Article by: Rahul Chhabria
必要なものは、すでに手元にそろっています。
Sentry を使っているなら、トレース、構造化ログ、そして新たにアプリケーションメトリクスもあるはずです。多くのチームはデバッグ目的にしか使っていませんが、実はそのデータで、別チームが管理し、別のデータモデルを持ち、別の費用がかかる専用アナリティクスツールに投げていたプロダクトの大半の問いに答えられます(すべてではありません。ギャップについては後ほど正直にお伝えします)。
この記事は、プロダクトアナリティクスツールの存在意義を問うものではありません。開発者がプロダクトインサイトの宝の山の上に座りながら、その問いを他の誰かに外注してきたという事実についての記事です。そうしなくていいのです。
これが今、5年前より重要な意味を持つ理由があります。「プロダクトマネージャー」と「ソフトウェアエンジニア」の境界が曖昧になりつつあるからです。アップタイムやレイテンシだけでなく、採用率・リテンション・ユーザー行動まで考えることが、エンジニアにも求められるようになっています。プロダクトエンジニア(最近はもはや「エンジニア」と同義になりつつありますが)であれば、デバッグに使っているツールで、プロダクトに関する問いの答えを得ることができます。そういう使い方をしてこなかっただけで。
プロダクトの問いはすべて、手元のテレメトリにマッピングできる
「今週、オンボーディングを完了したユーザーは何人いるか?」 これはカウンターメトリクスです:metrics.count("onboarding.completed", 1)。プランの種類、国、流入元など、すでに設定している属性でスライスできます。
