Article by: Sergiy Dybskiy
ここ数年で、ソフトウェアの作り方は大きく変化しました。一方で変わっていないのは、そのソフトウェアが最終的に「実際の人間」に届くという事実です。あなたや私、そして私の母のような人たちです。
そして、そうしたユーザーが必然的に何かしらの不具合に遭遇したとき、アプリケーションの開発者であるあなたは、何が壊れたのか、どこで壊れたのか、そしてそれをできるだけ早くどう修正するのかを理解するための適切なツールとコンテキスト、そして認識を備えている必要があります。
私たちは日々、「自己修復するソフトウェア」に少しずつ近づいています。Next.jsアプリケーションを構築し、バックエンドサービスとしてSupabaseを利用している場合、以下で説明するツールは、より高品質なソフトウェアを生み出すことと、すり抜けてしまった問題を最小限の影響で修正するという、自己完結的なループに一歩近づく助けになります。
エージェントが生み出すスタック問題
AI支援開発には特有の失敗モードがあります。エージェントは動作するコードを生成できますが、そこにオブザーバビリティが組み込まれていないことが多いという点です。その結果、Next.jsアプリがSupabaseと通信する方法が3種類(直接Postgres接続、Supabase JS SDK、そしてDrizzle、エージェントが戦略を切り替え続けたため)混在することもあり得ます。さらにDeno上で動くEdge Functionが加わり、実行時に何が起きているのかを統一的に把握できない状態に陥ります。
もう一つの失敗モードはより見えにくいものです。エージェントはインデックスを忘れることがあります。ローカル環境ではデータが40行程度しかないため問題にならず、N+1クエリを書いてしまうこともあります。しかし本番にデプロイし、データベースが400行に増えると、検索クエリが突然10秒かかるようになります。Sentryはこれを自動的に検出できますが、それは最初から正しく計装されている場合に限られます。
この計装を正しく行うには、SupabaseとSentryがどのように組み合わさるかを理解する必要があります。
Supabaseの組み込みオブザーバビリティとその限界
Supabaseには堅牢な組み込みオブザーバビリティがあります。ダッシュボードのQuery Performanceパネルでは、どのクエリが最も頻繁に実行されているか、どれが最も時間を消費しているかを確認できます。パフォーマンス問題が発生した際に最初に見るべき場所です。
またAdvisorsは、RLSポリシーの不足などのセキュリティ問題を検出し、重要度に応じて優先順位付けします。Index Advisorは不足しているインデックスを指摘し、それらが本番インシデントになる前に可視化します。

Logsセクションでは、Supabaseのすべてのサブシステムから構造化ログを取得できます。対象にはEdge Functions、Postgres REST API(PostgREST)、コネクションプーラー、ストレージ、cronジョブなどが含まれます。これらのログはダッシュボード上でSQLを使って直接クエリすることも可能です。
これは確かに非常に有用です。ただし、Supabaseの内部で観測できる範囲に限定されるという制約があります。つまり、Supabaseの外側で起きていることまでは見えません。例えば、遅いPostgresクエリがNext.jsフロントエンドのどのユーザーアクションによって発生したのか、あるいはEdge FunctionのタイムアウトがAPIレイヤー全体にどのようなエラーの連鎖を引き起こしたのか、といった因果関係は把握できません。こうした情報を得るには、フルスタックを横断した分散トレーシングが必要になります。
SupabaseログをSentryに接続する
SupabaseのデータをSentryに取り込む最も簡単な方法は、log drainを使うことです。Supabaseダッシュボードの「Logs > Drain」で送信先を追加し、SentryのDSNを貼り付けると、そのSupabaseプロジェクトのすべてのログが対応するSentryプロジェクトへ流れ込むようになります。
この仕組みについて、いくつか重要な点があります。
