろう判断をしただけです。より根拠が揃った側の主張を、より重く扱ったのです。
問題は、ある1つのエージェント内のツール呼び出しにありました。そしてその問題が、2段階後にまったく別のエージェントへ渡される入力品質を静かに劣化させていたのです。私がそれを発見できたのは、トレースをクリックしながら各ステップのツール出力を順番に読み進めたからでした。

マルチエージェントのオブザーバビリティとは?
マルチエージェントのオブザーバビリティとは、複数のAIエージェントがどのように協調し、作業を引き継ぎ合い、互いの意思決定へ影響を与えているかを可視化することです。
おそらく、単一エージェントのオブザーバビリティについてはすでにご存じでしょう。1本の推論チェーンがあり、いくつかのツール呼び出しがあり、最終的なレスポンスが返る、というものです。マルチエージェント版では、1つのエージェントの出力が別のエージェントの入力になる、相互接続された推論チェーンのグラフ全体を追跡します。このグラフのどこか1か所で失敗が起きると、その後段すべてを静かに壊してしまう可能性があります。
もし、いくつかのツールを持つ単一エージェントを動かしているだけなら、通常のエージェントオブザーバビリティで十分です。しかし、エージェント同士が他のエージェントを呼び出したり、サブタスクを委譲したり、並列実行した結果を後から統合したりし始めた瞬間、必要になる可視性のレベルは別物になります。
なぜ単一エージェント向け監視では不十分なのか
既存のエージェント監視では、「Skeptic が3.1秒で実行され、2,400トークン消費した」ということは分かります。しかし、それだけでは、Skeptic の web_search が弱い検索結果しか返していなかったこと、その結果生成されたブリーフが Advocate に比べて薄かったこと、そして Synthesizer が片方の入力品質の低さによって偏った分析を生成したことまでは分かりません。
これが破綻する理由は、主に3つあります。
まず、責任の所在が分散していることです。最終出力が間違っていたとしても、単一のエージェントだけを責めることはできません。Advocate はツールから得た情報を元に合理的な主張を組み立てていましたし、Synthesizer も受け取った情報を合理的に統合していました。問題は両者の相互作用の中にあり、単一エージェントのログだけを見ても発見できません。
次に、最悪の失敗ほど一見正常に見えることです。従来のソフトウェアでは、問題が起きればエラーが投げられます。しかしマルチエージェントAIでは、あるエージェントが「もっともらしいが薄い結果」を返し、次のエージェントがそれを疑わず取り込み、最終出力が返る頃には、弱いデータが何段階もの推論を経て自信満々に要約されています。生の入力同士を比較しない限り、その問題には気づけません。
さらに、すべての経路をテストできないという問題があります。5つのツールを持つ単一エージェントであれば、各ステップで取り得る行動は5通りです。しかし、5つのツールを持つ3つのエージェントが並列実行され、後で結果を統合する場合、可能な実行経路の数は膨大になります。すべての組み合わせを事前テストすることはできないため、本番環境で実際に何が起きているかを観測する必要があります。
多くの「マルチエージェント」は実際には単一エージェント
先へ進む前に、正直に言っておきたいことがあります。私は最初、この実験環境でマルチエージェント型のスタートアップアイデア検証システムを作りました。しかし途中で気づきました。これは偽物のマルチエージェントだったのです。
「Market Analyst」が「Technical Advisor」へ引き継ぎ、さらに「Devil’s Advocate」へ渡す、という構成は、実際にはツールを分けただけの単一エージェントに過ぎません。すべてのツールを持った1つのエージェントと包括的なシステムプロンプトを用意すれば、より低レイテンシかつ低コストで同じ結果を得られます。