「地域別のチェックアウトレイテンシの p95 はどれくらいか?」 これはスパンのディストリビューションです。トレースにはすでにタイミング情報があります。あとはクエリするだけです。
「火曜日にサインアップが落ちたのはなぜか?」 これは構造化ログです。サインアップサービスは signup.failed を reason: email_validation_error や deploy_sha: a3f9b2c といった情報と一緒にログに記録しています。そのログはすでに、リクエスト全体のライフサイクルを示すトレース、エラーが発生したスパン、それを引き起こしたリリースと紐づいています。トレースからワンクリックで Issue に移動でき、Issue からコミットと原因となったコードの行へたどり着けます。
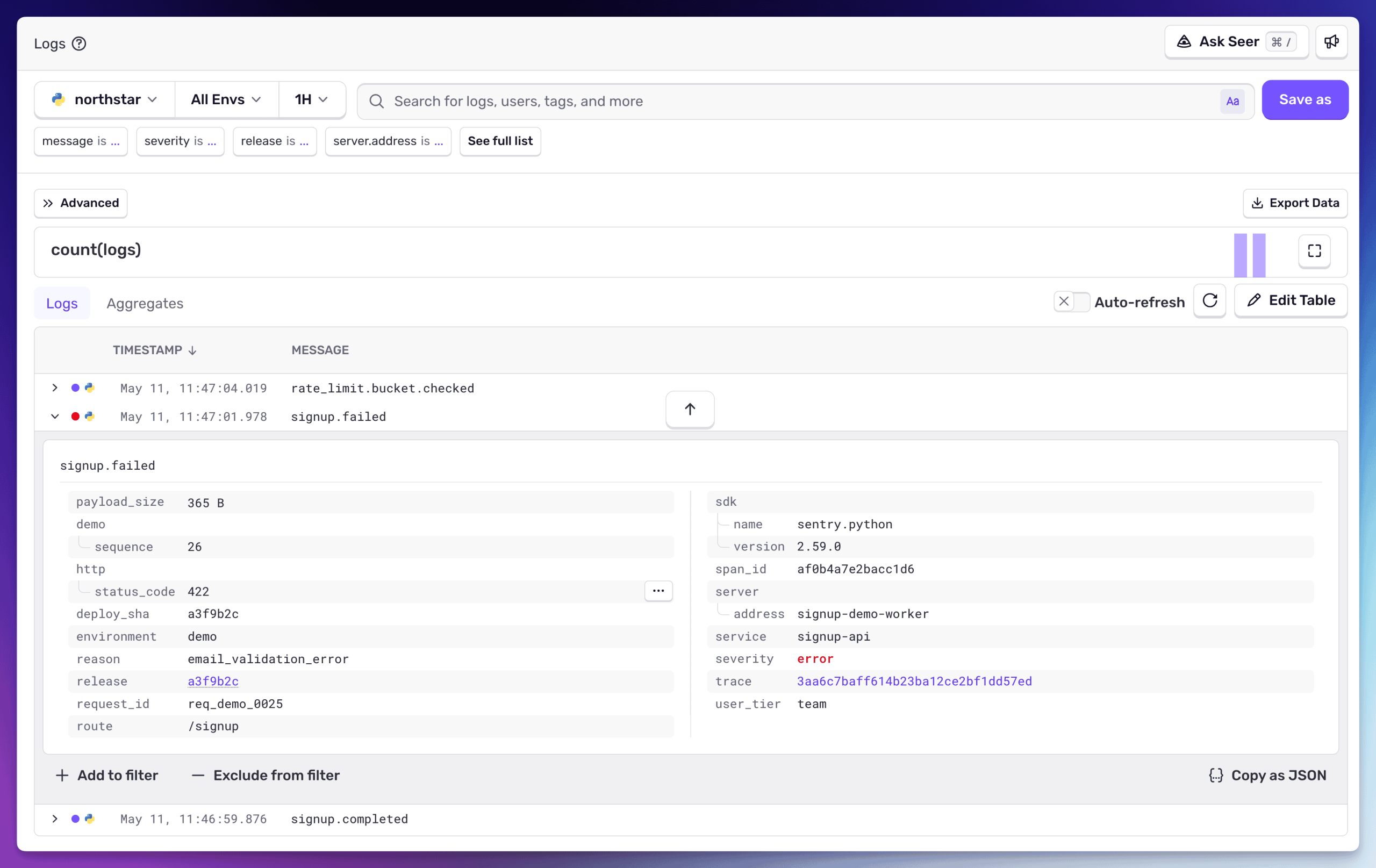
PM がアナリティクスツールに投げているのと同じ質問です。違いは、自分のテレメトリから答えるとき、その答えにはコンテキストが伴う点です。アナリティクスツールは「何が起きているか」を教えてくれます。テレメトリは「何が起きているか」「なぜ起きているか」、そして「責任のあるコードへの直接の道筋」までセットで教えてくれます。