- 現時点では「全量送信(all-or-nothing)」であり、Supabase側でログレベルによるフィルタリングはできません。
- ログがSentryに入った後は、Log Explorer上で severity:warn や severity:error のようにフィルタリングできます。
- log drainはNext.jsアプリやEdge Functionsとは分けて、専用のSentryプロジェクトに送るのが推奨されます。これによりシグナルが整理され、プロジェクトごとのアラート設定も容易になります。
この設定を行う理由は単なる利便性ではありません。Sentryはこれらのインフラログとアプリケーション層のトレースを相関付けることができるからです。例えばEdge Functionでエラーが発生した場合でも、Next.jsのページロード → APIルート → Edge Function → Postgresクエリというリクエスト全体の経路を、各スパンのタイミング付きで追跡できます。
このセットアップの詳細な手順については、Supabase log drain monitoringのレシピを参照してください。
Next.jsとSupabase Edge Functionsのインストルメンテーション
ここが、エージェント生成されたセットアップの多くが失敗するポイントです。Next.jsはフルスタックフレームワークであり、複数のランタイムで動作します。サーバー側ではNode.js、ブラウザ側ではV8、そして場合によってはエッジランタイムでも実行されます。一方、Supabase Edge FunctionsはDeno上で動作します。これらは同一の実行環境ではなく、それぞれに別のSentryプロジェクトと別のSDK設定が必要になります。
Sentry CLIはこの検出を自動的に処理します。

Next.jsアプリでは、sentry.server.config.ts にSupabaseのインテグレーションを含めることで、データベースクエリの自動インストルメンテーションを有効にできます。
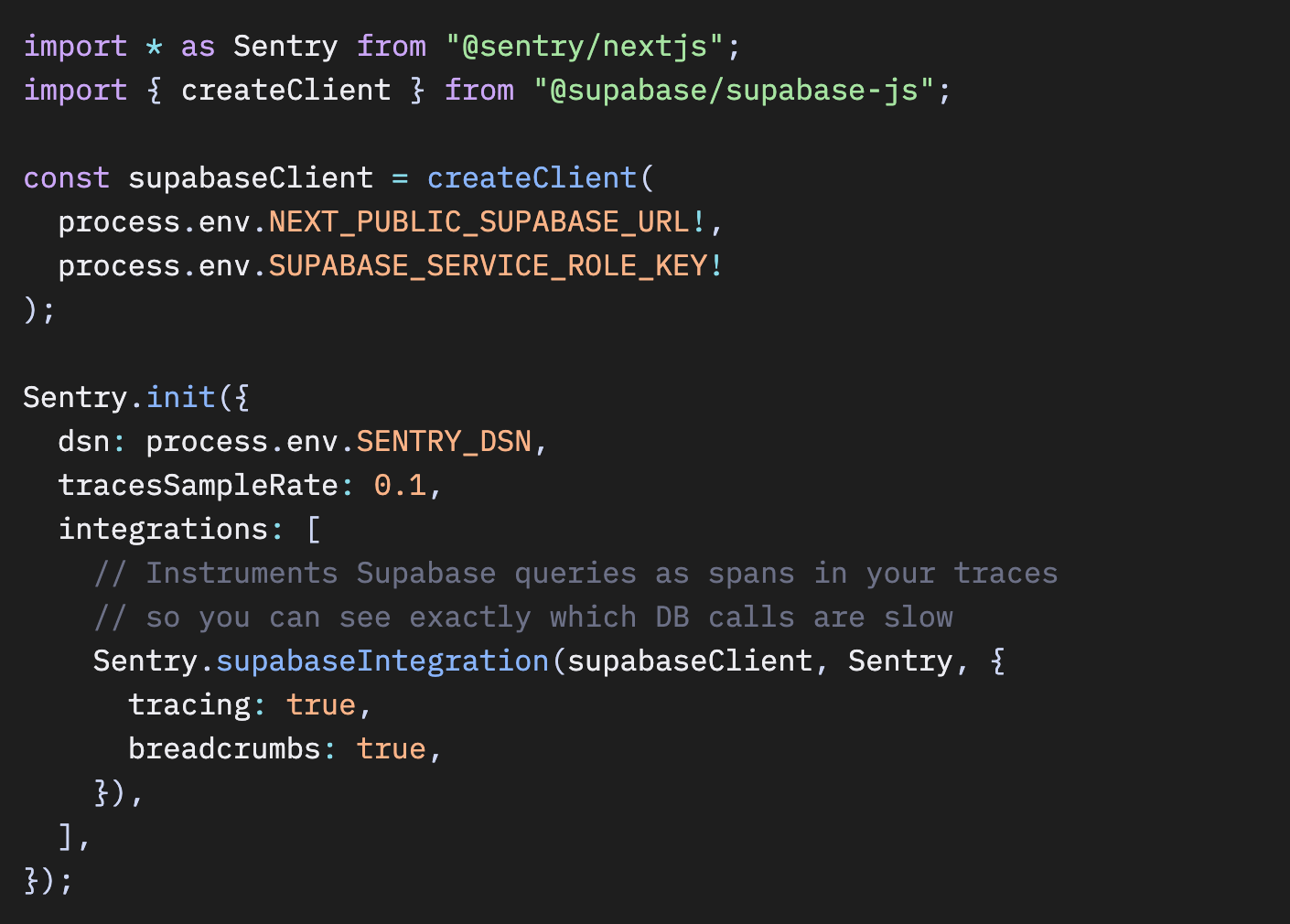
Supabaseインテグレーションがない場合、トレースではAPIルートが遅いことは分かりますが、どのクエリが原因だったのかまでは特定できません。インテグレーションを有効にすると、すべてのSupabase SDK呼び出しが、タイミング情報付きの名前付きスパンとして記録されます。利用可能な機能の全リストについては、Next.jsのインテグレーションドキュメントを参照してください。
Deno上で動作するEdge Functionsの場合は、他のすべてのインポートより前に、各関数の先頭でSentryを初期化します。

Sentryでプロジェクトを分ける理由は、SentryのAI機能(後述)がIsuueを分析する際に、プロジェクト単位のコンテキストで動作するためです。Next.jsのエラー、Denoのエラー、Postgresログを同一プロジェクトに混在させると、その分析結果はノイズが増え、精度も有用性も低下します。
エージェントに正しく計装させるためのセットアップ
エージェントがアプリを正しくインストルメントできるかどうかは、最新かつ完全な設定を生成できるかどうかにかかっています。これを左右する要素は主に2つあります。
MCPは学習データより重要
SentryとSupabaseの両方にはModel Context Protocol(MCP)サーバーがあります。SentryのMCPにアクセスできる状態であれば、コーディングエージェントはトレーニングデータに依存して推測するのではなく、実際のIssue、トレース、プロジェクト設定をリアルタイムで取得できます。
これは特に重要です。SentryのSDKは大きく進化しており、古い学習データだけを参照するエージェントは、「エラー監視専用のツール」として誤って設定してしまうことがよくあります。その結果、パフォーマンストレーシングが完全に抜け落ちるケースが発生します。
Skillsファイル
Claude Codeでは .claude/、Cursorなどでは .agents/ といったディレクトリを使います。これらのファイルは、プロジェクト固有のコンテキストをエージェントに提供し、セッションをまたいでも保持されます。Sentryが提供しているAgent Skillsの詳細についてはドキュメントを参照してください。