Microsoft の Cloud Adoption Framework もこれを明確に述べています。「役割分離が必要だからといって、複数エージェントが必要だと決めつけてはいけない。役割が異なれば複数エージェントを想起するかもしれないが、それだけでマルチエージェントアーキテクチャが正当化されるわけではない」。
マルチエージェント構成が本当に価値を持つのは、次のような場合です。
- 目的同士が本当に対立している場合です。同じプロンプト内で「賛成を主張しろ」と「反対を主張しろ」を同時に与えると、どちらについても中途半端な出力になります。生成役と批評役は分離されている必要があります。そうでなければ、批評役は手加減してしまいます。
- 情報を分離する必要がある場合です。もし Agent A が Agent B の結果を見ることで判断が偏ってしまうなら、両者は同じコンテキストウィンドウを共有できません。Advocate / Skeptic 構成や、ブラインド査読がその例です。
- 役割ごとに異なるモデルを使いたい場合です。リサーチには安価で高速なモデル、統合には高価だが高性能なモデルを使う、といったケースです。単一エージェントでは1種類のモデルしか使えません。
- タスクを並列実行したい場合です。互いに独立した2つのリサーチタスクを別エージェントとして同時実行するほうが、1つのエージェントが順番に処理するより本当に高速になります。
- セキュリティ境界の分離が必要な場合です。ユーザーのPIIを扱うエージェントに、データベースへの書き込み権限を持たせるべきではありません。
もし自分のユースケースがこれらのうち少なくとも2つに当てはまらないのであれば、まずは単一エージェントから始めたほうがよいでしょう。これから説明するようなデバッグの苦しみを避けられます。
一般的なマルチエージェントアーキテクチャパターン
各パターンは異なるトレース形状を生み、それぞれ固有の壊れ方をします。
Orchestrator / Worker
1つのエージェントが、専門エージェントへタスクを振り分けるパターンです。これは OpenAI Agents SDK、LangGraph、カスタム実装で最も一般的な構成です。
POST /api/research (http.server)
└── gen_ai.invoke_agent "Research Director"
├── gen_ai.request "chat gpt-5.4" ← plan subtasks
├── gen_ai.execute_tool "delegate_research"
│ └── gen_ai.invoke_agent "Web Research Agent"
│ ├── gen_ai.request "chat gpt-5.4-mini"
│ ├── gen_ai.execute_tool "web_search"
│ └── gen_ai.request "chat gpt-5.4-mini" ← summarize
├── gen_ai.execute_tool "delegate_analysis"
│ └── gen_ai.invoke_agent "Data Analysis Agent"
│ ├── gen_ai.request "chat gpt-5.4-mini"
│ ├── gen_ai.execute_tool "query_database"
│ └── gen_ai.request "chat gpt-5.4-mini"
└── gen_ai.request "chat gpt-5.4" ← synthesize