あるクライアントから最近、こんな話を伺いました。アナリティクスツールが問題を知らせてくれるのは被害が出た後ばかりで、先手を打ちたいと。そのクライアントが辿り着いた答えは、すでに収集しているテレメトリにアラートとモニターを設定することでした。ビジネス上重要なメトリクスが下降傾向を示し始めたとき、週次のダッシュボードレビューで気づくより前にアラートが発動します。そしてそのアラートは完全なトレースと繋がったスパンやメトリクスに紐づいているため、別ツールへのコンテキストスイッチなしに、最初からコンテキストを持った状態で調査を始められます。収集するデータを変えたわけではなく、それをどう監視するかを変えたのです。
実際どのようなものか
新しいエクスポート機能のユーザー採用状況を把握したい、パフォーマンスを確認したい、有料ユーザーと無料ユーザーの挙動の違いも見たい、というケースを考えてみましょう。
アナリティクスツールへのインストルメントチケットを作成する必要はありません。スパン、構造化ログ、アプリケーションメトリクスという3つの基本要素がすでに手元にあります。
リクエストレベルのコンテキストにはスパン。 スパンはリクエストがシステムをどう流れ、各処理にどれだけ時間がかかっているかを示します。エクスポート API ハンドラーにはすでにスパンがあります。そこにビジネスレベルの属性(プランでスライスできる export.user_tier など)を追加しましょう。

採用状況、パフォーマンス、エラーを一か所でクエリしてみましょう。

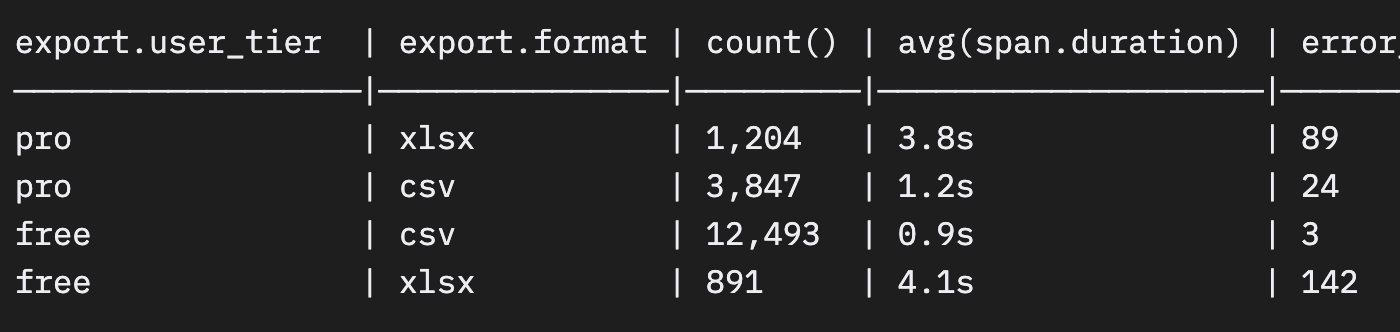
すでにストーリーが見えてきます。xlsx エクスポートは csv の 3〜4 倍遅く、無料プランの xlsx は 16% のリクエストでエラーが発生しています。アナリティクスツールは不要でした。手元にあったスパンをクエリすれば、それだけでわかることだったのです。