実践的なワークフローとして、Sentryをプロジェクトに追加する場合は、まずSentryのドキュメントにアクセスし、対象フレームワークのSDKを探し、そこに記載されているセットアップ用プロンプトをコピーしてエージェントに渡します。ドキュメントには最新のベストプラクティスと適切なSDKバージョンが含まれています。単に「Sentryを追加して」とエージェントに伝えるのは避けるべきです。その指示でもエージェントは実装しますが、その結果は動作しても正しい構成にはなりません。
エラーを超えたモニタリング
エラーは分かりやすい監視対象ですが、実際に役立つ監視の多くは「エラーではないもの」にあります。
- ログベースのモニターを使うと、ログストリーム内のパターンに対してアラートを設定できます。例えばSupabaseのログをSentryにドレインしている場合、「connection received」ログの件数が1時間あたりの閾値を下回ったときにアラートを発火させるモニターを作成できます。これはエラーではなく、データベース接続に問題がある可能性を示すシグナルです。SentryのUIでは、Alerts > Create Alert > Logs から、メッセージ内容でフィルタし、カウントの閾値を設定し、個人またはチームに割り当てます。
- ダイナミックアラートはまだ通常の閾値が分からない段階で特に有効です。固定値ではなく異常検知(anomaly detection)を使うように設定できます。Sentryの機械学習がトランザクションのレスポンスタイムの「通常状態」を学習し、そのパターンから外れたときにアラートを発火させます。まずはダイナミックな設定から始め、ベースラインが分かってきた段階で具体的な閾値に調整します。
- Sentry CLIにはダッシュボード機能があります。新しいSentry CLIの
dashboardsコマンドを使うと、エージェントが実際のトレースデータからカスタムダッシュボードを構築できます。プロジェクトを指定してアプリケーション用のパフォーマンスダッシュボードを作成するよう依頼すると、アクティブなトランザクションやスパンを解析し、可視化すべき対象を自動で判断します。
出力は完璧ではありません(ウィジェット設定の確認は必要です)が、出発点としては十分で、通常30分かかる作業を約30秒に短縮できます。
Seer:アラートから修正まで
SeerはSentryのAIデバッガーです。Issueの履歴、トレース、Logs、Session Replays 全体にアクセスできます。「どのオープンIsuueが悪化しているか?」や「最も遅いデータベースクエリは何か?」といった自然な質問を投げると、実際のデータに基づいて回答します。
より重要なのはAutofixの機能です。リポジトリを接続してSentryプロジェクト設定で有効化すると、新しいIssueが発生した際にSeerが自動的に原因の推定を行い、必要に応じて修正案のドラフトPRまで生成します。設定によって動作範囲を調整でき、根本原因の提示だけにすることも、テスト更新を含む完全な修正まで行わせることも可能です。
Supabaseのセキュリティアドバイザリーワークフローでは、Supabase MCPがRLSポリシーの問題などのアドバイザリー情報を公開します。Supabase MCPとSentry MCPの両方にアクセスできるエージェントは、それらのアドバイザリーを取得し、SentryのIssueとして登録できます。これによりセキュリティ問題もアプリケーションエラーと同じワークフローに統合されます。その後Seerがそれらを取得し、自動修正を試みることができます。
これが実際の「自己修復するソフトウェア」の姿です。魔法ではなく、新しい問題が発生したときに、それを自動でトリアージ・分析し、開発者が気づく前にコーディングエージェントへ引き渡されるパイプラインです。
Original Page: From vibe code to production-ready: observability for Next.js and Supabase apps
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。