構成上発生する問題:オーケストレーターがタスクを誤分類し、間違った専門エージェントへルーティングしてしまうケースがあります。その結果、専門エージェントは「間違った問題」に対して完璧な仕事をしてしまいます。あるいは、十分なコンテキストを渡さなかったために、専門エージェントが不足情報を補完しようとして hallucination を起こす場合もあります。
Advocate workflow .............. 3.2s (parallel)
├── gen_ai.invoke_agent "Advocate"
│ ├── gen_ai.request "chat gpt-5.4-mini" ← plan research
│ ├── gen_ai.execute_tool "web_search" ← find evidence
│ ├── gen_ai.execute_tool "fetch_benchmark" ← get numbers
│ └── gen_ai.request "chat gpt-5.4-mini" ← write brief
Skeptic workflow ............... 2.8s (parallel)
├── gen_ai.invoke_agent "Skeptic"
│ ├── gen_ai.request "chat gpt-5.4-mini" ← plan research
│ ├── gen_ai.execute_tool "web_search" ← find counter-evidence
│ └── gen_ai.request "chat gpt-5.4-mini" ← write brief
Synthesizer workflow ........... 4.1s (sequential, after both)
└── gen_ai.invoke_agent "Synthesizer"
└── gen_ai.request "chat gpt-5.4" ← blind analysis
構成上発生する問題:ツール品質のばらつきです。あるエージェントのツール呼び出しが、別のエージェントより豊富なデータを返した場合、統合エージェントは自然とその側をより重く扱うようになります。統合エージェントには、入力同士の質が不均衡だったことを知る手段がありません。なぜなら、見えているのは完成済みのブリーフだけであり、その背後にある生のツール実行結果は見えていないからです。この記事を書きながら、私自身がまさにこのバグと格闘することになりました。
エージェント間ハンドオフ
エージェント同士が直接制御を引き渡すパターンです。OpenAI Agents SDK の handoff() パターンはこの方式で動作します。
POST /api/chat (http.server)
└── gen_ai.invoke_agent "Triage Agent"
├── gen_ai.request "chat gpt-5.4-mini"
├── gen_ai.handoff "from Triage Agent to Billing Agent"
└── gen_ai.invoke_agent "Billing Agent"
├── gen_ai.request "chat gpt-5.4-mini"
├── gen_ai.execute_tool "check_balance"
├── gen_ai.handoff "from Billing Agent to Dispute Specialist"
└── gen_ai.invoke_agent "Dispute Specialist"
├── gen_ai.request "chat gpt-5.4"
└── gen_ai.execute_tool "file_dispute"