個別ビジネスイベントには構造化ログ。 構造化ログは個別のイベントを、何が起きたか・なぜ起きたかをデバッグできる十分な詳細とともに記録します。ユーザーがプランをアップグレードしたとき、変更前後の出来事・トリガー箇所・収益への影響を残しておきたいとします。記録する価値のあるビジネスイベントですが、エンドツーエンドでトレースするほどパフォーマンスクリティカルな処理でもありません。ログで十分です。
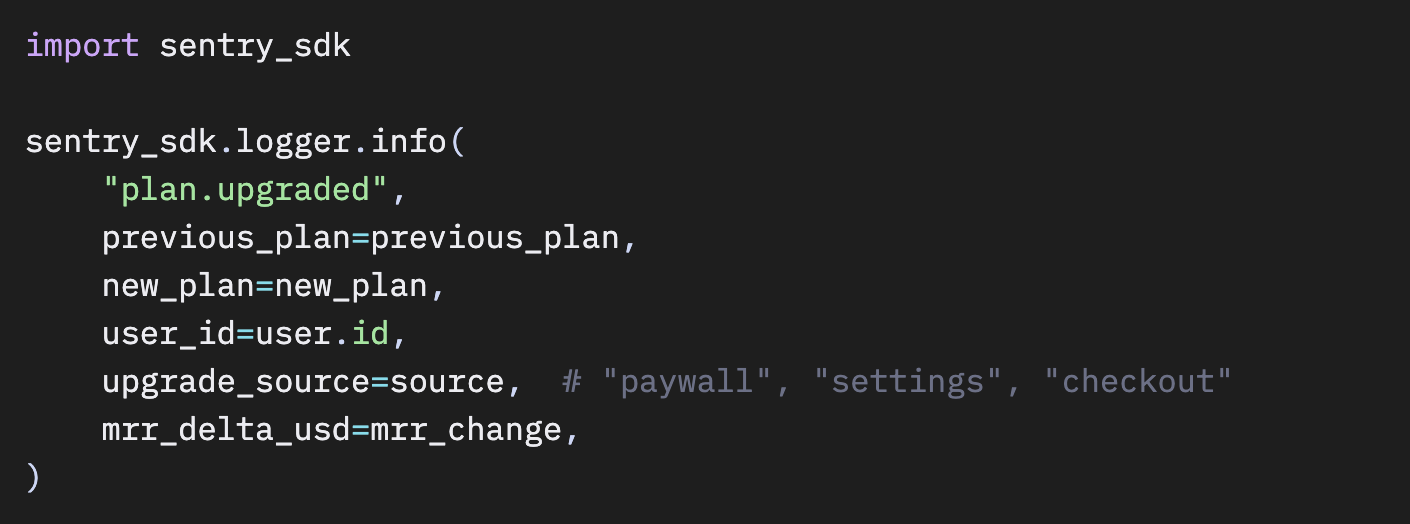
これで、流入元別のアップグレード数をクエリしたり、最も収益をもたらしているアップグレード経路を確認したりできます。アップグレードフローで何か壊れた場合も、そのログエントリはすでに、失敗箇所を示すトレースコンテキストと紐づいています。
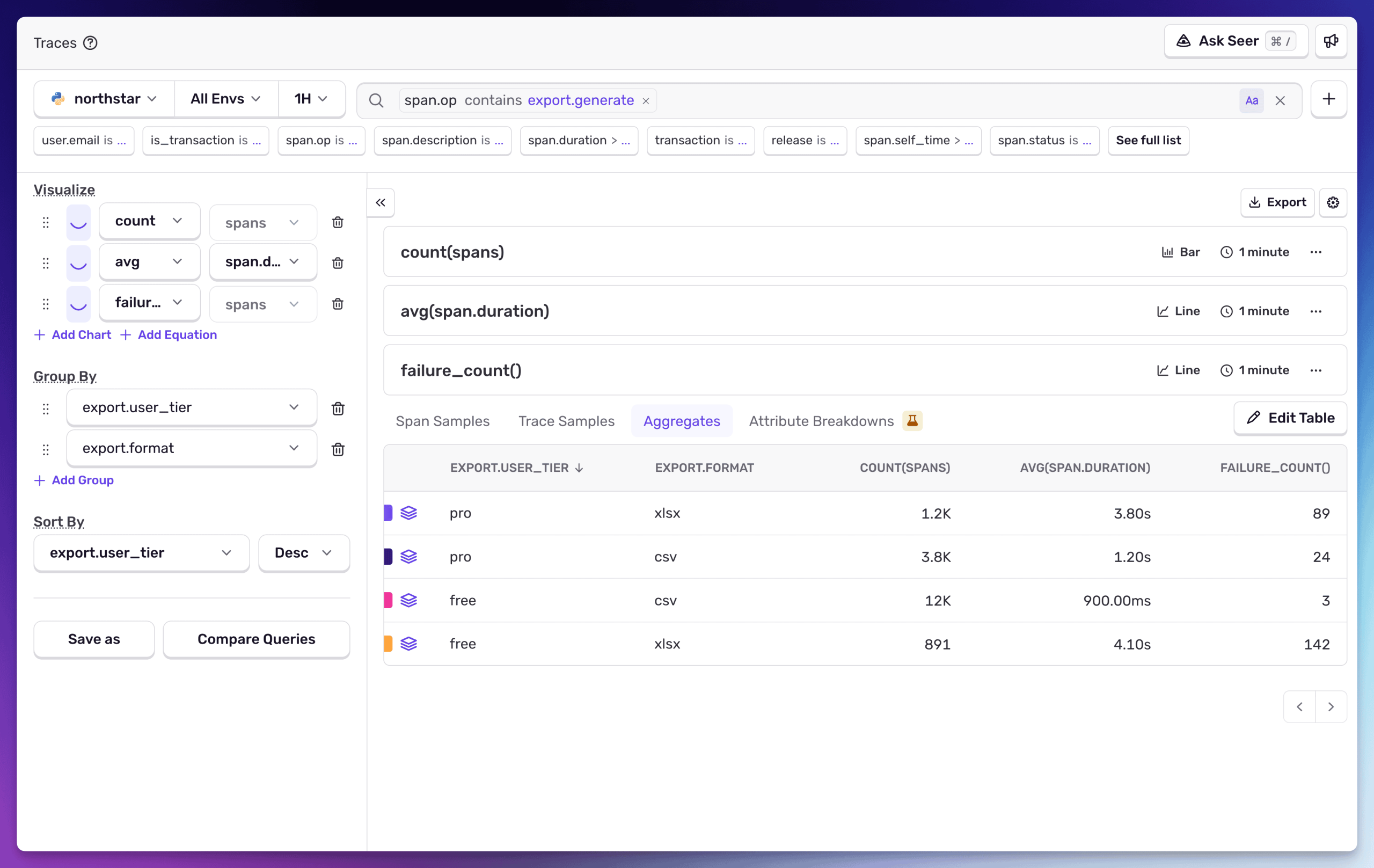
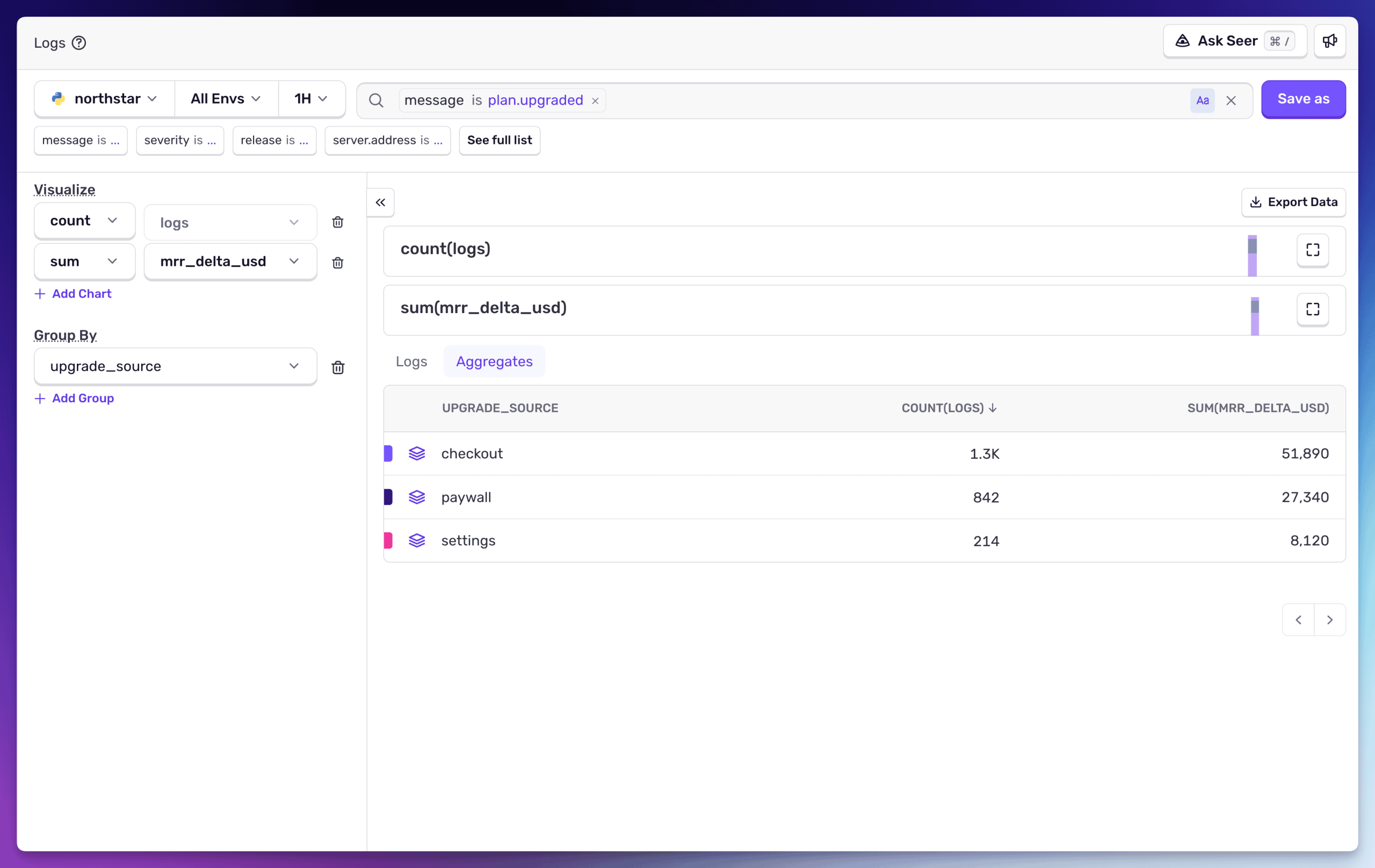
過去30日間のアップグレードイベントをクエリしてみましょう。

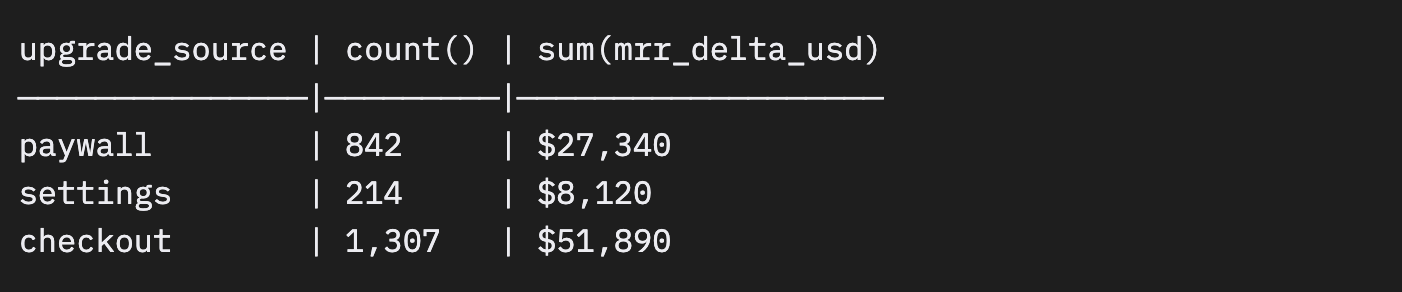
チェックアウトからのアップグレードが最も多く、1件あたりの平均 MRR も高い($39.69 対 paywall の $32.47)。PM が別ツールを使って掘り出しに行くようなインサイトが、ログの中に眠っていたのです。
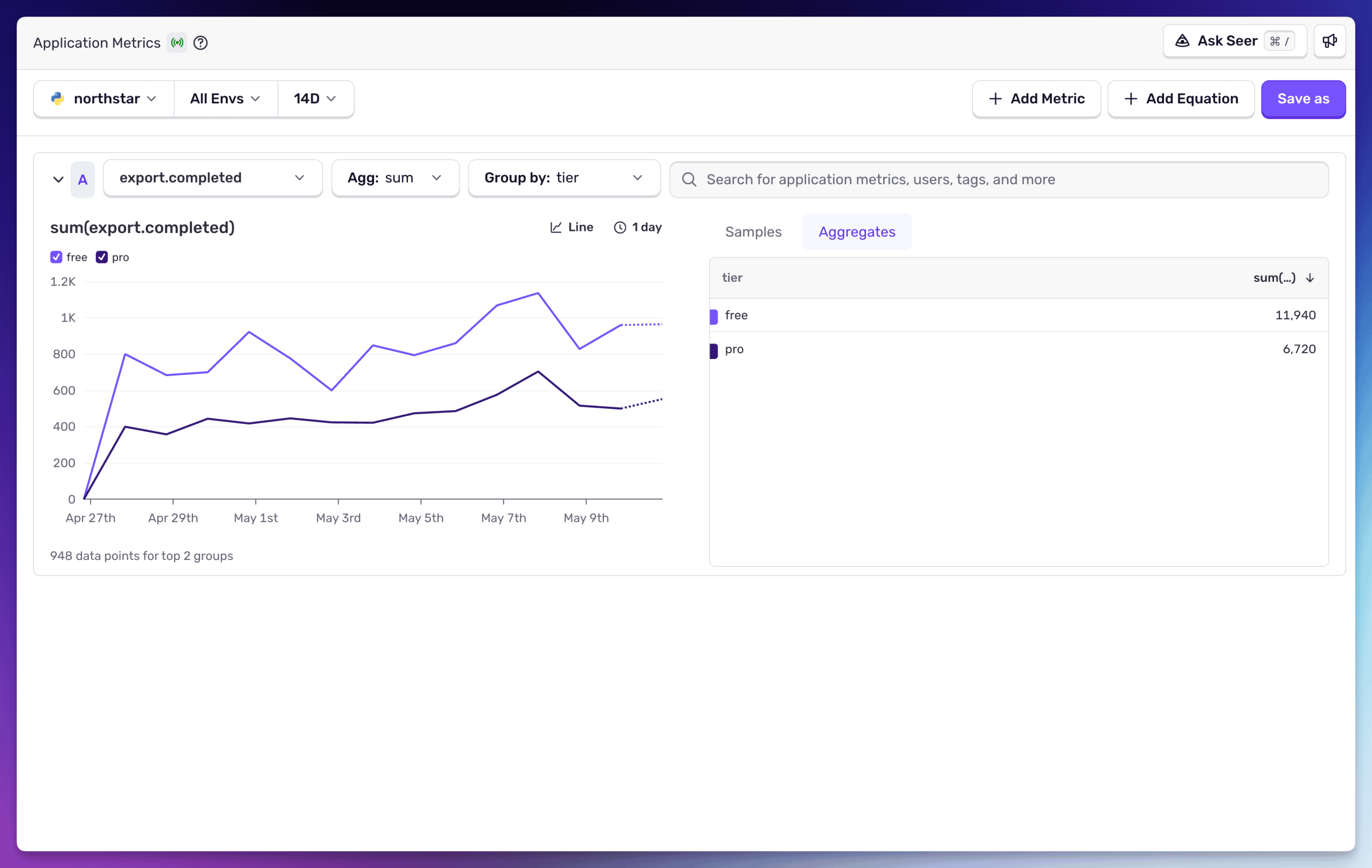
KPI とヘルスシグナルには Application Metrics。 メトリクスは、サービスとビジネスの健全性を示す指標を継続的に追跡するための手段です。チェックアウトのコンバージョン率、時系列でのサインアップ数やトラフィック、エラーバジェットの消費状況など。常時追跡し、アラートを設定し、トレンドを観察すべきシグナルです。

アナリティクスパイプラインを構築・維持することなく、アラート設定・可視化・トレンド観察に使えるカウンターとディストリビューションが得られます。
1つの SDK で、必要なあらゆる角度をカバーする3つの基本要素がそろいます。スパンによるリクエストレベルの詳細、構造化ログによるビジネスイベントの個別記録、メトリクスによる集計トレンド。すべて1つのツールでクエリ可能で、互いに連携しています。
よくあるワークフローと比べてみましょう。誰かがアナリティクスツールに feature_export_used イベントをインストルメントし、ダッシュボードを作り、週次でチェックします。3週間後、採用率が横ばいなことに気づきます。エンジニアに問題がないか確認します。エンジニアが Sentry を見ると、50MB 超のファイルでエクスポートがタイムアウトしていることがわかります。実際の多くのユースケースをカバーするサイズです。アナリティクスツールには症状は見えても原因は見えなかったために、3週間が失われたのです。
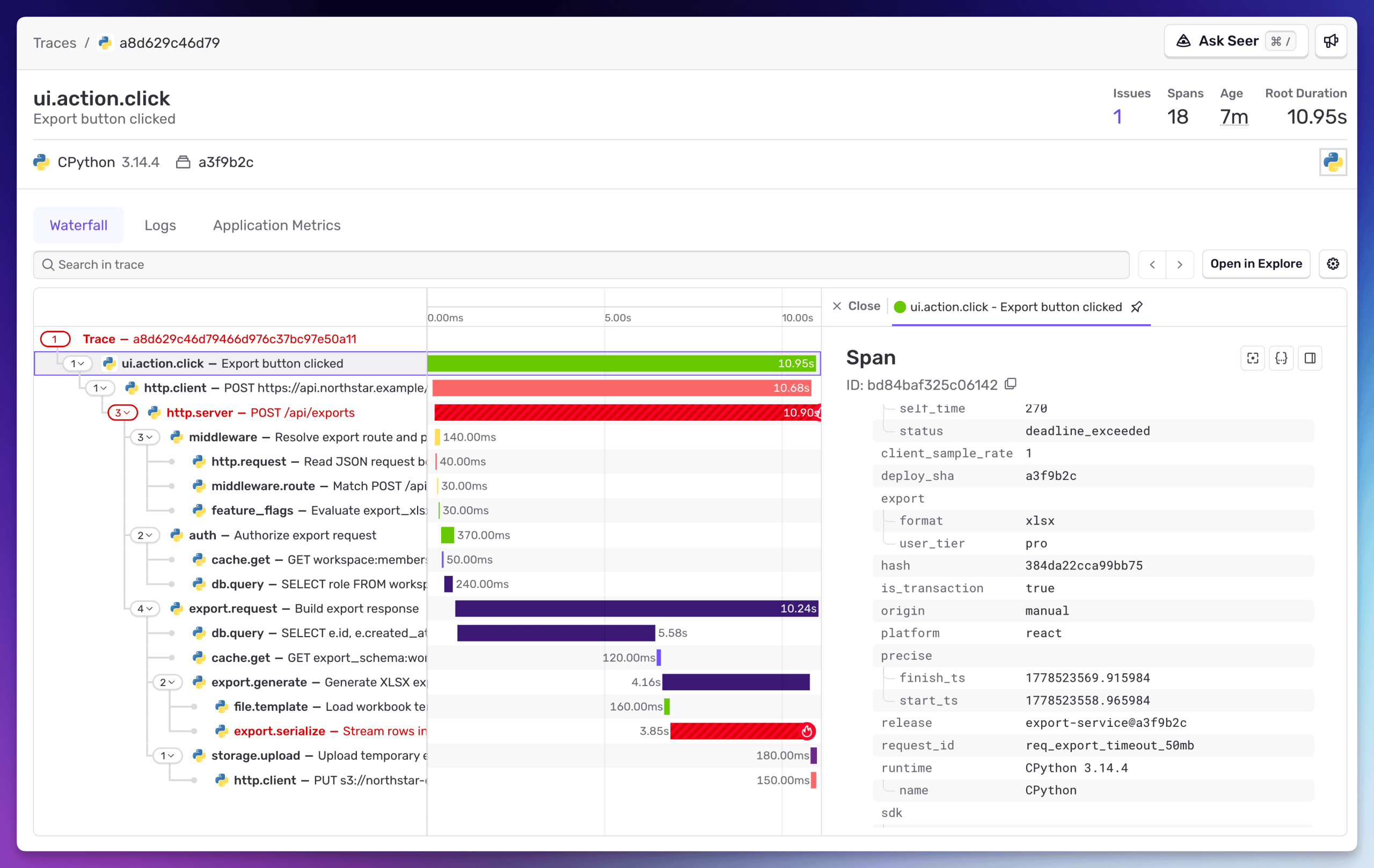