構成上発生する問題:ハンドオフ時の状態管理です。Agent A から Agent B へ制御を渡す際、何を引き継ぐのでしょうか。会話履歴すべてでしょうか。要約でしょうか。それとも直前のメッセージだけでしょうか。すべて渡せばコンテキストウィンドウを圧迫します。一方で要約すればニュアンスが失われます。ハンドオフプロトコル内のバグは最も発見が難しい種類の問題です。なぜなら、それが受け取り側エージェントのバグのように見えるからです。
マルチエージェントのデバッグが特に難しい理由
複数エージェントが関与したときにだけ発生する、特有の問題がいくつかあります。
- 境界を横断する責任特定:マルチエージェントシステムが誤った出力を返したとき、問題になるのは「正しいエージェントがタスクを受け取ったのか」「適切なコンテキストを受け取っていたのか」「良い入力に対して悪い仕事をしたのか、それとも悪い入力に対して良い仕事をしたのか」という点です。エージェントグラフ全体を横断するトレースがなければ、各エージェントのログを個別に読みながら、境界部分で何が起きたのかを再構築するしかありません。
- 静かに連鎖する障害:これは私自身が実際に遭遇した問題です。あるエージェントがもっともらしいレスポンスを返し、下流エージェントがそれを受け入れ、最終出力は間違っている。しかし、すべての span には status: ok が表示されています。こうした問題を捉えるには、各エージェント境界で入力と出力を比較できること、そして各LLM呼び出しにおける完全なプロンプトとレスポンスを確認できることが必要です。トークン数やレイテンシだけでは役に立ちません。
- ハンドオフ間で発生するコンテキストドリフト:エージェントが次へ引き渡す前に要約を行うたび、情報は損失圧縮されます。3回もハンドオフを繰り返せば、元のユーザー意図はほとんど判別できなくなる場合があります。トレース上では、プロンプトを順番に読むことでこれを確認できます。最初のエージェントは完全なクエリを持っていますが、2番目は要約、3番目は要約の要約しか持っていません。修正方法は通常アーキテクチャ側にあります。自然言語ではなく構造化データを渡すことです。しかし、まずドリフトを観測できなければ修正もできません。
- 原因特定できないまま膨らむコスト:私たちのリサーチシステムでは、Synthesizer が gpt-5.4 を使用し、リサーチ担当エージェントは gpt-5.4-mini を使用しています。エージェント単位のコスト追跡がなければ、全体コストが増加していることは分かっても、クエリごとに1回しか動いていない Synthesizer がコスト全体の60%を占めていることには気づけません。
バランス型リサーチシステムを使ったデバッグ例
では、冒頭のバグを私が実際にどう発見したのかを説明します。Synthesizer が偏った分析を生成していたため、その原因を突き止めたかったのです。
並列エージェントの比較
最初に行ったのは、2つのリサーチエージェントのワークフローを、トレースビューで並べて比較することでした。
Advocate workflow .......................... 3.2s ✓
├── gen_ai.invoke_agent "Advocate" ......... 3.1s
│ ├── gen_ai.request "chat gpt-5.4-mini" . 0.6s ← plan
│ ├── gen_ai.execute_tool "web_search" ... 0.2s ← "rust performance"
│ ├── gen_ai.execute_tool "web_search" ... 0.1s ← "rust adoption"
│ ├── gen_ai.execute_tool "fetch_benchmark" 0.1s ← rust benchmarks
│ └── gen_ai.request "chat gpt-5.4-mini" . 1.8s ← write brief
Skeptic workflow ........................... 2.8s ✓
├── gen_ai.invoke_agent "Skeptic" .......... 2.7s
│ ├── gen_ai.request "chat gpt-5.4-mini" . 0.5s ← plan
│ ├── gen_ai.execute_tool "web_search" ... 0.1s ← "python migration costs"
│ └── gen_ai.request "chat gpt-5.4-mini" . 1.9s ← write brief
非対称性はすぐに明らかでした。Advocate は3回ツール呼び出しを行っていました。一方、Skeptic は1回だけでした。
ツール実行結果の確認
Advocate 側の web_search span を開いてみると、それぞれ3〜4件のデータポイントが返されていました。
["Rust programs typically run 2-5x faster than equivalent Python...",
"Discord switched from Go to Rust... latency drop from 50ms to 1ms",
"Figma rewrote their multiplayer server... memory usage by 10x"]一方、Skeptic 側の唯一の web_search は、「python migration costs」という検索を行っていました。
["No specific data found for 'python migration costs'. Consider refining your search terms."]その結果、Skeptic は引用なしの一般知識だけを元にブリーフを書いていた一方で、Advocate は3回の検索から10件以上のデータポイントを得ていました。
Synthesizer まで追跡する
次に Synthesizer の gen_ai.request span を開き、プロンプト内容を確認すると、原因ははっきりしました。そこには、引用やベンチマークデータを含む十分に根拠付けられたブリーフと、一般論だけでデータを持たないブリーフの2つが渡されていました。Synthesizer は、より根拠が揃った側を重く扱っていました。これは、統合役として期待される通りの振る舞いです。問題は上流にありました。
修正方法
選択肢は2つありました。1つは、最初の検索結果が弱かった場合に複数の検索クエリを試すよう、Skeptic のプロンプトを改善すること。もう1つは、より広い検索語句にも対応できるよう web_search ツール側を改善することです。私は両方を行いました。その後トレースを確認すると、両エージェントとも同程度に根拠付けられたブリーフを生成するようになっていました。
根本原因は、ある1つのエージェントにおける弱いツール実行結果でした。そしてそれが、情報の非対称性としてパイプライン全体へ連鎖していたのです。もしトレース上ですべてのツール呼び出しとすべてのプロンプトを確認していなければ、私は Synthesizer のプロンプトが偏っているのだと誤解していたでしょう。
マルチエージェントフレームワークの自動インストルメンテーション
Sentry は OpenAI Agents SDK、LangGraph、その他のフレームワークを自動インストルメントします。対象パッケージが検出されると、統合は自動的に有効化されます。以下は、バランス型リサーチシステムにおける設定例です。
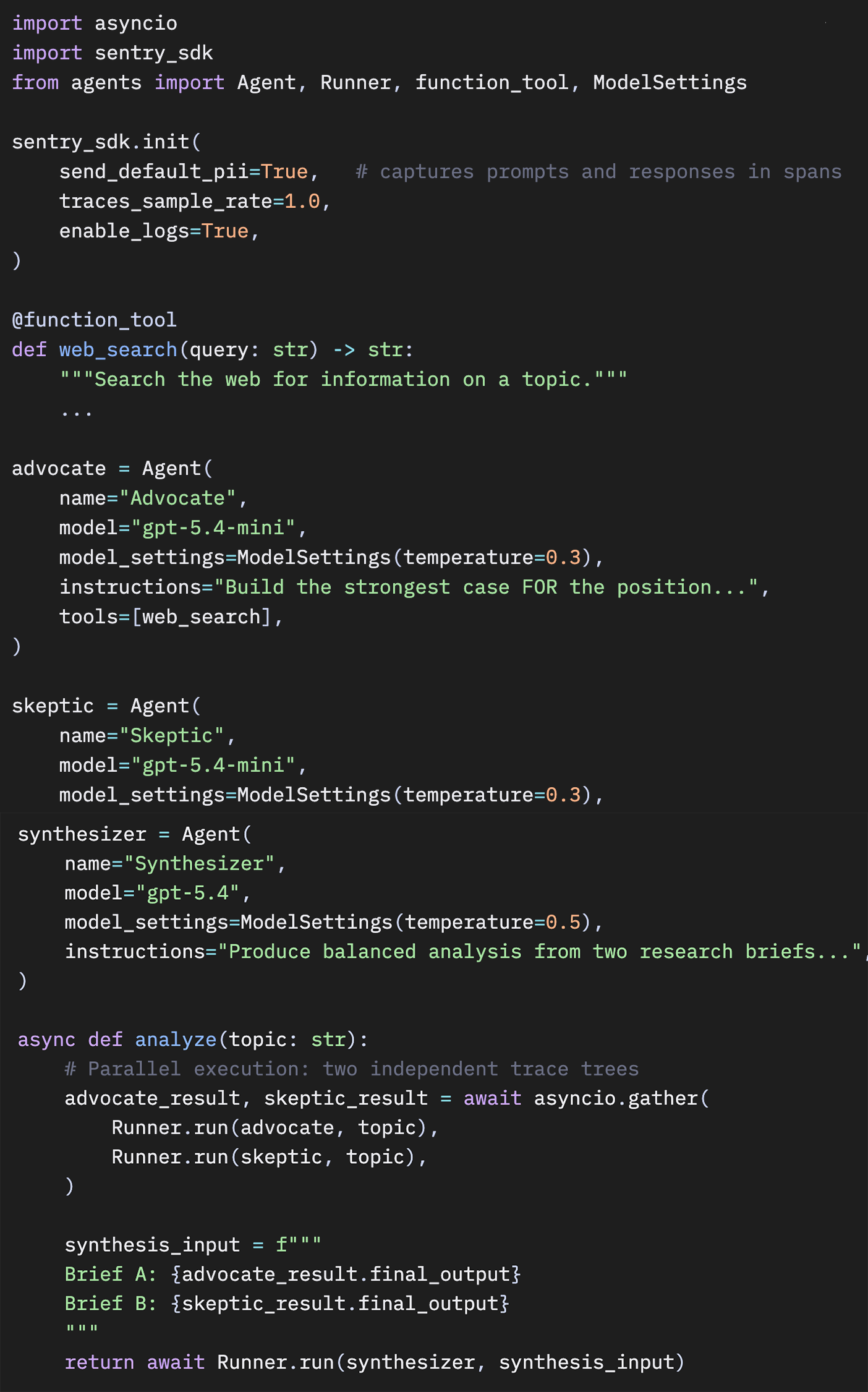