テレメトリを使えば、そのスパンのエラーレートと所要時間にモニターを設定できます。タイムアウトが発生し始めたとき、アラートは週単位でしか反映されないダウンストリームのアナリティクスメトリクスではなく、スパン自体に対して発動します。メトリクスはカウントの減少を示し、スパンは所要時間のスパイクを示し、構造化ログはエラーを示す。3つすべてが、同じトレース・同じリリース・同じコードの行を指し示しています。
さらに一歩進めたいなら、採用率が横ばいになっている原因として何か壊れているものがないかを Seer に尋ねることもできます。
知識と経験はそのまま使える
すでに Sentry をデバッグに使っているなら、変えるべき考え方はひとつだけです。「ビジネスのテレメトリ」と「システムのテレメトリ」は、別のカテゴリではないということ。
ビジネス上の問い(「ユーザーはコンバートしたか?」)とエンジニアリング上の問い(「リクエストは成功したか?」)は、同じ問いを異なる視座から見ているだけです。ビジネス上の問いに別ツールは要りません。すでにあるスパン に purchase.value_usd を追加し、必要な属性とともに purchase.completed イベントをログに残し、カウンターを増やすだけです。
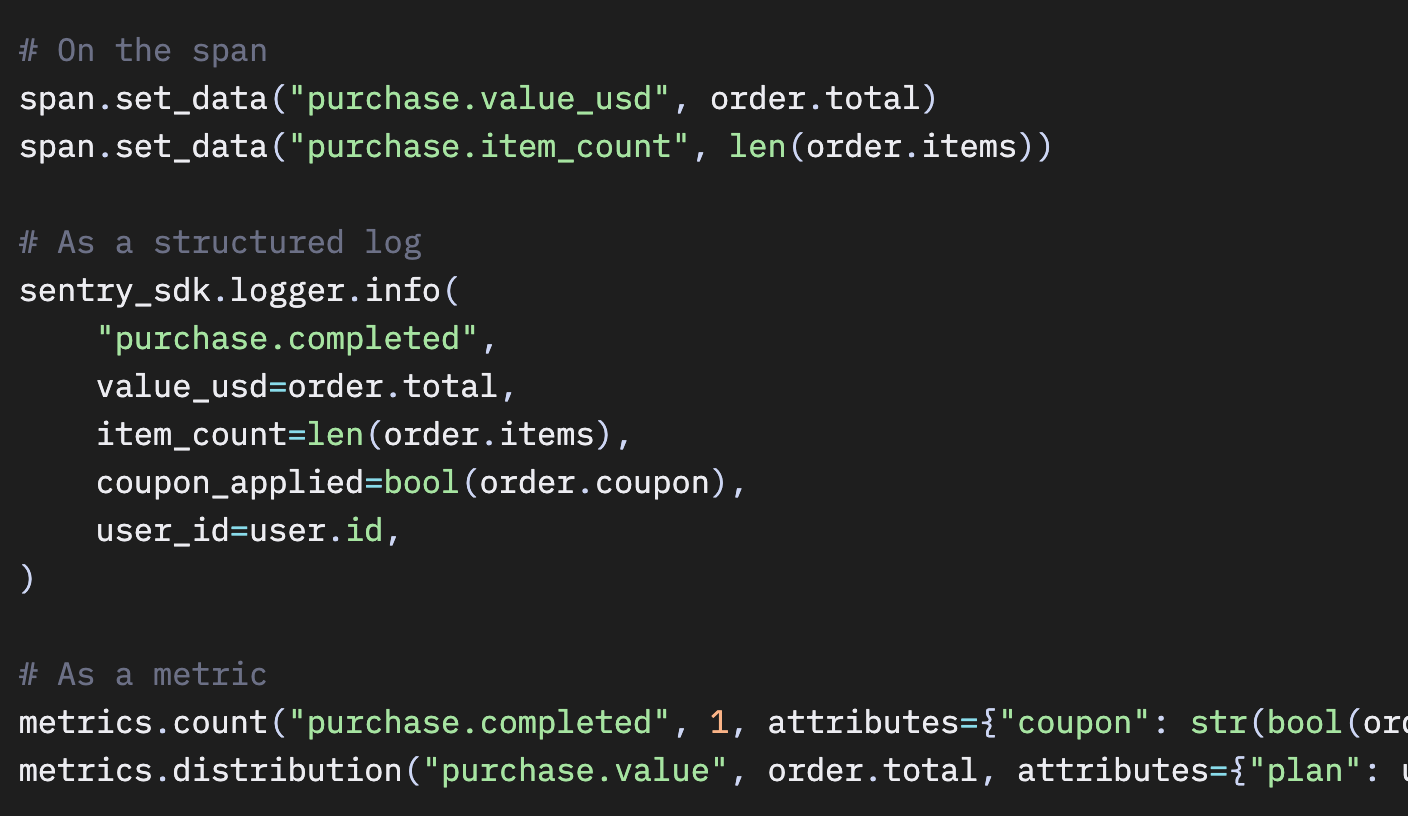
あるクライアントの言葉が的を射ていました。「ビジネスメトリクスに差異が生じたとき、それはシステムの他の部分にも現れる。それがオブザーバビリティの意味だ。すべては繋がっている」と。テレメトリをプロダクトの問いに答える唯一の情報源として使い始めた瞬間、別のシステムは不要になります。