SENTRY_DSN は環境変数から読み込まれます。send_default_pii=True は、span 内でプロンプトとレスポンスをキャプチャするための設定であり、前述したハンドオフ問題をデバッグするうえで不可欠です。
SDK は、各エージェントに対して gen_ai.invoke_agent span、ツール呼び出しに対して gen_ai.execute_tool span、そしてトークン数やモデル情報を含むLLM呼び出しに対して gen_ai.request span を生成します。
Vercel AI SDK や LangChain を使用した JavaScript / TypeScript 環境では、AI関連ルートを100%キャプチャするために tracesSampler を使用します。
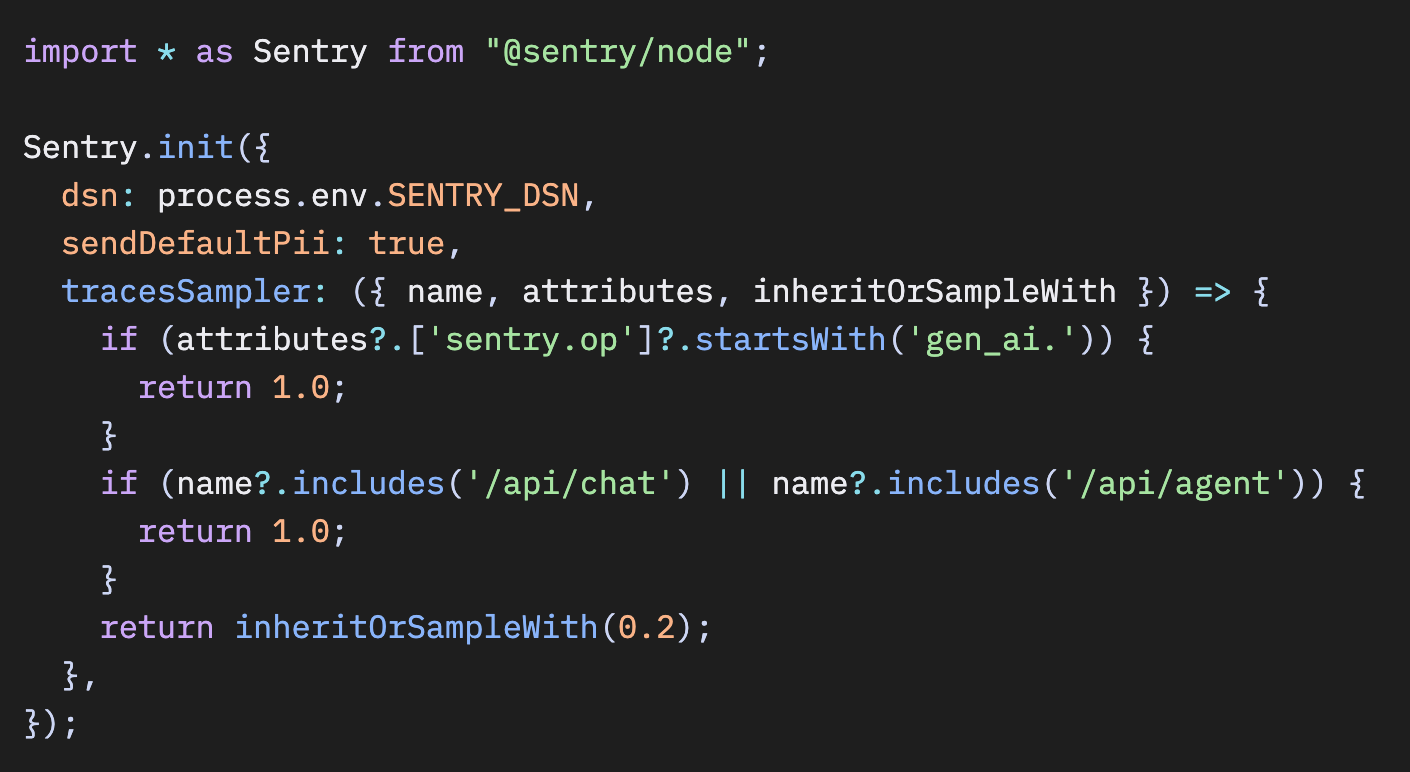
AIトレースを100%サンプリングすべき理由については、関連記事「すべてをサンプリングせず、AIトレースを100%取得する」を参照してください。
マルチエージェント向けダッシュボードの構築
事前構築されたエージェントダッシュボードでは、モデル単位やツール単位の集計を確認できます。しかし、マルチエージェントシステムでは、エージェント単位で分析できるようにする必要があります。
Sentry CLI を使うことで、たとえば次のようなダッシュボードを構築できます。
エージェントごとのコスト分析:

これによって、Synthesizer がクエリごとに1回しか実行されていないにもかかわらず、全体コストの60%を占めていることが分かりました。理由は、gpt-5.4-mini ではなく gpt-5.4 を使用しているためです。
エージェントごとのツール信頼性:
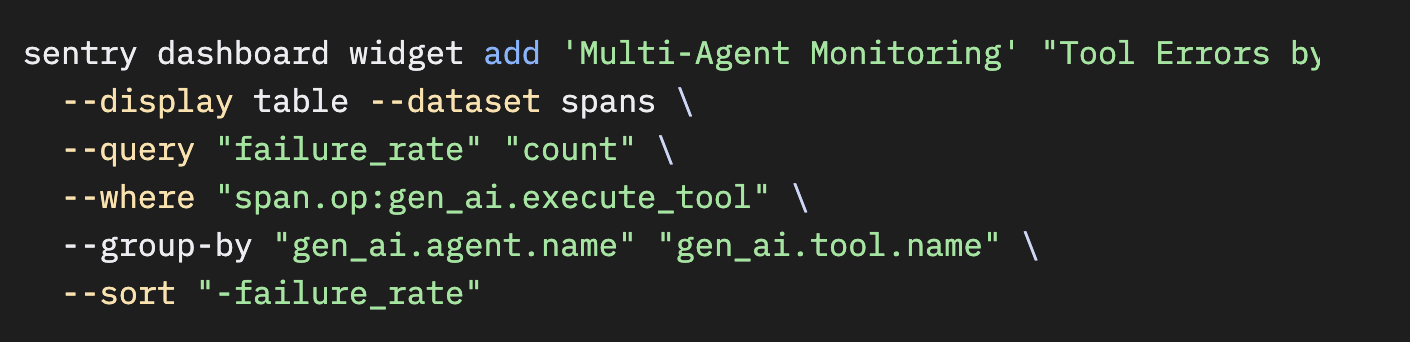

似たような処理を行うエージェント同士であれば、実行時間も近いはずです。並列エージェント間で大きな実行時間差がある場合、通常は片方が想定より多く、あるいは少なくツール呼び出しを行っていることを意味します。
マルチエージェントシステムを構築するなら私が勧めること
このシステムをデバッグした経験と、大量のトレースを読んだ結果として、私が勧めたいことがあります。
すべてのエージェント境界で、プロンプトとレスポンスを記録すること。
これは send_default_pii=True フラグで有効になります。トークン数から分かるのはコストだけです。しかし、実際にバグを発見できるのは、プロンプト、レスポンス、そしてツールの入力/出力データです。マルチエージェント特有の問題の大半は、エージェント間のハンドオフ境界で発生します。
エージェントには分かりやすい名前を付けること。
トレースビューに「Agent」や「Sub-Agent」とだけ表示されていても何も分かりません。「Advocate」「Skeptic」「Synthesizer」と表示されていれば、追跡可能なストーリーになります。
並列エージェント同士を比較すること。
エージェントが並列実行され、その結果が統合される場合、統合エージェント自身には、入力品質が均等だったかを判断できません。しかし、トレースを見れば人間には分かります。同じような役割を持つエージェント間で、ツール呼び出し数、トークン使用量、実行時間に非対称性がないか確認してください。
100%サンプリングすること。
これは単一エージェント以上に、マルチエージェントで重要です。特定のツール結果の組み合わせでのみ発生する障害は、50回に1回しか起きないかもしれません。サンプリング率が10%なら、その障害を1回捕捉するまでに500回の実行が必要になります。設定方法については、「AIトレースを100%サンプリングする方法」を参照してください。
ツール障害率はグローバルではなく、エージェント単位で監視すること。
あるツールが全体では5%しか失敗していなくても、特定エージェントでは20%失敗している場合があります。原因は、そのエージェント特有のクエリ生成方法かもしれません。グローバル平均では、エージェント単位の問題は隠れてしまいます。
システム全体のトレースと接続すること。
web_search ツールの遅延原因は、エージェントではなく上流API側のレート制限かもしれません。既存の分散トレース内にマルチエージェントトレースを組み込めば、システム全体を横断して確認できます。
始め方
すでに Sentry を使ってエージェント監視を行っている場合、マルチエージェントトレースは自動的に機能します。SDK はエージェント呼び出し、ハンドオフ、ツール呼び出しを自動検出します。
新規に始める場合は、次の手順になります。
-
pip install sentry-sdk または npm install @sentry/node を実行する
-
traces_sample_rate=1.0 と send_default_pii=True を指定して初期化する
-
マルチエージェントワークフローを実行する。span は Sentry の trace view に表示される
10種類以上のフレームワークにおける設定方法については、「【AIエージェントのオブザーバビリティ】エージェント監視 開発者ガイド」を参照してください。
FAQ
■ マルチエージェントオブザーバビリティとは?
マルチエージェントオブザーバビリティとは、複数のAIエージェントが協調し、並列実行し、あるいはタスクを引き渡しながら動作するシステム全体を、エンドツーエンドで可視化することです。個々のエージェントの振る舞いだけでなく、エージェント間の相互作用も追跡します。たとえば、各境界でどのようなコンテキストが引き渡されたのか、あるエージェントの出力が下流エージェントにどのような影響を与えたのか、そして障害がチェーン内のどこで発生したのか、といった点を確認できます。
■ 単一エージェントと比べて、マルチエージェントAIのデバッグは何が違うのでしょうか?
単一エージェントのデバッグは直線的です。LLM呼び出しやツール呼び出しを順番に追跡すれば済みます。一方、マルチエージェントのデバッグはグラフ構造になります。障害は、あるエージェント内のツール呼び出しから発生し、エージェント間の境界を静かに伝播し、最終的にはまったく別のエージェントで偏った、あるいは誤った出力として現れることがあります。問題は個々のエージェントの推論ではなく、エージェント間の相互作用に存在している場合が多いのです。
■ どのような場合に、単一エージェントではなくマルチエージェントを使うべきでしょうか?
目的が本質的に対立している場合(生成役と批評役など)、情報を隔離する必要がある場合(ブラインドレビューなど)、異なるモデルが異なる役割を担う場合、タスクが並列化によって恩恵を受ける場合、あるいはセキュリティ境界によって分離が必要な場合です。複数ツールを持つ単一エージェントで実現できるなら、その構成にするべきです。マルチエージェントシステムは、協調のオーバーヘッドによってコストが超線形的に増加します。
■ スパンにもっとコンテキストを追加するにはどうすればよいですか?
span.setAttribute() を使用して、ユーザーID、リクエストID、フィーチャーフラグなどの関連データを付加できます。コンテキストが多いほど、Sentryでのフィルタリングやデバッグが容易になります。
■ マルチエージェントオブザーバビリティをサポートするツールには何がありますか?
Original Page: Debugging multi-agent AI: When the failure is in the space between agents
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。