難しい部分と、それが解消されつつある理由
ギャップについて正直に話しましょう。
複数セッションにまたがるリテンション分析、行動パターンによるユーザーグループ(コホート)分析(「14日以内に X はしたが Y はしなかったユーザー」)、セッションをまたいだファネルのコンバージョン分析は、生のテレメトリから再構成するのが難しい領域です。スパンはリクエストスコープ、構造化ログはイベントスコープ、メトリクスは時系列です。ユーザーのジャーニーをセッションと日をまたいで繋ぎ合わせるには、これまでのオブザーバビリティツールが構築してきたものとは異なる集計インフラが必要になります。
獲得チャネル別に分けた30日間のリテンション曲線が必要な場合、今日の時点では単純な GROUP BY では辿り着けません。
ただ、データのほとんどはすでにそこにあります。スパン、構造化ログ、メトリクスはいずれもユーザー ID・タイムスタンプ・ビジネス属性を持っています。不足しているのは集計・可視化レイヤーであり、データモデルの問題ではありません。OpenTelemetry によってこの課題は四半期ごとに改善されています。インストルメンテーションが標準化されれば、集計レイヤーはコモディティ化されるからです。ギャップは確かに存在しますが、縮まり続けています。
この領域には取り組む価値があると考えており、今後の記事では、クロスセッション分析においても Sentry の既存クエリツールでどこまで到達できるか、より難しいユースケースを深掘りしていく予定です。
機能を作って出荷する開発者として日々重要になる問いに対しては、そのギャップはありません。自分の機能は採用されているか?パフォーマンスは問題ないか?エラーは出ていないか?有料ユーザーと無料ユーザーの挙動に違いはあるか?最も収益をもたらしているアップグレード経路はどこか?これらはすべて、誰かを待たずに、今すぐ手元のテレメトリから答えられます。
試してみよう
最近リリースした機能の中から、気になるものを一つ選んでみてください。次のことを試す機会が必ずあるはずです。
- その機能のクリティカルパス上にあるスパンに、ビジネスレベルの属性を追加する
- クエリに使いたい詳細情報(ユーザープラン、画面の種類、アクティビティデータ)を含む、高カーディナリティなワイドイベントとして Sentry Logs を追加する
- ダッシュボード作成に役立つ属性を付けたアプリケーションメトリクスを随所に散りばめる
このような作業は AI エージェントが得意としています。ローカルの IDE にデプロイできるスキルも用意しています。作業が終わったら、ダッシュボード・モニター・アラートを最適に作成する方法について Seer Agent に相談してみてください。
その機能のアナリティクスダッシュボードを、誰も最初に開かなくなる日が来るまでどれくらいかかるか、試してみてください。データはすでにある。ツールもすでにある。自分で立てるべき問いを、ずっと他の誰かに委ねてきただけです。
Original Page: The product analytics you already have
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。